
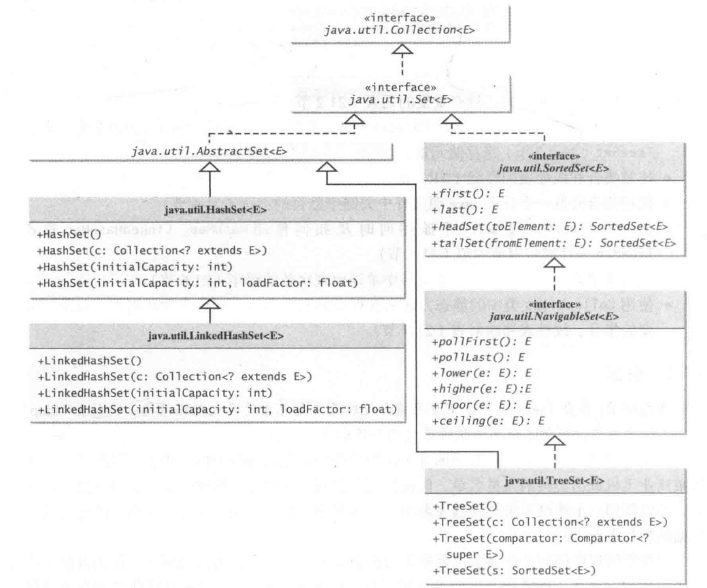
集合
可以使用集合的三个具体类HashSet、LinkedHashSet、TreeSet来创建集合


HashSet类
负载系数
当元素个数超过了容量与负载系数的乘积,容量就会自动翻倍
HashSet类可以用来存储互不相等的任何元素。考虑到效率的因素,添加到散列集中的对象必须以一种正确分散散列码的方式来实现hashCode方法。
如果两个对象相等,那么这两个对象的散列码必须一样。两个不相等的对象可能有相同的散列码
继承Collection接口,所以Collection中的所有方法,都可以用
例子:


LinkedHashSet类
LinkedHashSet用一个链表实现来扩展HashSet类,他支持对集合内的元素排序
HashSet中的元素是没有被排序的,而LinkedHashSet中的元素可以按照他们插入集合的顺序提取。
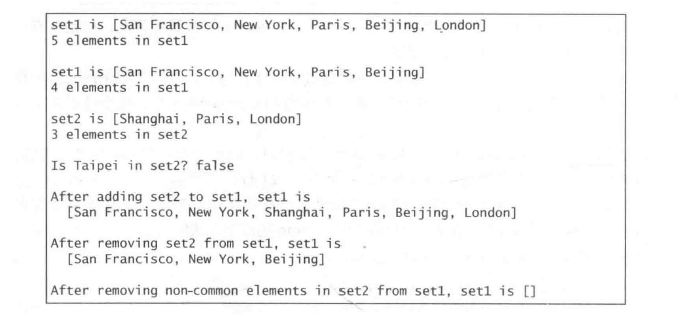
例子:


LinkedHashSet保持了元素插入时的顺序。
TreeSet类

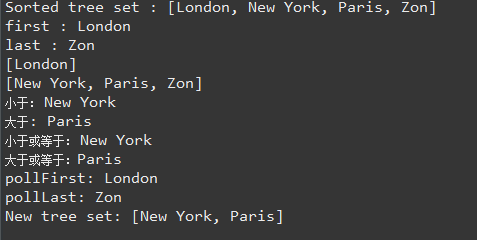
例子:
public class TextTreeSet { public static void main(String [] args) { Set<String> set = new HashSet<String>(); set.add("London"); set.add("Paris"); set.add("New York"); set.add("Zon"); TreeSet<String> treeSet = new TreeSet<String>(set); System.out.println("Sorted tree set : " + treeSet); System.out.println("first : " + treeSet.first()); System.out.println("last : " + treeSet.last()); System.out.println(treeSet.headSet("New York")); //输出New York 之前的数据 System.out.println(treeSet.tailSet("New York")); //输出 New York 之后的数据 System.out.println("小于: " + treeSet.lower("Paris")); //返回一个小于给定的元素 System.out.println("大于: " + treeSet.higher("New York")); //返回一个大于给定的元素 System.out.println("小于或等于: " + treeSet.floor("P")); //返回一个小于或等于给定的元素 System.out.println("大于或等于:" + treeSet.ceiling("P")); //返回一个大于或等于给定的元素 System.out.println("pollFirst: " + treeSet.pollFirst()); System.out.println("pollLast: " + treeSet.pollLast()); System.out.println("New tree set: " + treeSet); } }


