前篇在此:
操作系统笔记(五) 虚拟内存,覆盖和交换技术
操作系统 笔记(三)计算机体系结构,地址空间、连续内存分配(四)非连续内存分配:分段,分页
内容不多,就不做index了。
功能:当缺页中断发生时,需要调入新的页面而内存已满时,需要选择哪个物理页面被置换?
目标:尽可能减少缺页中断(页面的换入换出)次数。在局部性原理下根据过去的数据统计预测。
页面锁定(frame locking):用于描述必须常驻内存的操作系统的关键部分,或时间关键的应用进程(time-critical)。需要在页表中添加锁定标志位(lock bit)
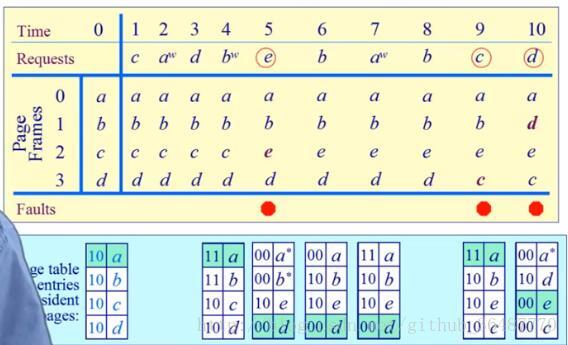
比较不同的页面置换算法:
设置一个实验环境,记录一个进程对页访问的轨迹。
虚拟地址跟踪(3,0) (1,9) (4,1)……
偏移可忽略,只用页号生成页面轨迹3,1,4 ……
模拟一个页面置换的行为并且记录产生缺页的数量,越少越好
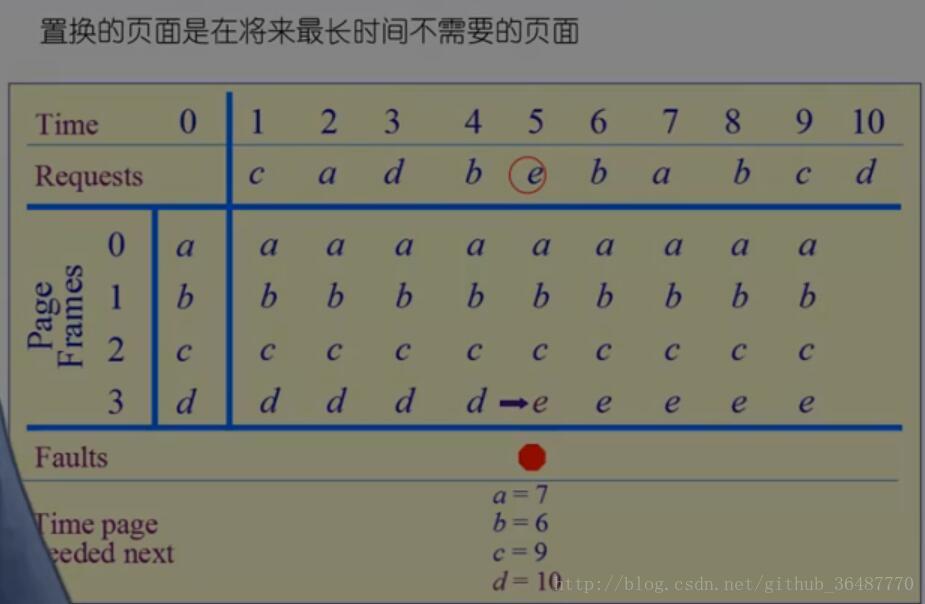
(1) 最优界面置换算法:
选择内存中等待时间最长的页作为置换页面。
只能是理想情况,OS不知道啊。
可以作为最佳的标准,在第二遍运行时利用第一次的访问轨迹使用最优算法。其他算法应尽量逼近。
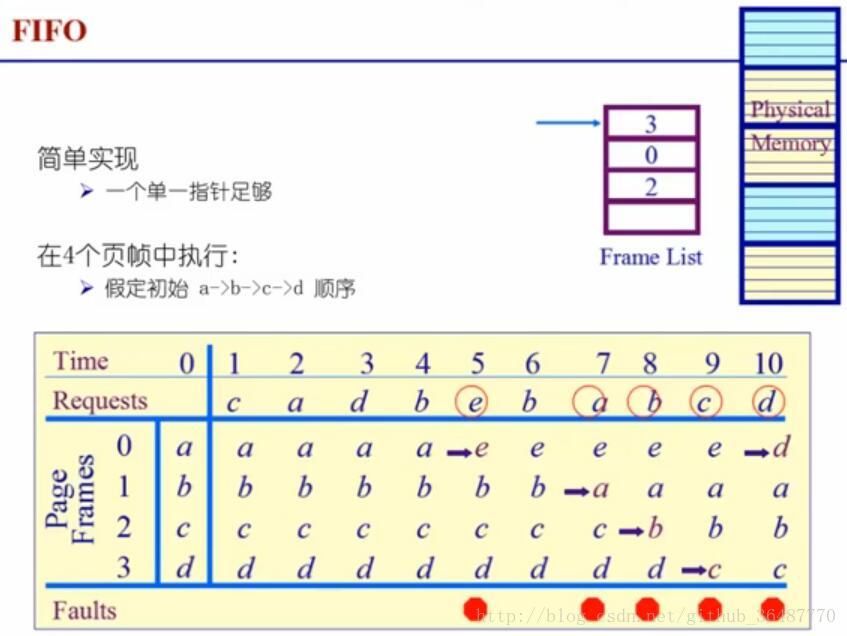
(2) 先进先出算法 first-in first-out FIFO
选择在内存中驻留时间最长的页面并淘汰之。OS维护着一个队列链表,淘汰首位,添加末位。
性能较差,调出的页面可能是常用页面(驻留时间长,本身就说明可能常用),有belady现象(给的物理页帧越多反而缺页越频繁)。
FIFO belady现象:分配的物理页数增加,缺页率反而提高,原因是FIFO忽视了进程访问的动态特征。多次访问的不要走。尤其是最坏情况发生时,易高缺页率。
Belady 是个人名,不要想多了。。。
很少单独使用
(3) 最近最久未使用算法least recently used LRU
选择最久未使用的那个页面淘汰掉。
是对最优置换算法的近似,以过去推未来。根据程序的局部性原理,如果最近一段时间内某些页面被频繁访问,那么在将来还可能被频繁访问。反之,未被访问的将来也不会被访问。
程序应具有较好的局部性。
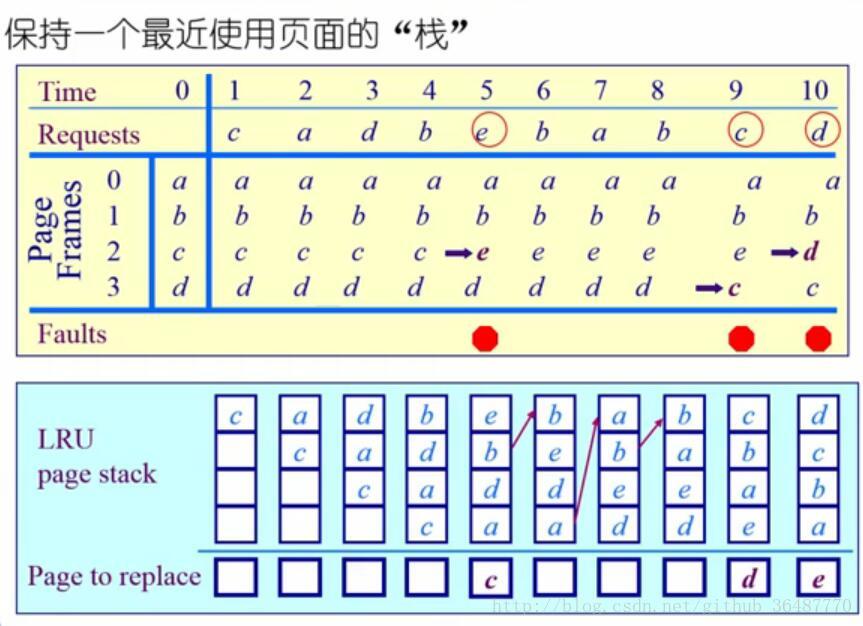
需要记录各个页面使用时间的先后顺序,开销大。
两种可能的实现方法:
系统维护一个页面链表,最近刚使用的页面最为首节点,最久未使用的页面作为尾节点,每次访问内存动态更新头结点。缺页中断时,淘汰末位的页面。
活动页面堆栈:访问某页时,将此页号入栈,并去除栈内的重复页。淘汰栈底的页面。(栈是先进后出,只有栈顶开口,怎么push栈底?)
动态更新(插,删,内部调整)堆栈和链表要开销,注意平衡—不是最有效
(4) 时钟页面置换算法 clock ——LRU的近似,FIFO的改进
用到页表项的访问位(access bit),当一个页面被装入内存时,把该位初始化为0,被访问(读/写)时,硬件把它置为1. 而OS会定期清0。(1—最近被访问,0—-未访问)
把各个页面组成环形链表类似一个clock,指针指向最老的页面。
当发生一个缺页中断时,考察指针所指的最老页面,访问位是0则淘汰,如果是1则置为0,然后指针向下移动一格。如此下去直到淘汰某页。
在内存中维持一个环形页面链表,更新并删除used bit=0的页面 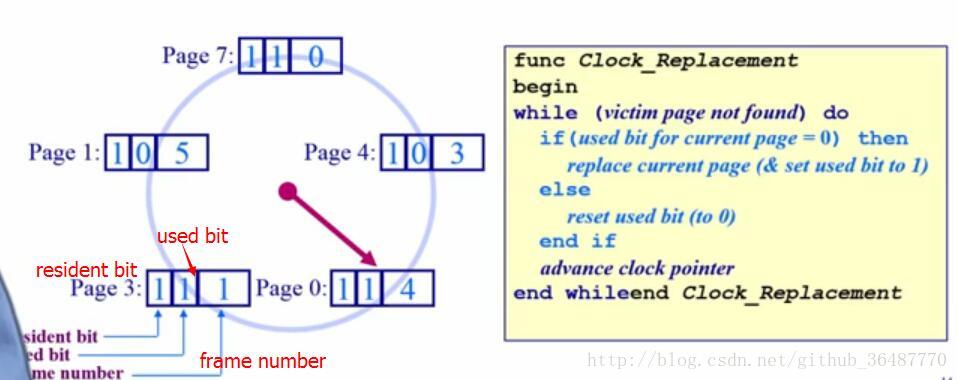
(5)二次机会法
区分读和写,enhanced clock algorithm
读和写都是访问,dirty bit是写位,如果写,为1,否则是0。同时使用脏位和使用位。
修改clock算法,使它允许脏页总是在一次时钟头扫描时保留下来,以减少写回硬盘的操作(仅读的页可以直接释放)
需要替换的页,其访问位和脏位都是0,如果都是 1,则有两次机会才被淘汰。从而让更多使用频率的页有更多的机会留在内存中。
较为接近LRU算法,尽量保存dirty page,更好地减少了访问外存
(6)最不常用算法(least frequently used)LFU
选择置换访问次数最少的那个页面
对每个页面设置访问计数器,每当一个页面被访问时,++。淘汰数值最小的那个。
硬盘计数器空间开销,排序查找时间开销;
LRU/LFU区别:LRU考察的是多久未访问,时间越短越值得留在内存,LFU是访问次数/频度,次数越多越好。
反例:一个页面在进程开始时使用的很多,但以后就不使用了。此时LFU就不适用了。
把时间也考虑进去,在一段时间内考察LFU。比如,定期把次数寄存器右移一位。
综合比较局部页替换算法
都是 针对一个程序 站在算法角度本身考虑
LRU和FIFO本质都是先进先出,但LRU是页面的最近访问时间而不是进入内存的时间,有动态调整,符合栈算法的特性,空间越大缺页越少。如果程序局部性,则LRU会很好。如果内存中所有页面都没有被访问过会退化为FIFO。
Clock 和enhanced clock也是类似于FIFO的算法,但用了硬件的BIT来模拟了访问时间和顺序,近似了LRU,综合起来较好,但也会退化为FIFO。
都对程序的访问次序有局部性的要求,不然都会退化。
开销上,LRU开销大,FIFO开销小但BELADY,折中的是clock算法,开销较小,对内存中还未被访问的页面,效果等同LRU。对曾经被访问过的则不能记住其准确位置。
全局置换算法
局部页替换算法的问题、工作集模型
分配的物理页帧的数目对置换算法的效果有很大的影响。
程序的运行具有阶段性,是动态变化的过程,开头结尾较多,中间较少,都分配固定的物理页帧则失去了灵活性。
工作集模型:
如果局部性原理不成立,那各种算法都没啥区别,比如是单调递增,那不管哪种都会缺页中断。
利用工作集模型来表征局部性。
工作集(working set):一个进程当前使用的逻辑页面集合
可以用一个二元函数W(t,Δ),t是当前执行时刻,Δ是工作集窗口 working-set window,一个定长的页面访问的时间窗口。t+Δ构成了一个时间段,W(t,Δ)就是在当前时刻t之前的Δ时间内所有访问页面组成的集合,在随t不断更新。| W(t,Δ)|是工作集的大小即页面数目。
进程开始后,随着访问新页面逐步建立较稳定的工作集,当内存访问的局部性区域的位置大致稳定时| W(t,Δ)|波动很小,在过渡阶段,则会快速扩张和收缩过渡到下一个稳定值。有波峰,有波谷。
常驻集:在当前时刻,进程实际驻留在内存当中的页面集合。
工作集是固有性质,常驻集取决于系统分配给进程的物理页面数目和所采用的置换算法。如果一个进程的常驻集与工作集尽量重叠,则不会造成太多缺页中断。当常驻集大小达到某个数目后,再分配物理页帧也不会有明显下降的缺页率——可以把多出来的物理页帧分给其他程序了。
2个全局算法:
工作集缺页置换算法:
追踪之前的(Δ)个引用。
老的页会随着时间不断的换出,不管是否有缺页中断。确保物理页帧始终有空余的,给其他程序提供内存,让系统的缺页率降低。
缺页率页面置换算法
刚才的窗口是固定的。
可变分配策略:常驻集大小可变
可采用全局页面置换的方式,当发生一个缺页中断时,被置换的页面可以在其他进程中,各个并发进程竞争地使用物理页面。依据是缺页率。多的说明需要内存。缺页率算法(PFF, page fault frequency)动态调整常驻集的大小。性能较好,但增加了系统开销
缺页率=缺页次数/内存访问次数
=1/缺页的平均时间间隔
影响因素有页面置换算法,分配给进程的物理页面数目(越多越小),页面本身的大小(页面大则会小),编程方法(局部性好就会小)
若缺页率高则增加工作集(Δ)来分配更多物理页面,若过低则减少工作集来减少其物理页面。使缺页率保持在一个合理的范围内。各个程序之间保持一个平衡。
具体机制:根据缺页的时间间隔来判断 动态更新
保持追踪缺页概率,记录上次缺页到这次的时间间隔
t(current) -t(last),与T比较(自定义一个合理的间隔),若大于T,则缺页率小,可增加工作集,否则增加缺失页到工作集中。
抖动问题(thrashing):
如果分配给一个进程的物理页面太少,常驻集远小于工作集,则缺页率会很大,频繁在内外存之间替换页面,使进程的运行慢,这种状态成为”抖动”。
随着驻留内存的进程数目增加,分配给每个进程的物理页面数不断减少,缺页率上升。因此OS要选择一个适当的进程数目和进程需要的帧数,在并发水平和缺页率中达到平衡。
抖动问题可能被本地的页面置换改善。加载控制(better criteria for load control: adjust MPL so that): 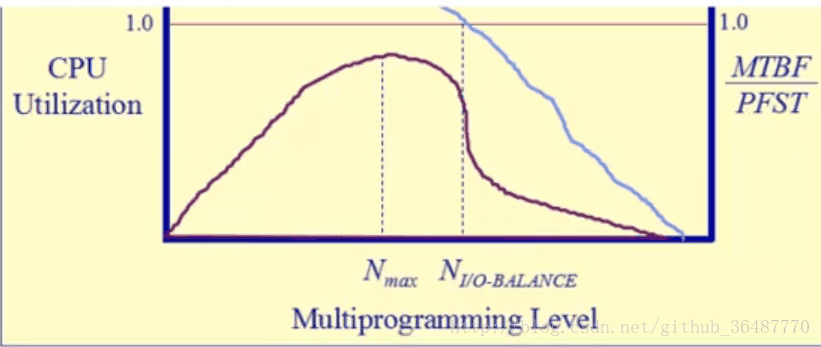
mean time between page faults(MTBF)= PFST page fault service time
∑▒WSt=内存的大小
程序开的多,OS忙于换进换出的I/O操作,用于运行程序的cpu少了。找到交汇点,此时可以并发执行的程序个数和cpu利用率都较好,总体达到平衡。另一方面,如果仅有一个程序,但它很大,也会导致抖动。
下篇在此: