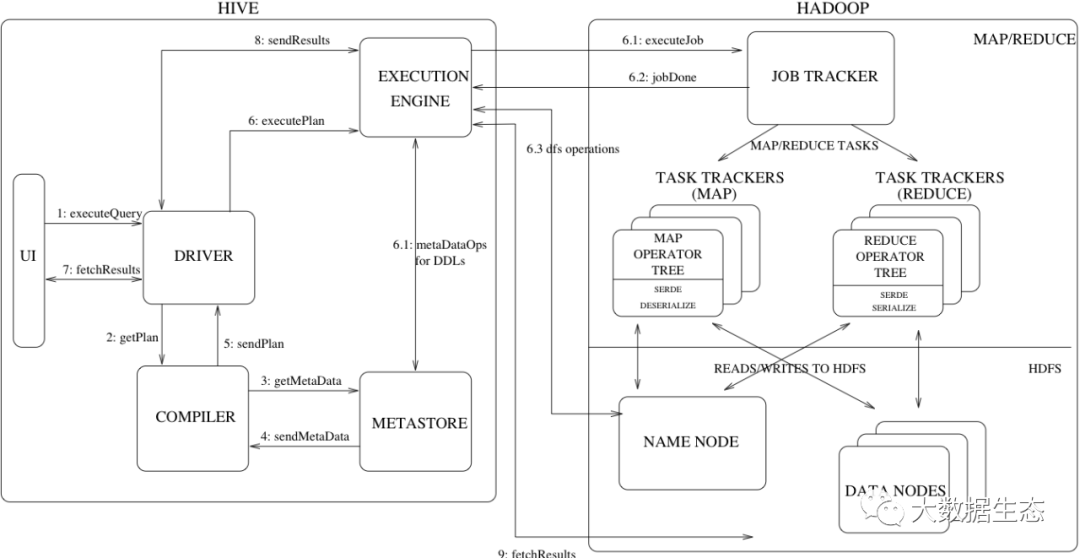
1. HiveServer1
在了解 HiveServer2 之前我们先来了解一下 HiveServer1(或者称之为 HiveServer)。
HiveServer 是一种可选的 Hive 内置服务,可以允许远程客户端使用不同编程语言向 Hive 提交请求并返回结果。HiveServer 是建立在 Apache ThriftTM(http://thrift.apache.org/) 之上的,因此有时会被称为 Thrift Server,这可能会导致我们认知的混乱,因为新服务 HiveServer2 也是建立在 Thrift 之上的。自从引入 HiveServer2 后,HiveServer 也被称为 HiveServer1。

为什么有了 HiveServer,还要引入 HiveServer2 ?主要是因为 HiveServer 有如下的局限性:
-
支持远程客户端连接,但一次只能连接一个客户端,无法处理来自多个客户端的并发请求。这实际上是因为受到 HiveServer 暴露的 Thrift 接口所限制,并且不能通过修改 HiveServer 源代码来解决。
-
没有会话管理的支持。
-
不提供身份验证支持。
从 Hive 1.0.0 版本开始,Hive 发行版中删除了 HiveServer。需要切换到 HiveServer2。
2. HiveServer2
HiveServer2 是一种能使客户端执行 Hive 查询的服务。HiveServer2 是 HiveServer1 的改进版,HiveServer1 已经被废弃。HiveServer2 对 HiveServer 进行了重写来解决上述问题。
HiveServer2 作为复合服在单个进程中运行,其中包括基于 Thrift 的 Hive 服务(TCP或HTTP)以及用于 Web UI的 Jetty Web 服务。HiveServer2 可以支持多客户端并发和身份认证。旨在为开放API客户端(如JDBC和ODBC)提供更好的支持。
2.1 架构
HiveServer2 实现了一个新的基于 Thrift 的 RPC 接口,该接口可以处理客户端并发请求。当前版本支持 Kerberos,LDAP 以及自定义可插拔身份验证。新的 RPC 接口也是 JDBC 和 ODBC 客户端更好的选择,尤其是对于元数据访问。
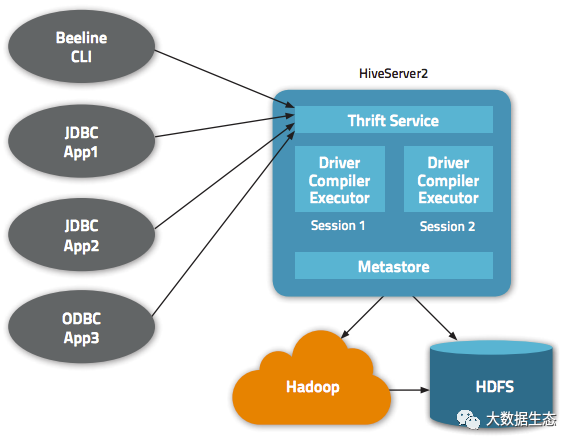
与 HiveServer1 一样,HiveServer2 也是 Hive 执行引擎的容器。对于每个客户端连接,都会创建一个新的执行上下文,以服务于来自客户端的 Hive SQL 请求。新的 RPC 接口使服务器可以将 Hive 执行上下文与处理客户端请求的线程相关联。
2.2 依赖
-
Metastore:Metastore 可以配置为嵌入式(与 HiveServer2 同一个进程)或者远程服务(也是基于 Thrift 的服务)。HiveServer2 访问 Metastore 以获取编译所需的元数据。
-
Hadoop 集群:HiveServer2 为不同执行引擎(MapReduce/Tez/Spark)提供物理执行计划,并将作业提交到 Hadoop 集群执行。
我们可以在下图中找到 HiveServer2 与依赖组件之间的相互关系:
欢迎关注我的公众号和博客: