Catalog:Click to jump to the corresponding position
目录:
=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=
NumPy(Numerical Pythaon)是Python语言中做科学计算的基础库,重在于数值计算,也是大部分Python科学计算库的基础
Numpy模块多用于在大型、多维数组上执行的数值运算。
1.使用np.array()创建
-使用array()创建一个一维数组:
import numpy as np
arr = np.array([1,3,5,7,9])
arr
输出结果:
array([1, 3, 5, 7, 9])
-使用array()创建一个多维数组:
![]()
数组的维数:可以理解为嵌套的层级,比如一个列表对象中嵌套了一个列表,那么在数组下就是二维数组,列表对象如果没有嵌套,就是一维数组
2.使用plt创建
可以将外部的一张图片加载到Numpy数组中,然后可以进行裁剪、旋转等操作
import numpy as np
import matplotlib.pyplot as plt
img_arr = plt.imread('F:datayoona.jpg') #返回的是数组,数组中装载的是图片内容
plt.imshow(img_arr) #将numpy数组进行可视化展示

3.使用np的函数创建

import numpy as np
arr_1 = np.zeros(shape=(4,3))
arr_2 = np.ones(shape=(4,3))
arr_3 = np.linspace(0,10,num=5)
arr_4 = np.arange(10,20,step=2)
arr_5 = np.random.randint(0,50,size=(4,3))
print(arr_1,'
',arr_2,'
',arr_3,'
',arr_4,'
',arr_5)
输出结果:

-数组中存储的数据元素类型必须是统一的类型
-数组中的元素类型有优先级:字符串>浮点数>整数
import numpy as np
arr_case=np.array([1,2,'three'])
arr_case.dtype
输出结果:dtype('<U11')
shape、ndim、size、dtype
import numpy as np
arr_case=np.random.randint(10,100,size=(5,4))
arr_case

arr_case.shape #返回数组的形状
arr_case.ndim #返回数组的维度
arr_case.size #返回数组元素的个数
arr_case.dtype #返回数组的类型
输出结果:
(5,4)
2
20
dtype('int32')
-array(dtype=x):可以设定数据类型
-arr.dtype = 'x':可以修改数据类型
-astype可以显式地转换数组的类型
import numpy as np
arr_case=np.random.randint(10,100,size=(5,4),dtype='int32')
arr_case.dtype #输出结果:dtype('int32')
arr_case.dtype='int64'
arr_case.dtype
输出结果:dtype('int64')
import numpy as np
arr_case=np.random.randint(10,100,size=(5,4),dtype='int32')
arr = arr_case.astype(np.int64)
arr.dtype
输出结果:dtype('int64')
import numpy as np
arr = np.random.randint(10,100,size=(5,4),dtype='int32')
arr

arr[0] #取数组的第一行数据,数组的索引从0开始
输出结果:array([95, 61, 13, 78])
arr[0:2] #取数组的第一行到第二行数据
输出结果:

arr[[0,2]] #取数组的第一行和第三行数据,注意是两个列表框
输出结果:
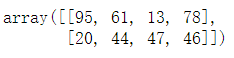
arr[0,0] #取数组的第一行,第一列的数据
输出结果:95
arr[0,[1,2]] #取数组的第一行,第二列和第三列的数据
输出结果:array([61, 13])
arr[:,[1,2]] #取数组的二列和第三列的数据
输出结果:

arr[:,0:3] #取数组的一列到第三列的数据
输出结果:

arr[0:2,0:2] #取数组的前两行前两列的数据
输出结果:

arr[::-1] #取数组的行顺序进行倒转
输出结果:

arr[:,::-1] #取数组的列顺序进行倒转
输出结果:

arr[[1,2],[1,2]] #相当于arr[1,1]、arr[2,2]
输出结果:array([37, 47])
arr[[1,2]][:,[1,2]] #先取出第二行和第三行,在取出来的基础再上取第二列和第三列
输出结果:

import numpy as np
import matplotlib.pyplot as plt
img_arr = plt.imread('F:datayoona.jpg')
img_arr.ndim
输出结果:3
输出结果为3表示图片的数组维度有三个
img_arr.shape
输出结果:(1498, 1200, 3)
1498和1200表示像素的维度
3表示颜色的维度
-reshape是返回一个新的数组对象,并不会改变原数组的内容
-resize也可以改变数组的形状,只不过resize会直接将原数组进行改变
-ravel将数组按照一定的方式降为一维数组,并不会改变原数组的内容
import numpy as np
arr = np.random.randint(1,50,size=(5,3))
arr
输出结果:

