输出单个文件中的前 N 个最常出现的英语单词。
功能1:输出文件中所有不重复的单词,按照出现次数由多到少排列,出现次数同样多的,以字典序排列。
功能2:指定文件目录,对目录下每一个文件执行 功能1的操作。
功能3:指定文件目录, 但是会递归遍历目录下的所有子目录,每个文件执行功能1的做操。
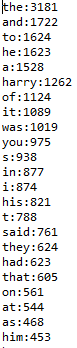
package Statistics; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Scanner; public class FileOutput1 { public static void main(String[] args)throws IOException//扔掉很重要 { File file = new File("Harry Potter and the Sorcerer's Stone.txt"); FileReader fr = new FileReader(file); BufferedReader br = new BufferedReader(fr);//构造一个BufferedReader类来读取文件 StringBuffer sb = new StringBuffer(); String line =null; while ((line=br.readLine())!=null){ sb.append(line);//将读取出的字符追加到stringbuffer中 } fr.close(); // 关闭读入流 String str = sb.toString().toLowerCase(); // 将stringBuffer转为字符并转换为小写 String[] words = str.split("[^(a-zA-Z)]+"); // 非单词的字符来分割,得到所有单词 Map<String ,Integer> map = new HashMap<String, Integer>() ; for(String word :words){ if(map.get(word)==null){ // 若不存在说明是第一次,则加入到map,出现次数为1 map.put(word,1); }else{ map.put(word,map.get(word)+1); // 若存在,次数累加1 } } // 排序 List<Map.Entry<String ,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(map.entrySet()); Comparator<Map.Entry<String,Integer>> comparator = new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> left, Map.Entry<String, Integer> right) { int i=left.getValue()-right.getValue(); if(i==0) { return (right.getKey().compareTo(left.getKey())); } return (left.getValue().compareTo(right.getValue())); } }; // 集合默认升序 Collections.sort(list,comparator); int n=list.size(); System.out.println("一共有"+n+"种单词"); System.out.println("请输入你要排序前几个单词:"); Scanner s=new Scanner(System.in); n=s.nextInt(); for(int i=0;i<n;i++){// 由高到低输出 System.out.println(list.get(list.size()-i-1).getKey() +":"+list.get(list.size()-i-1).getValue()); } } }