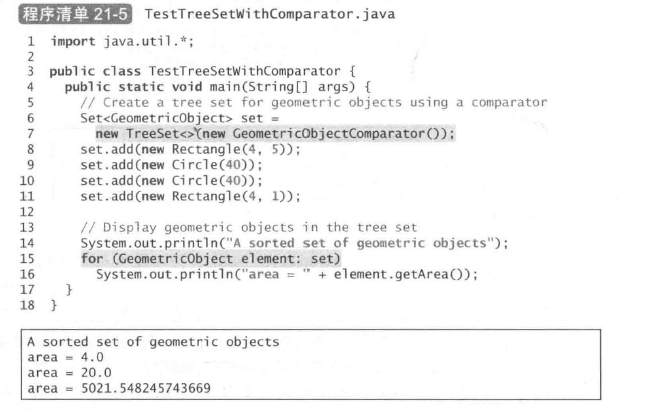
例子:
HashSet,LinkedHashSet和TreeSet有什么区别?


更新方法包括clear、put、putAll和remove,方法clear()从映射表中删除所有的条目。
方法put(K,V)为映射表中的指定的键和值添加条目,如果这个映射表原来就包含键的一个条目,这原来的值将被新的值所替代,并且返回与这个键相关联的原来的值
查询方法包括containsKey、containsValue、isEmpty和size。

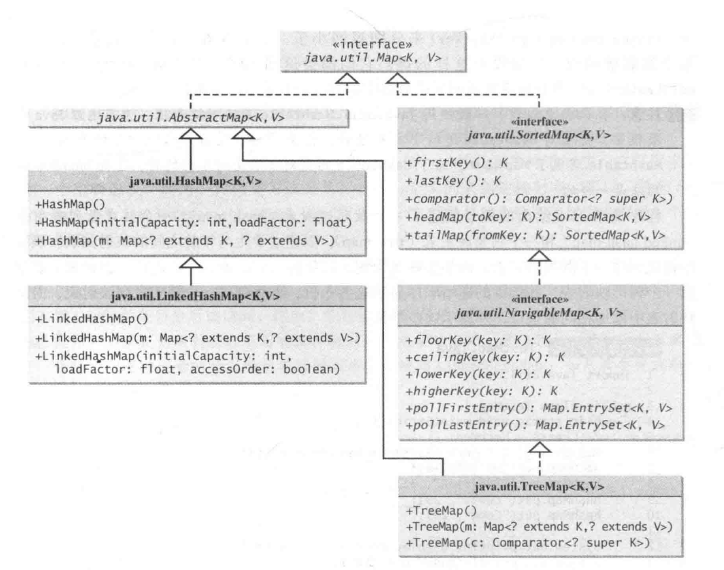
LinkedHashMap类是用链表来实现来扩展HashMap类,他支持映射表中的条目的排序。HashMap没有顺序,而LinkedHashMap,元素可以按照插入的顺序来顺序排序,也可以按他们被最后一次访问时的顺序从最早到最晚排序,
TreeMap类在遍历排好顺序的键时是很高效的。键可以使用Comparable接口或Comparator接口来排序
例子:



LinkedHashMap如果使用了按访问顺序排序,那么被访问的,会放在映射表的末尾
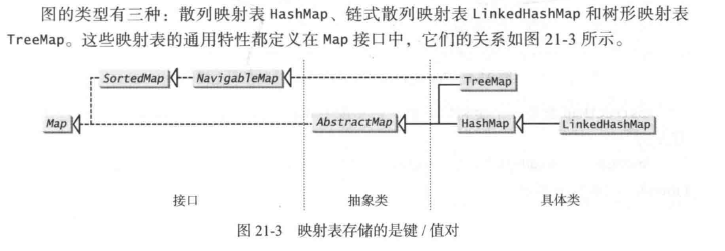
三种映射表的使用情况

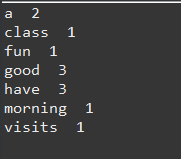
统计单词出现次数例子:
public class CountOccurentOfWords { public static void main(String [] args) { String text = "Good morning. have a good class. Have a good visits. Have fun!."; Map<String, Integer> map = new TreeMap<>(); String [] words = text.split("[ .,;:?!(){}]"); for(int i=0; i<words.length; i++) { String key = words[i].toLowerCase(); if(key.length() > 0) { if(!map.containsKey(key)) { map.put(key, 1); }else { int value = map.get(key); value++; map.put(key, value); } } } Set<Map.Entry<String, Integer>> wordSet = map.entrySet(); //调用entrySet()方法 可以返回一个Set集合 for(Map.Entry<String, Integer> s: wordSet) { System.out.println(s.getKey() + " " + s.getValue()); } } }
单元素与不可变的合集和映射表

