spark
./sbin/start-all.sh
./sbin/start-history-server.sh
web-ui: master:8080
redis
是一个开源、高效的Key-value非关系型数据库
单机版:启动服务 ./redis-server redis.conf
启动服务器:./start-all.sh
创建集群服务器./redis-trib.rb create --replicas 1 192.168.139.200:7001 192.168.139.200:7002 192.168.139.200:7003 192.168.139.200:7004 192.168.139.200:7005 192.168.139.200:7006
启动客户端:../bin/redis-cli -h 192.168.139.200 -p 7001 -c
在集群中:cluster nodes查看所有节点的情况, set key,get key ,例如:set s1 111 ,get s1
kafka
是一个分布式的,容错的,高效的消息通到。主要用于做实时的数据流、构建实时应用等。
设计目标:为处理实时数据提供一个统一、高吞吐量、低延迟的平台。
kafka是一个分布式消息队列:生产者、消费者的功能。
启动:先保证zk集群启动
再启动kafka
/opt/apps/kafka/bin/kafka-topics.sh --list --zookeeper master:2181
/opt/apps/kafka/bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic nginxdata1906
/opt/apps/kafka/bin/kafka-topics.sh --delete --zookeeper master:2181 --topic nginxdata1906
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
/opt/apps/kafka/bin/kafka-console-consumer.sh --zookeeper master:2181 --from-beginning --topic nginxdata1906
/opt/apps/kafka/bin/kafka-console-producer.sh --broker-list master:9092 --topic nginxdata1906
四大核心API
Producer API(生产者API)允许一个应用程序去推送流式记录到一个或者多个kafka的topic中。
Consumer API(消费者API)允许一个应用程序去订阅消费一个或者多个主题,并处理生产给他们的流式记录。
Streams API(流式API)允许应用程序作为一个流处理器,消费一个或多个主题的输入流,并生成一个或多个主题到输出流,从而有效地将输入流转换为输出流。
Connector API(连接器API)允许构建和运行将Kafka主题连接到已经存在应用程序或数据系统的可重用生产者或消费者。例如,到关系数据库的连接器可能捕获对表的每个更改。
HDFS
遍历创建:hdfs dfs -mkdir -p /csair/data/rule-black-list/
processDate
就是一个对象,一个类,可以封装多个字段,类似:
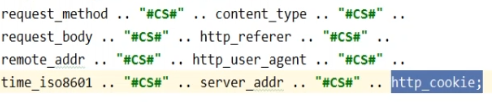
spider-csair
反爬虫脚本,当运行反爬虫脚本时,由于脚本中指定了(private static String basePath = "http://192.168.139.200:10086")访问的服务器为虚拟机上的Nginx服务器,当nginx接收到爬虫请求,然后会加载配置,当加载到Lua脚本文件的时候,Lua脚本文件内部写了对接kafka的相关代码,所以会将爬虫的一些信息发送到Kafka中。
Streamingmonitor1906
common:通用类,包含bean(对某些数据集中封装的对象),util(帮助类,工具类)
dataprocess:处理数据管理的,包含businessprocess(不同需求对应不同方法都放在此包中),constants,launch(写对应的业务逻辑,由自己写)
rulecompute:规则计算,用于实时处理的
链路统计
一个链路就是一个服务器,统计链路就是实时统计nginx服务器的数量
为了区分不同天数的链路对应的数据,在存入redis时需要将server_addr加时间戳
活跃连接数:首先需要在lua脚本里的数据拼接ngx.var.connections_active
活跃连接数统计过程:(server_addr, connections_active ) 服务器地址和数量
 由于每次connection_active记录的都是最后一个,所以
由于每次connection_active记录的都是最后一个,所以

.reduceByKey((x,y)=>y)就是不断循环取每个key里最后的那个数,就是最大的数
kafka的几个topic
nginxdata1906:存放lua从nginx拿到数据,并将数据保存到kafka中的nginxdata1906这个topic中
processedQuery:存放处理后的查询数据,
processedBook:存放处理后的预定数据
zookeeper的作用:
分布式协调服务框架