地理位置GEOHASH算法

图计算
spark序列化问题
类字段过多导致异常?extends Product with Serializable
正确理解分布式程序
数据倾斜,某个task数据量过大
调优过程
用spark处理数据的时候,怎么保证数据的一致性?
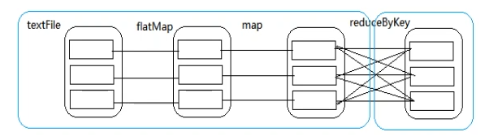
这是一个wordCount案例,RDD经过flatMap,map和reduceByKey3个过程,每个RDD都有多个分区。根据依赖关系,DAG(有向无环图)分成了两个stage,第一个stage里的父RDD和子RDD里的分区一一对应,是窄依赖,第二个stage里的父RDD里的分区对应多个子RDD里的分区,发生shuffle,所以是宽依赖。有了DAG就有了lineage(血缘),有了弹性和容错:
分区容错:比如子分区发生错误或者数据丢失,可以找到其父分区,然后重新计算过程就可以了
task容错:不会影响别的task,这个task重新计算就可以了
stage容错:找到上一个stage,然后计算就可以了
Executor容错:spark master重启Executor,将没完成的任务重新计算就可以了
用spark处理数据的时候,怎么保证数据一致性?
spark内部自己会实现数据一致性的(如上面解释)
离线:生成数据的时候给每条数据一个唯一的标识,计算后的结果数据里也存储该标识,,在数据恢复的时候,可以根据标识判断数据是否计算完成,该方式是很耗费资源和时间(因为需要另外使用一个程序来进行标识)
另一种方式,将结果删除,重新运行该离线任务即可。
实时:首先需要手动维护offset,用事务机制、幂等方式、数据和offset绑定到一起的方式
何为数据倾斜
正常的数据分布理论上都是倾斜的,也就是20-80原理:即80%的财富集中在20%的人手里。20%的用户贡献80%的访问量, 20%的用户使用80%的功能,不同的数据字段可能的数据倾斜
一般有两种情况:
数据频率倾斜:某一个区域的数据量要远远大于其他区域,区域的划分可以根据唯一标识key等。
数据大小倾斜:某部分记录的大小远远大于平均值。
·怎么发现数据倾斜
数据倾斜发生在shuffl过程中,根据key进行操作的时候,能尽量避免shuffle就避免。
开启spark-on-alone集群的时候,打开webui端,可以查看task和stage,有些task运行了80%,有些可能运行了20%。
· 需要确定出现倾斜key
拿到部分样例数据
对样例数据做countByKey( 得到的结果:Map(cd -> 1, ef -> 1, ab -> 2))countByKey是action,不是transform。
对倾斜的key做加盐操作(加盐就是拆分,可以给Key加一个0到9的随机数,就可以进行划分)
· 再进行shuffle操作
注意:加盐时,还是需要对所有的数据进行扫描。
方法二:在数据采集的过程中,进行加盐操作。比如某些key是最多的,按地区的来说,是上海北京广州的,就对此key加一个0-9的随机数。
spark广播变量的作用
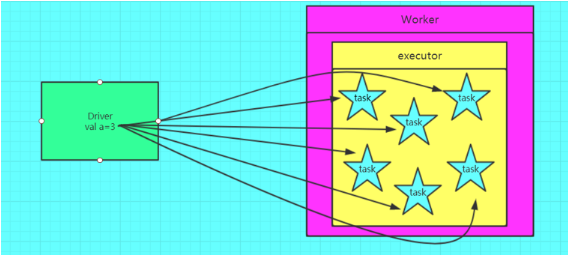
spark广播变量的定义在Driver端,在Driver端可以改变广播变量的值,在Executor端不可以改变,广播变量不能定义RDD,因为RDD存储的数据计算逻辑而不是数据,可以存储RDD之后的
结果。对变量进行广播,每个executor都有一份这个数据,那么task都可以共享,否则每个task都需要一份数据,尤其当数据量大的时候,更需要对变量进行广播。
缺陷:我们开始使用广播变量,也项目过程中遇到了字典需要不断更新或者扩展的问题,由于变量广播之后字典不能改变,所以我们使用了redis,而且随着字典的不断更新,我们的应用程序也需要做多更新,这时可以直接获取redis的数据即可,不用广播变量。这种方式即节省缓存又可以灵活的更新数据。