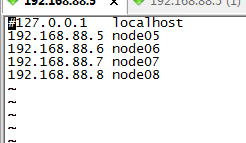
前提:1.机器最好都做ssh免密登录,最后在启动hadoop的时候会简单很多 免密登录看免密登录
2.集群中的虚拟机最好都关闭防火墙,否则很麻烦
3集群中的虚拟机中必须安装jdk.
具体安装步骤如下:
1.将 文件拷贝到linux系统中(可以拷贝到所以的虚拟机,也可以拷贝到一台虚拟机,最后进行复制)
文件拷贝到linux系统中(可以拷贝到所以的虚拟机,也可以拷贝到一台虚拟机,最后进行复制)
2.解压到/usr/local/hadoop ,看你需要安装到哪个目录就解压到哪个目录,解压命令 tar -zxvf ~/hadoop-1.2.1-bin.tar.gz -C /usr/local/hadoop ,解压完成就安装完了
接下来就应该修改配置文件
3.配置namenode和数据存储的位置,修改安装后hadoop-1.1.2下的conf文件夹下的core.site.xml文件
添加如下信息:(配置的namenode的ip和hadoop临时文件的地址)


<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node05:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-1.2</value>
</property>
</configuration>
4.配置节点数(datanode) 编辑slaves文件
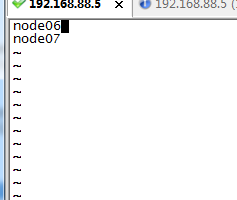
5.配置SecondaryNameNode,编辑masters文件,配置如下:
我一共用了三台虚拟机,node05是我的namenode节点.,node06,node07是我的datanode节点.同时node06也是我的SecondaryNameNode节点

6.配置数据的副本数 编辑hdfs-site.xml文件(副本数应该小于等于datanode的数量)
具体配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
7.将我们安装的hadoop复制到其余几台虚拟机中,注意配置文件保持一致,否则会失败
8.格式化namenode,到hadoop安装后的bin目录下执行 ./hadoop namenode -format命令
如果出现Error:JAVA_HOME.....错误 请在hadoop 的conf目录下的hadoop-env.sh文件中配置如下:

9.接下来就可以启动hadoop了
启动的时候,到bin目录下执行 ./start-dfs.sh命令,(因为我这里没有安装hdfs所以执行的这个命令)
10:测试是否成功,在每台虚拟机中输入jps测试是否启动成功
node05:namenode:
node06(是datanode也是SecondaryNameNode)
node07 datanode: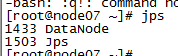
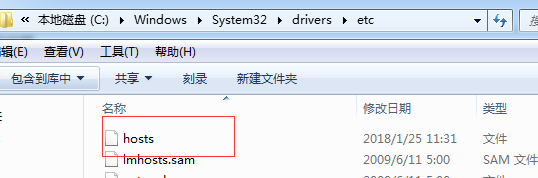
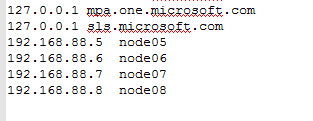
11,在物理机中,修改hosts文件,将我们的集群的ip和域名添加进去:
访问我们的namenode查看hadoop集群信息
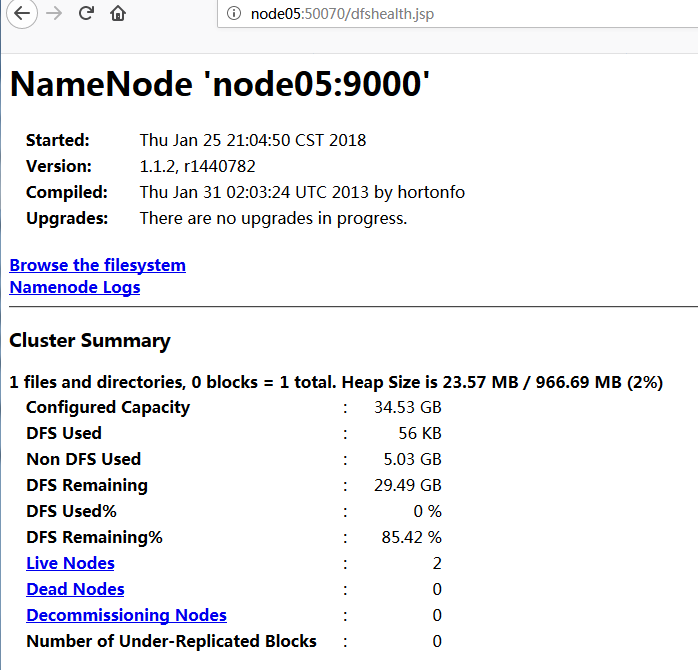
Live Nodes的节点数正确为2
如果Live Nodes的值为0
启动过程中动态查看hadoop的日志文件tail -f /usr/local/hadoop/hadoop-1.1.2/logs/hadoop-root-namenode-node05.log 查看有哪些错误,
如过提示
2018-01-25 20:54:09,903 INFO org.apache.hadoop.hdfs.server.namenode.DecommissionManager: Interrupted Monitor
java.lang.InterruptedException: sleep interrupted
修改/etc/hosts文件