Yarn(统一资源调度器,任务监控管理器)
- 整合hadoop集群中资源(cpu,内存等)进行统一调度
- 监控map和reduce的执行状况

ResourceManager(master,负责整合资源调度)
NodeManager(slave,负责计算)
关键配置
yarn-site.xml


1 <property> 2 <name>yarn.nodemanager.aux-services</name> 3 <value>mapreduce_shuffle</value> 4 </property> 5 <property> 6 <name>yarn.resourcemanager.hostname</name> 7 <value>hadoop</value> 8 </property>
mapred-site.xml(默认只有mapred-site.xml.template,将其复制一份为xml即可)
1 <property> 2 <name>mapreduce.framework.name</name> 3 <value>yarn</value> 4 </property>
注:start-yarn.sh 只能在resourcemanager节点上执行
一个job的五个阶段

- Mapreduce中可以没有reduce阶段,也可以有多个,一旦设置多个reduce task,结果会根据该数量放入不同文件中
- map task的数量由这个文件block决定
- 为了解决map的局部数据在传递给多个reduce处理过程中,为了保证每个reduce处理的额数据均衡,MR引入分区概念。分区的数量由reduce task数量决定。默认的分区机制:HashPartition分区。自定义分区:继承Partitioner<k,v>,k为map阶段输出的key,v为输出value
- 合并(Combiner):map阶段可能会有大量的局部计算结果要汇总到reduce阶段,如果不做一些处理直接传输到对应哪个reduce节点,会占用大量的网络带宽等资源,因此,可以在map阶段添加reduce先做合并,减小map局部数据大小,进一步提高MR效率。在MR机制中,Combiner默认是关闭的。
job counter
用来对map执行次数和reduce执行次数进行计数
MapReduce计算步骤
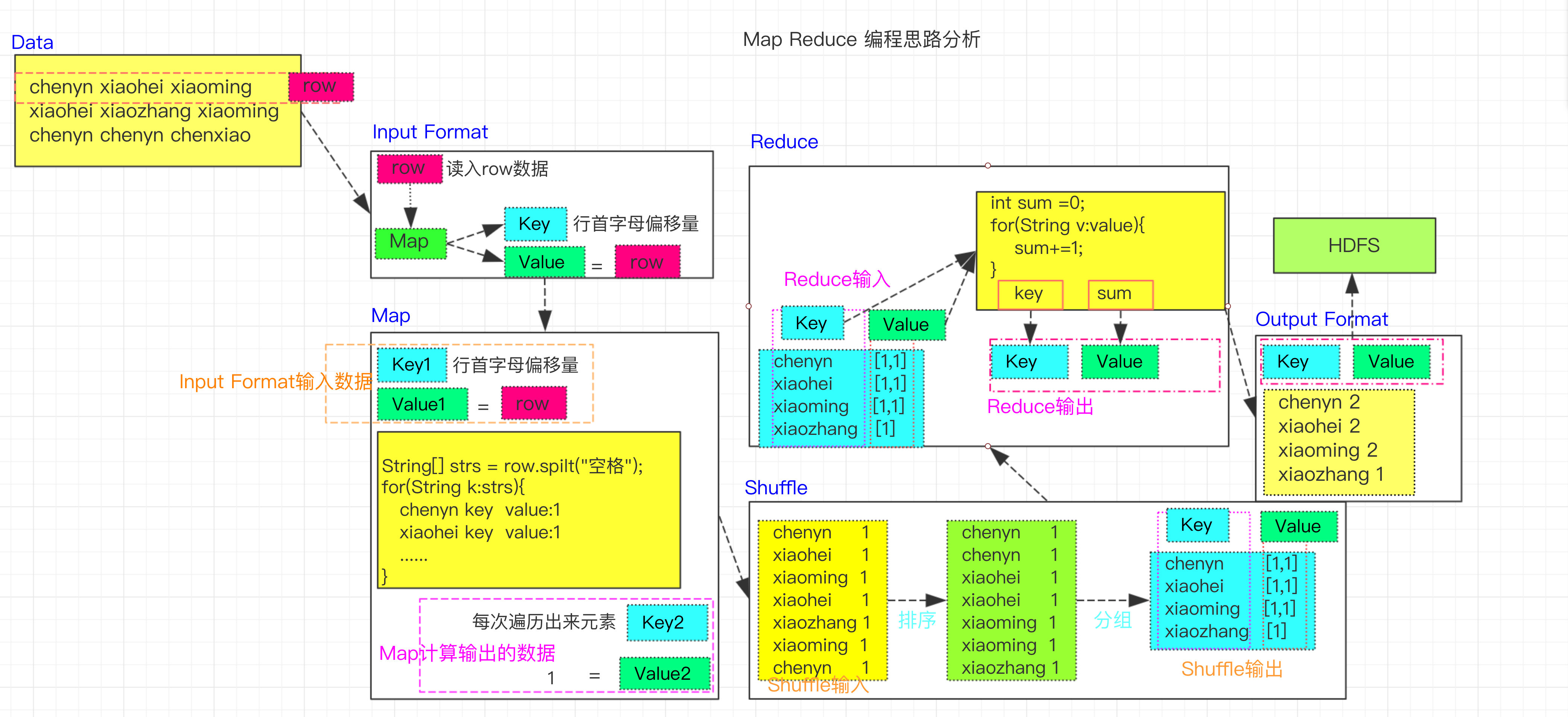
shuffle阶段只对Map阶段输出的key进行排序,对Map输出重复的key进行排序(去重)