arr_1 = arr.reshape(15,) #将二维数组降为一维
arr_1
输出结果:array([28, 16, 23, 34, 16, 25, 1, 32, 42, 25, 15, 17, 45, 18, 24])
arr_2 = arr.reshape(3,5) #将 5行3列 改为 3行5列
arr_2
输出结果:
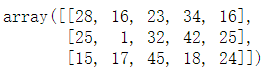
arr_3 = arr.reshape(3,-1) #行或列只要有同一个数字确定,python会自动计算-1位置上的数字,前提是那个确定的数字能被原数组中的元素个数整除
arr_3 #原数组5行3列一共15个元素,15可以整出3
输出结果:

arr_4 = arr.ravel() #将原数组按照行的方向降为一维数组,不会改变原数组的形状
arr_4
输出结果:array([28, 16, 23, 34, 16, 25, 1, 32, 42, 25, 15, 17, 45, 18, 24])
arr_5 = arr.ravel(order='F') #将原数组按照列的方向降为一维数组,不会改变原数组的形状
arr_5
输出结果:array([28, 34, 1, 25, 45, 16, 16, 32, 15, 18, 23, 25, 42, 17, 24])
arr.resize(3,5) #resize也可以改变数组的形状,只不过resize会直接将原数组进行改变
arr
输出结果:

八、排序函数、np.inld函数、unique去重函数、np.where函数
排序函数: sort函数、argsort函数都可以进行排序,不过argsort返回的是从小到大的索引值
8.1 sort()函数
import numpy as np
arr = np.random.randint(1,50,size=(5,3))
arr
输出结果:

arr.sort() #直接改变的是原数组,如果是多维数组,那么默认axis=1
arr
输出结果:

import numpy as np
arr = np.random.randint(1,50,size=(5,3))
arr

arr.sort(0) #直接改变的是原数组,按照数组中的列排序
arr

arr.sort()都是从小到大进行排序的,如果想让从大到小进行排序,可以在排序之后使用切片操作达到目的
注意 arr.sort() 对应的是 arr[ : , : : -1 ]、arr.sort(0)对应的是arr[ : : -1 ]
arr[::-1] #在arr.sort()执行之后进行切片操作

8.2 argsort()函数
argsort返回的是从小到大的索引值,索引值从0开始
import numpy as np
arr = np.random.randint(1,50,size=(5,3))
arr

arr.argsort(0) #返回新的数组对象,不改变原数组,0表示按照列的方向
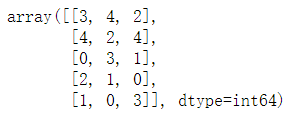
8.3np.in1d()函数
注意是in“一”d,你是in“L”d
import numpy as np
arr = np.random.randint(1,50,size=(5,3))
list_case=[12,5,4,8]
arr
返回结果:

np.in1d(arr,list_case) #判断arr里的元素是否在list_case中,返回一个布尔值的数组
返回结果:array([False, False, False, False, False, False, False, True, False, False, False, True, True, True, False])
发现返回的结果是一个一维数组,不方便于我i们查看,我们此时可以将一维数组转化为与arr相同形状的数组
np.in1d(arr,list_case).reshape(5,3)
输出结果:

这样就方便我们与arr数组对照了
8.4unique()去重函数
import numpy as np
arr_1 = np.array([[1,3,4,5,7,9],[2,4,5,7,9,7],[1,3,4,5,8,9]])
arr_1
输出结果:

np.unique(arr_1) #计算arr_1的唯一值并排序
输出结果:array([1, 2, 3, 4, 5, 7, 8, 9])
8.5np.where函数
numpy.where() 有两种用法:
1. np.where(condition, x, y)
满足条件condition,输出x,不满足输出y
import pandas as pd
import numpy as np
arr = np.array(np.random.randint(1,20,size=(5,6)))
arr
输出结果:

np.where(arr[0:3]>15,'大于','小于') #arr的前三行的数据如果大于15,返回大于,否则返回小于
输出结果:
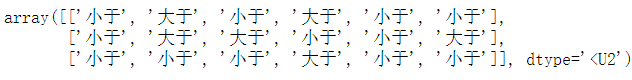
2. np.where(condition)
只有条件 (condition),没有x和y,则输出满足条件元素的索引 (等价于numpy.nonzero)
这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
import pandas as pd
import numpy as np
arr = np.array(np.random.randint(1,20,size=(5,6)))
arr
输出结果:
np.where(arr>15) #结果的第一行表示行索引,第二行表示列索引
输出结果:
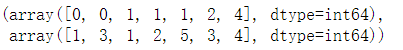
9.1常用数学函数:
sin()、cos()、tan() 和 around()
np.add(a,b)求和
np.divide(a,b)除法
np.subtract(a,b)减法
np.multiply(a,b)乘法
np.power(a,b)求幂
import numpy as np
np.sin(0.5)
输出结果:0.479425538604203
import numpy as np
arr = np.random.randint(1,50,size=(5,3))
np.sin(arr) #对arr数组中的每一个元素求sin值
输出结果:

9.2常用聚合函数:
sum、max、min、mean平均值、cusum累计求和、argmin最小值的索引、argmax最大值的索引
import numpy as np
arr = np.random.randint(1,50,size=(5,3))
arr
输出结果:

np.sum(arr) #将arr数组中的所有元素相加求和
输出结果:379
np.sum(arr,axis=0) #将arr数组中的每一列的元素相加求和,axis=1表示每一行
输出结果:array([ 65, 157, 157])
np.argmin(arr,axis=0) #返回数组中每一列元素最小值的索引
输出结果:array([2, 1, 0], dtype=int64)
9.3常用统计函数:
-numpy.ptp()计算数组中元素最大值与最小值的差(最大值 - 最小值)
-numpy.median()计算数组中元素的中位数(中值)
-numpy.std()计算数组中元素的标准差
-numpy.var()计算数组中元素的方差
import numpy as np
arr = np.random.randint(1,50,size=(5,3))
arr
输出结果:

np.std(arr) #求所有元素的标准差
输出结果:16.441681449562537
np.std(arr,axis=0) #求数组中每一列元素的标准差
输出结果:array([10.17840852, 13.5735036 , 17.24644891])
关于标准差:
标准差是一组数据平均值分散程度的一种度量
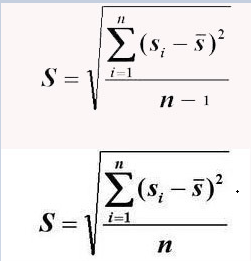
上式为样本标准差,下式为总体标准差,二式差一个自由度,n与n-1。
一个班级学生身高的标准差,50个学生有50个身高数据,如求这个班级学生身高的标准差那么用总体标准差
如这50个身高数据作为全校学生的抽样,那么用样本标准差,因为这50个身高数据是全校学生的样本

在numpy中调用字符串的方法,需要加char关键字,例如:np.char.upper()
import numpy as np
list_1=['hello','world']
list_2=['studay','running']
代码示例:
np.char.add(list_1,list_2)
输出结果:array(['hellostuday', 'worldrunning'], dtype='<U12')
np.char.multiply(list_1,2)
输出结果:array(['hellohello', 'worldworld'], dtype='<U10')
np.char.center('studay',12,'*')
输出结果:array('***studay***', dtype='<U12')
np.char.split('studay','u')
输出结果:array(list(['st', 'day']), dtype=object)
使用np.delete(data,删除的行或列的索引,axis)函数
索引从0开始、axis=1表示列,axis=0表示行
numpy数组数据源:
df1_value
输出结果:
#删除第一列,返回一个新的视图,不会改变元数据的值 np.delete(df1_value,0,axis=1)
输出结果:

#删除多行,返回一个新的视图,不会改变元数据的值 np.delete(df1_value,[0,2,4],axis=0)
输出结果:

将多个numpy数组进行横向或纵向的连接
np.concatenate((数组1,数组2,……),axis=0/1)
axis参数的理解:0表示列、1表示行
两个数组横向连接时,行数必须相同,列数可以不同
两个数组纵向连接时,列数必须相同,行数可以不同
import numpy as np
arr_1 = np.random.randint(1,100,size=(5,3))
arr_2 = np.random.randint(1,100,size=(3,3))
arr_3 = np.random.randint(1,100,size=(1,3))

np.concatenate((arr_1,arr_2,arr_3),axis=0)

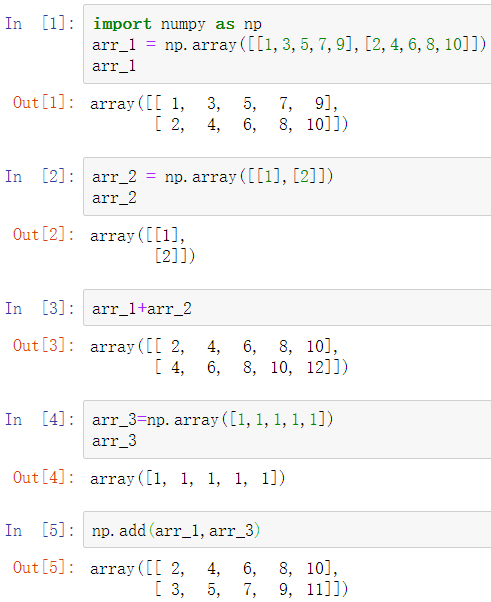
一维数组广播机制:
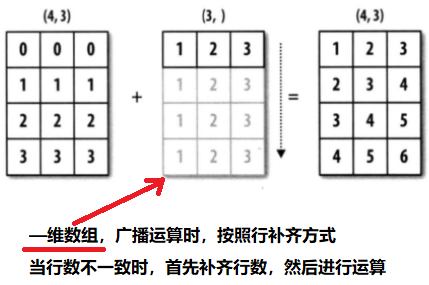
import numpy as np
arr_1 = np.array([[1,3,5,7,9],[2,4,6,8,10]])
arr_1
输出结果:

arr_2 = np.array([1,1,1,1,1])
arr_2
输出结果:array([1, 1, 1, 1, 1])
arr_1+arr_2 #使用np.add(arr_1,arr_2)也行
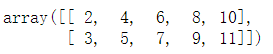
二维数组广播机制:
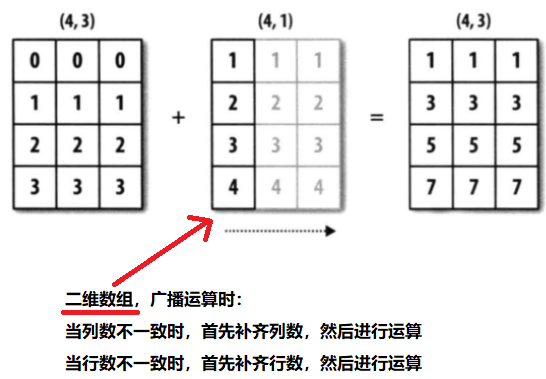
注意:二维数组再进行广播运算时,必须有一个维度相同,要么是行数相同,列数不同,要么就是列数相同,行数相同,不能行数不同,列数也不同
numpy.eye(x) 函数返回给定大小的单位矩阵
import numpy as np
arr_1 = np.eye(5)
arr_1

arr_1.T #矩阵的转置,行变成列,列变成行
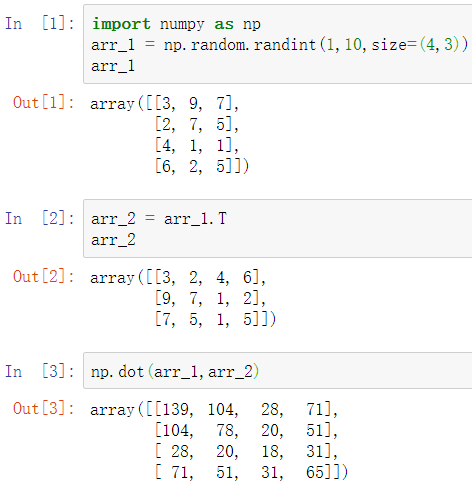
矩阵相乘:
numpy.dot(a, b, out=None)
a 、 b 为两个数组
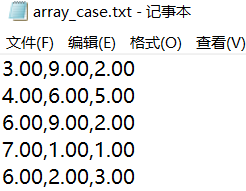
可以使用genfromtxt读取txt或者csv文件、也可以使用loadtxt读取txt或者csv文件
两个函数功能类似,genfromtxt针对的更多是结构化数据
array.txt源文件数据展示:
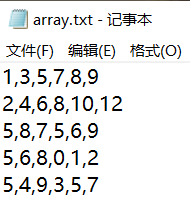
-genfromtxt
import numpy as np
data_1 = np.genfromtxt(r'F:dataarray.txt',delimiter=',',skip_header=1)
data_1
delimiter=',' 表示使用“,”将数据进行分隔
skip_header=1 表示不读取第一行
输出结果:

-loadtxt
data_2 = np.loadtxt(r'F:dataarray.txt',delimiter=',',skiprows=1)
data_2
delimiter=',' 表示使用“,”将数据进行分隔
skiprows=1 表示不读取第一行

-文件的保存
使用np.savetxt()函数
np.savetxt(保存地址,要保存的数据源,delimiter=分隔符,fmt=存储格式)
import numpy as npi
data_case = np.random.randint(1,10,size=(5,3))
data_case
输出结果:

np.savetxt(r'F:dataarray_case.txt',data_case,delimiter=',',fmt='%.2f')
输出结果: