withScope是最近的发现版中新增加的一个模块,它是用来做DAG可视化的(DAG visualization on SparkUI)
以前的sparkUI中只有stage的执行情况,也就是说我们不可以看到上个RDD到下个RDD的具体信息。于是为了在
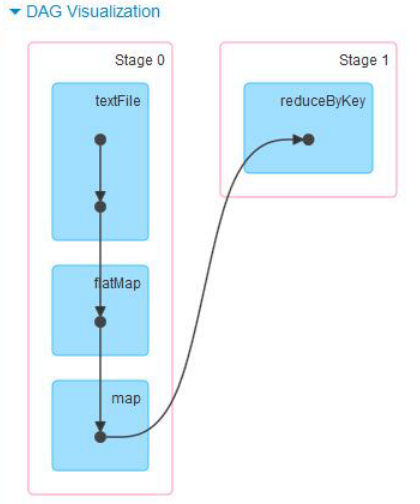
sparkUI中能展示更多的信息。所以把所有创建的RDD的方法都包裹起来,同时用RDDOperationScope 记录 RDD 的操作历史和关联,就能达成目标。下面就是一张WordCount的DAG visualization on SparkUI
在通过看RDD源码理解各算子的作用时, 总能看到withScope, withScope到底是个什么东西?
首先需要了解几个东西: scala柯里化(currying), 贷出模式(loan pattern)
scala柯里化(currying)
在scala中, 一个经过柯里化的函数在应用时支持多个参数列表,而不是只有一个。当第一次调用只传入第一个参数时,返回一个用于第二次调用的函数值。
scala> def curriedSum(x: Int)(y: Int) = x + y
curriedSum: (x: Int)(y: Int)
scala> curriedSum(1)(2)
res1: Int = 3
scala> val add3 = curriedSum(3)_
add3: Int => Int = <function1>
scala> add3(4)
res2: Int = 7
curriedSum(3)_中_是占位符, 表示第二个参数先不传, 返回值是一个函数值。
我们看RDD源码
/**
* Execute a block of code in a scope such that all new RDDs created in this body will
* be part of the same scope. For more detail, see {{org.apache.spark.rdd.RDDOperationScope}}.
*
* Note: Return statements are NOT allowed in the given body.
*/
private[spark] def withScope[U](body: => U): U = RDDOperationScope.withScope[U](sc)(body) // 这里用了柯里化
贷出模式(loan pattern)
把公共部分(函数体)抽出来封装成方法, 把非公共部分通过函数值传进来
/**
* Execute the given body such that all RDDs created in this body will have the same scope.
*
* If nesting is allowed, any subsequent calls to this method in the given body will instantiate
* child scopes that are nested within our scope. Otherwise, these calls will take no effect.
*
* Additionally, the caller of this method may optionally ignore the configurations and scopes
* set by the higher level caller. In this case, this method will ignore the parent caller's
* intention to disallow nesting, and the new scope instantiated will not have a parent. This
* is useful for scoping physical operations in Spark SQL, for instance.
*
* Note: Return statements are NOT allowed in body.
*/
private[spark] def withScope[T](
sc: SparkContext,
name: String,
allowNesting: Boolean,
ignoreParent: Boolean)(body: => T): T = {
// Save the old scope to restore it later
val scopeKey = SparkContext.RDD_SCOPE_KEY
val noOverrideKey = SparkContext.RDD_SCOPE_NO_OVERRIDE_KEY
val oldScopeJson = sc.getLocalProperty(scopeKey)
val oldScope = Option(oldScopeJson).map(RDDOperationScope.fromJson)
val oldNoOverride = sc.getLocalProperty(noOverrideKey)
try {
if (ignoreParent) {
// Ignore all parent settings and scopes and start afresh with our own root scope
sc.setLocalProperty(scopeKey, new RDDOperationScope(name).toJson)
} else if (sc.getLocalProperty(noOverrideKey) == null) {
// Otherwise, set the scope only if the higher level caller allows us to do so
sc.setLocalProperty(scopeKey, new RDDOperationScope(name, oldScope).toJson)
}
// Optionally disallow the child body to override our scope
if (!allowNesting) {
sc.setLocalProperty(noOverrideKey, "true")
}
body // 非公共部分
} finally {
// Remember to restore any state that was modified before exiting
sc.setLocalProperty(scopeKey, oldScopeJson)
sc.setLocalProperty(noOverrideKey, oldNoOverride)
}
}
因为每个RDD算子方法,都有共同部分和共同参数, 所以这里用withScope封装了公共部分代码, 用柯里化把共同参数先传进去。
然后非公共部分代码,通过第二个参数传进去。这里body参数就是非公共部分函数值。
理解算子
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
这里就举一个例子, map方法
其实这里是相当于直接调用withScope方法, 后面花括号里面的是函数字面量, 是参数。
在scala中,当方法只有一个参数时, 后面可以用花括号代替圆括号。