Prometheus(普罗米修斯)
从零搭建Prometheus监控报警系统(一)
Prometheus数据持久化存储(二)
——— 先“安利”下理论知识
什么是Prometheus?
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。
Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8s的一个子项目,用于获取集群的性能数据)相比功能更加完善、更全面。
Prometheus性能也足够支撑上万台规模的集群。
Prometheus的特点
- 多维度数据模型
- 灵活的查询语言
- 不依赖分布式存储,单个服务器节点是自主的
- 通过基于HTTP的pull方式采集时序数据
- 可以通过中间网关进行时序列数据推送
- 通过服务发现或者静态配置来发现目标服务对象
- 支持多种多样的图表和界面展示,比如Grafana等
基本原理
Prometheus的基本原理是通过HTTP协议周期性的抓取被监控组件状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
服务过程
- Prometheus Daemon负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
- Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
- Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
- PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
- Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
组件
- Prometheus :主程序,Prometheus服务端,由于存储及收集数据,提供相关api对外查询用,主要是负责存储、抓取、聚合、查询方面。
- Alertmanager:告警管理器,主要是负责实现报警功能。
- Pushgateway :程序,主要是实现接收由Client push过来的指标数据,在指定的时间间隔,由主程序来抓取。
- *_exporter :类似传统意义上的被监控端的agent,有区别的是,它不会主动推送监控数据到server端,而是等待server端定时来收集数据,即所谓的主动监控
———理论太枯燥,安装部署开始
部署开始
环境描述
| 名称 | 版本 |
|---|---|
| OS | Ubuntu 16.04 |
| Docker | 18.09.1-ce |
服务器信息
| IP | 角色 |
|---|---|
| 192.168.1.20 | Server |
| 192.168.1.17 | Client |
登录Server服务器
ssh user@192.168.1.20
创建工作目录:mkdir ~/prometheus
cd ~/prometheus
一、部署prometheus server
- 通过docker方式部署
目录结构
prometheus
├── config
│ ├── prometheus.yml
│ └── rules
│ └── alert-rules.yml
├── data
├── docker-compose-prometheus.yml
└── README.md
//mkdir config data
Prometheus配置文件:
//cat config/prometheus.yml
global:
scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据。
external_labels:
monitor: 'codelab-monitor'
# 这里表示抓取对象的配置
scrape_configs:
#这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签
- job_name: 'prometheus'
scrape_interval: 5s # 重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090']
- job_name: 'linux-server' # 定义任务名
scrape_interval: 5s
static_configs:
- targets: ['192.168.1.20:9100'] # 客户端地址
labels:
instance: '192.168.1.20' # 标签,实例名,在后续报警通知获取此值
# 配置告警规则位置
rule_files:
- "rules/*rules.yml"
rules 告警规则
//cat config/rules/alert-rules.yml
groups:
- name: alert-rule # 规则组名称
rules:
- alert: NodeServerDown # 单个规则的名称
expr: up{job="linux-server"} == 0 # 匹配规则, job与prometheus.yml配置文件内job_name对应
for: 15s # 持续时间
labels: # 标签
severity: urgent # 自定义lables,级别
annotations: # 告警正文
summary: "服务器实例 {{ $labels.instance }} 丢失" # 告警总结概述
description: "服务器实例 {{ $labels.instance }} 不在线,已经停止" # 告警描述
- alert: NodeFilesystemUsage-high
expr: ( 1 - (node_filesystem_free_bytes{fstype=~"ext3|ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext3|ext4|xfs"}) ) * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 文件系统磁盘使用率过高"
description: "{{$labels.instance}}: 节点文件系统使用率高于80%,(当前值为: {{ $value }})"
- alert: NodeMemoryUsage
expr: ( 100 - (((node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes)/node_memory_MemTotal_bytes) * 100)) > 70
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到节点内存使用率过高"
description: "{{$labels.instance}}: 节点内存使用率超过80%,当前使用率: {{ $value }})"
- alert: NodeCPUUsage
expr: ( 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到节点CPU使用率过高"
description: "{{$labels.instance}}: 节点CPU使用率超过80%,当前使用率: {{ $value }})"
# ---------------------------------------------------
- alert: "磁盘读 I/O 超过 30MB/s"
expr: irate(node_disk_read_bytes_total{device="sda"}[1m]) > 30000000
for: 30s
labels:
severity: warning
annotations:
sumary: "服务器实例 {{ $labels.instance }} I/O 读负载 告警通知"
description: "{{ $labels.instance }}I/O 每分钟读已超过 30MB/s,当前值: {{ $value }}"
- alert: "磁盘写 I/O 超过 30MB/s"
expr: irate(node_disk_written_bytes_total{device="sda"}[1m]) > 30000000
for: 30s
annotations:
labels:
severity: warning
sumary: "服务器实例 {{ $labels.instance }} I/O 写负载 告警通知"
description: "{{ $labels.instance }}I/O 每分钟写已超过 30MB/s,当前值: {{ $value }}"
- alert: "网卡流出速率大于 10MB/s"
expr: (irate(node_network_transmit_bytes_total{device!~"lo"}[1m]) / 1000) > 1000000
for: 30s
labels:
severity: warning
annotations:
sumary: "服务器实例 {{ $labels.instance }} 网卡流量负载 告警通知"
description: "{{ $labels.instance }}网卡 {{ $labels.device }} 流量已经超过 10MB/s, 当前值: {{ $value }}"
Docker-compose启动文件
//cat docker-compose-prometheus.yml
version: "2.3"
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
hostname: prometheus
volumes:
- /prometheus/prometheus/config:/etc/prometheus
- /prometheus/prometheus/data:/prometheus
- /etc/localtime:/etc/localtime
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--log.level=info'
- '--web.listen-address=0.0.0.0:9090'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention=15d'
- '--query.max-concurrency=50'
- '--web.enable-lifecycle'
ports:
- "9090:9090"
logging:
driver: "json-file"
restart: always
README
# prometheus
* config: 配置文件
* data: 数据文件(用于留存数据)
* docker-compose-prometheus.yml: Docker启动文件
## 启动&停止
docker-compose -f docker-compose-prometheus.yml up -d
docker-compose -f docker-compose-prometheus.yml down
# 重新加载配置
curl -X POST http://192.168.1.20:9090/-/reload
# 访问
http://192.168.1.20:9090/
可以看到Prometheus页面。
http://192.168.1.20:9090/metrics
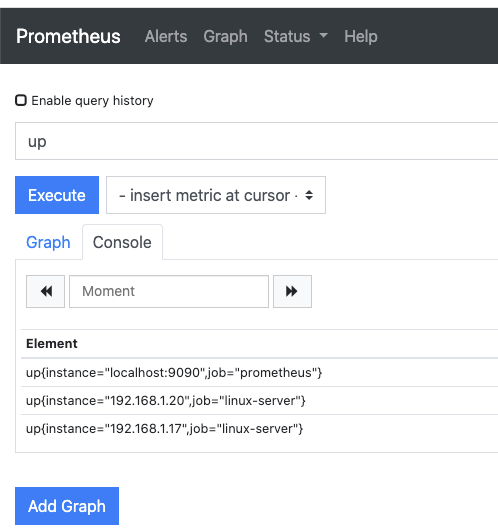
默认配置的9090端口,默认prometheus会抓取自己的/metrics接口,在页面上Graph搜索口输入“up”可以看到监控数。
二、部署客户端程序,提供metrics接口
1、通过node exporter提供metrics
Client:192.168.1.17
目录结构
node_exporter
├── LICENSE
├── node_exporter
├── NOTICE
└── README.md
//下载
curl -OL https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
tar -xzf node_exporter-0.17.0.linux-amd64.tar.gz
mv node_exporter-0.17.0.linux-amd64 node_exporter
//启动方式1
screen -S node_exporter
./node_exporter
// 指定端口启动
./node_exporter # 直接启动默认端口9100
./node_exporter --web.listen-address=":9111" #指定端口启动
//启动方式2
创建用户
groupadd prometheus
useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus
chown prometheus.prometheus -R /usr/local/prometheus
创建Systemd服务
//mv node_exporter /usr/local/bin/node_exporter
//cat /etc/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/bin/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
//启动
systemctl start node_exporter
systemctl enable node_exporter
prometheus.yml配置文件增加如下:
- targets: ['192.168.1.17:9111']
labels:
instance: '192.168.1.17'
然后把接口再次配置到prometheus.yml, 重新载入配置curl -X POST http://192.168.1.20:9090/-/reload
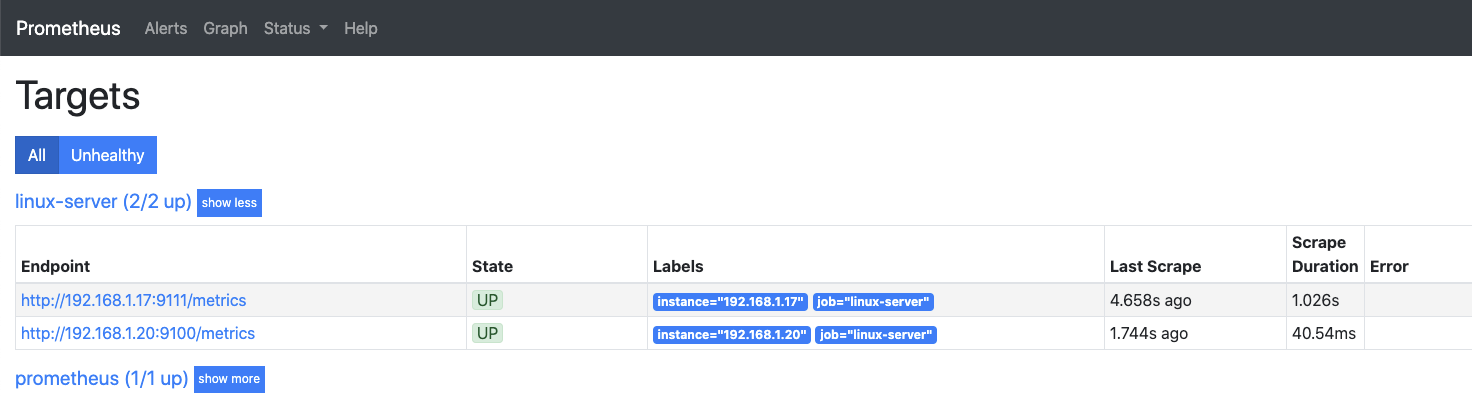
然后访问http://192.168.1.20:9090/
Status — Targets 可以看到客户端相关信息
2、通过push gateway提供metrics
- pushgateway是为了允许临时作业和批处理作业向普罗米修斯公开他们的指标。
由于这类作业的存在时间可能不够长, 无法抓取到, 因此它们可以将指标推送到推网关中。 - Prometheus采集数据是用的pull也就是拉模型,这从我们刚才设置的5秒参数就能看出来。但是有些数据并不适合采用这样的方式,对这样的数据可以使用Push Gateway服务。
它就相当于一个缓存,当数据采集完成之后,就上传到这里,由Prometheus稍后再pull过来。
//cat docker-compose-pushgateway.yml
version: "2.3"
services:
pushgateway:
image: prom/pushgateway:latest
container_name: pushgateway
hostname: pushgateway
volumes:
- /etc/localtime:/etc/localtime
ports:
- "9091:9091"
restart: always
访问http://192.168.1.17:9091/可以看到pushgateway已经运行起来了。
prometheus.yml配置文件增加如下:
Pushgateway 方式配置
- job_name: 'pushgateway'
scrape_interval: 5s
static_configs:
- targets: ['192.168.1.17:9091']
labels:
instance: '192.168.1.17'
然后把以上接口再次配置到prometheus.yml, 重新载入配置curl -X POST http://192.168.1.20:9090/-/reload
三、安装Grafana展示
- Grafana是用于可视化大型测量数据的开源程序,它提供了强大和优雅的方式去创建、共享、浏览数据。
Dashboard中显示了你不同metric数据源中的数据。 - Grafana最常用于因特网基础设施和应用分析,但在其他领域也有用到,比如:工业传感器、家庭自动化、过程控制等等。
- Grafana支持热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus等。
目录结构
grafana/
├── config
│ ├── grafana.ini
│ └── provisioning
├── dashboards
├── data
├── docker-compose-grafana.yml
├── logs
└── README.md
还是给予docker安装
mkdir config dashboards data logs
//cat docker-compose-grafana.yml
version: "2.3"
services:
grafana:
image: grafana/grafana:latest
container_name: grafana
hostname: grafana
restart: always
volumes:
- /prometheus/grafana/config:/etc/grafana
- /prometheus/grafana/logs:/var/log/grafana
- /prometheus/grafana/data:/var/lib/grafana
- /prometheus/grafana/dashboards:/etc/grafana/provisioning/dashboards
- /etc/localtime:/etc/localtime
ports:
- "3000:3000"
user: "104"
//cat README
# grafana
* config: 配置文件
* dashboards: 数据文件
* data: 数据文件
* logs: 日志文件
* docker-compose-grafana.yml: Docker启动文件
#启动&停止
docker-compose -f docker-compose-grafana.yml up -d
docker-compose -f docker-compose-grafana.yml down
访问http://192.168.1.20:3000/默认用户密码:admin/admin

Add data source 添加数据源
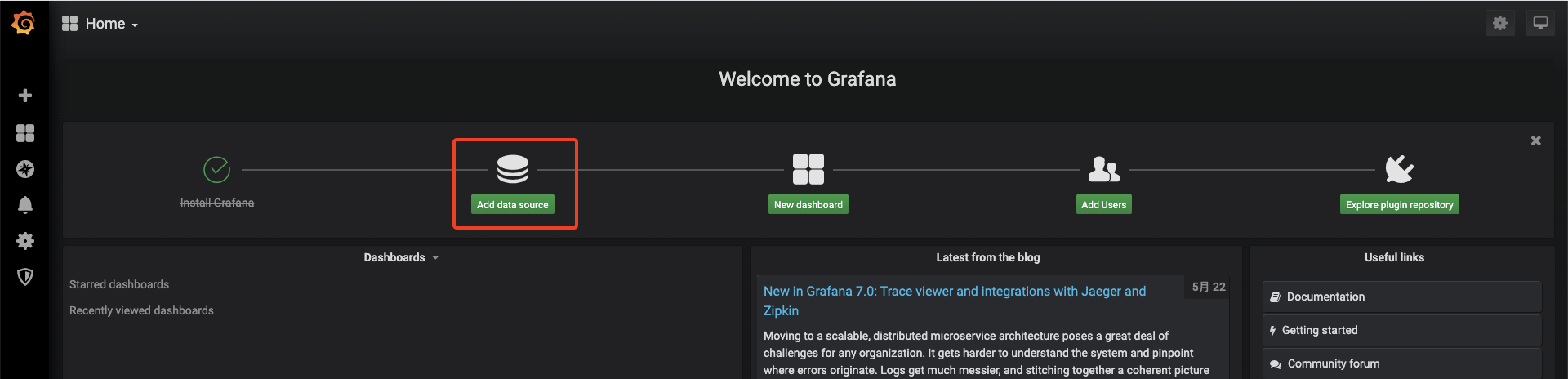

把Prometheus的地址填上
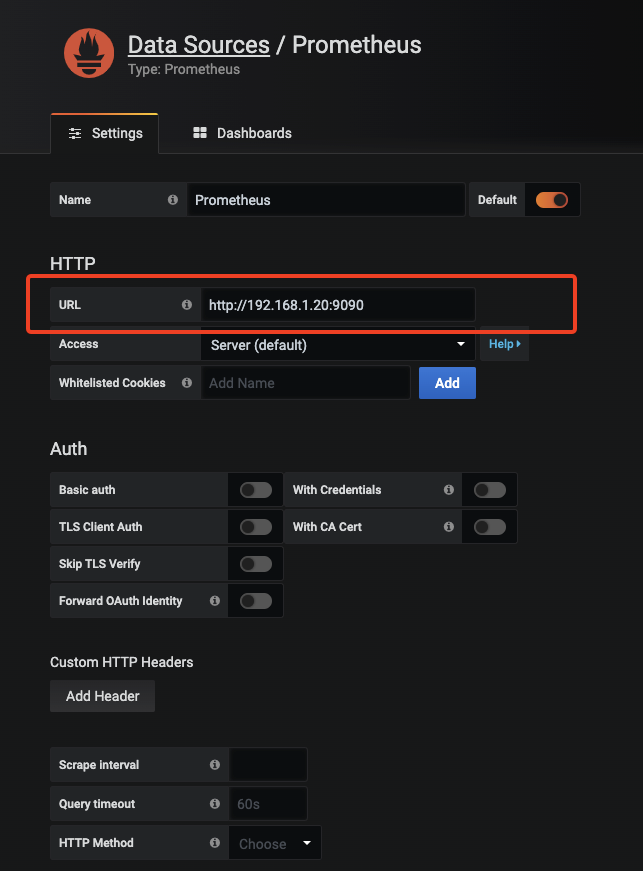
Save& Test
导入prometheus的模板,增加一个个人认为比较全的模版
到Grafana官网获取模版
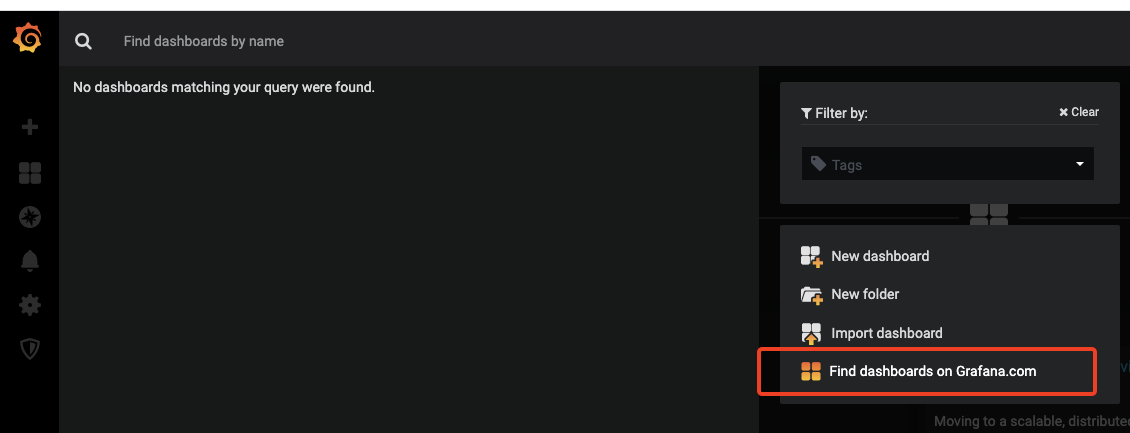
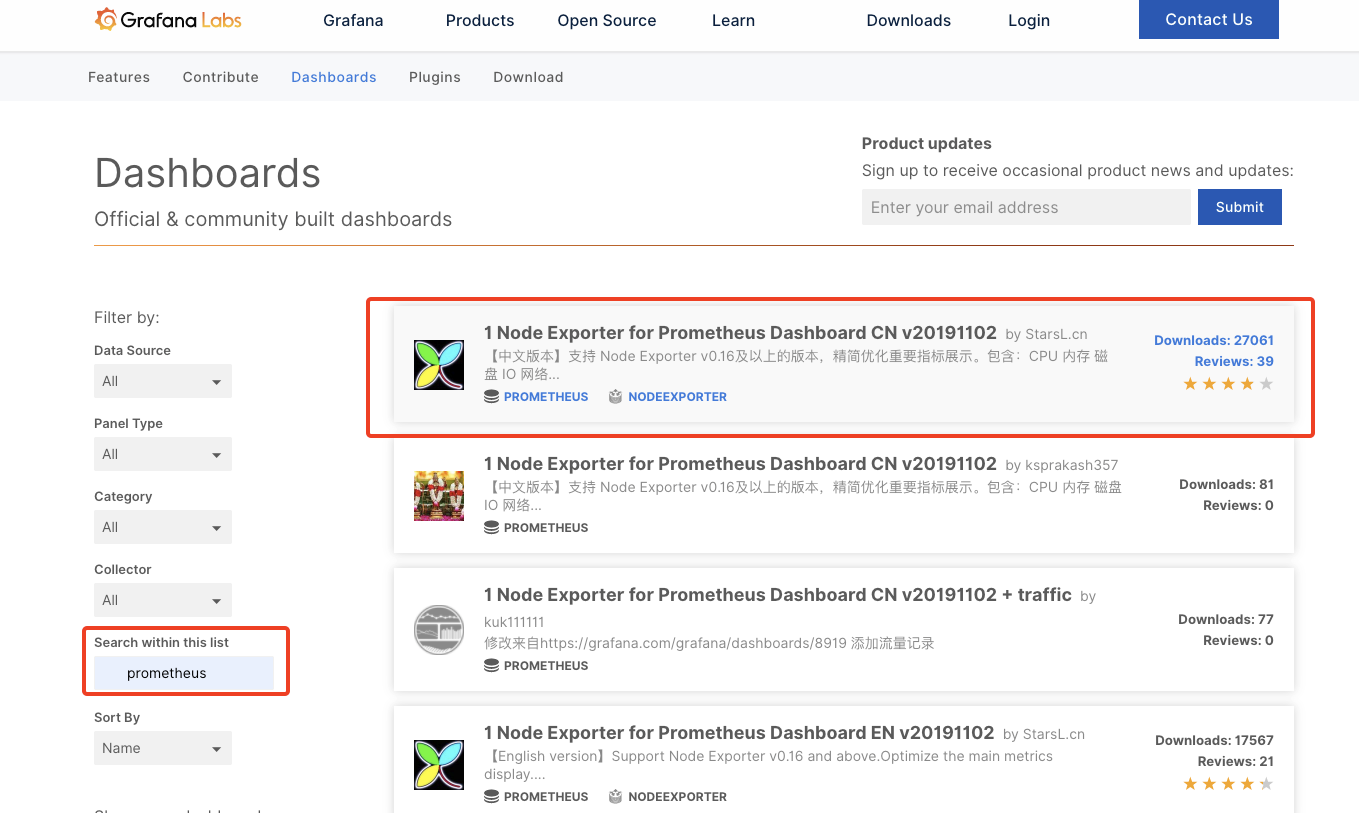
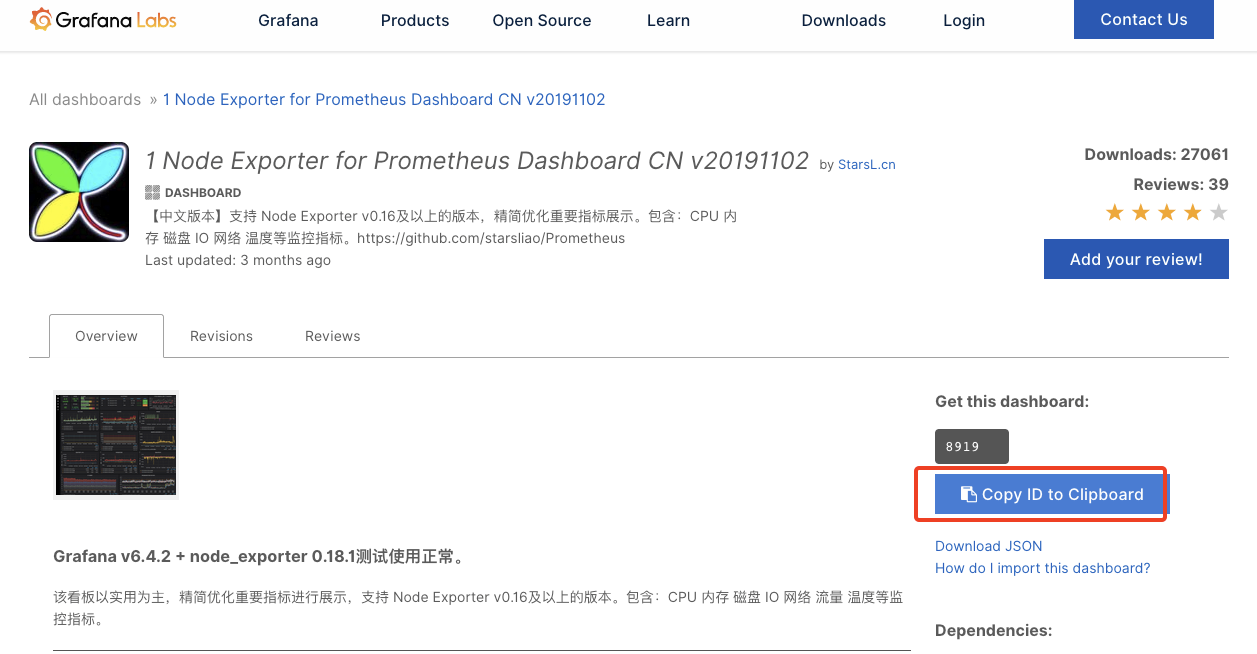
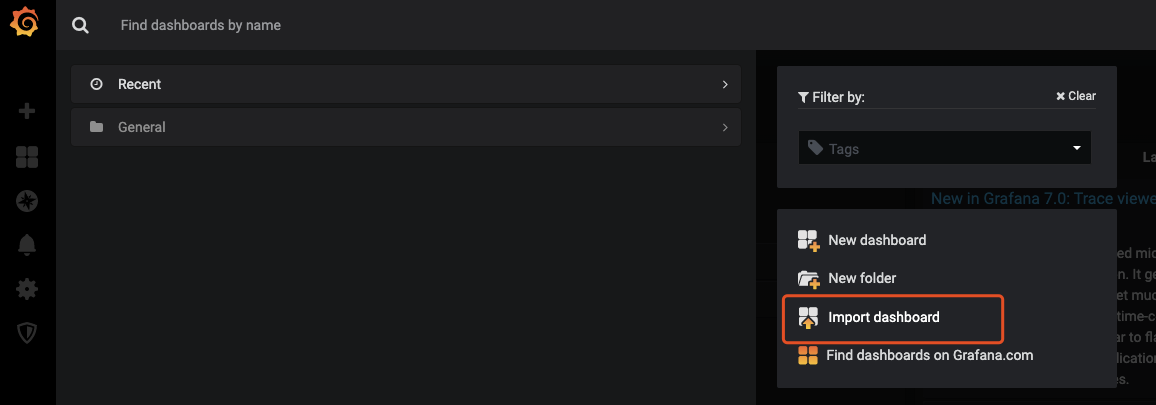
复制模版ID,返回grafana页面导入模版Import dashboard
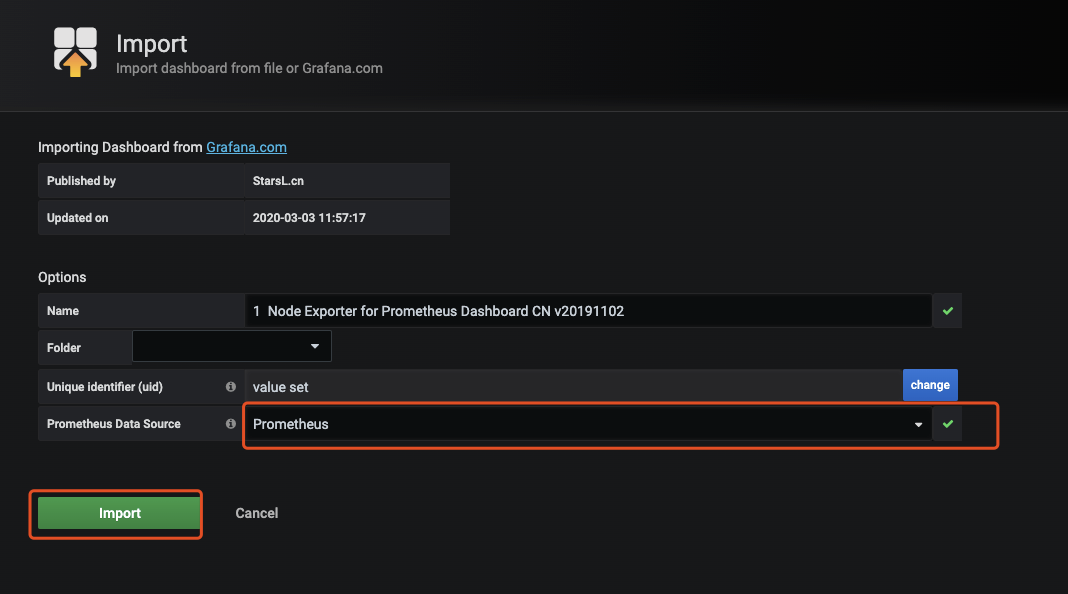
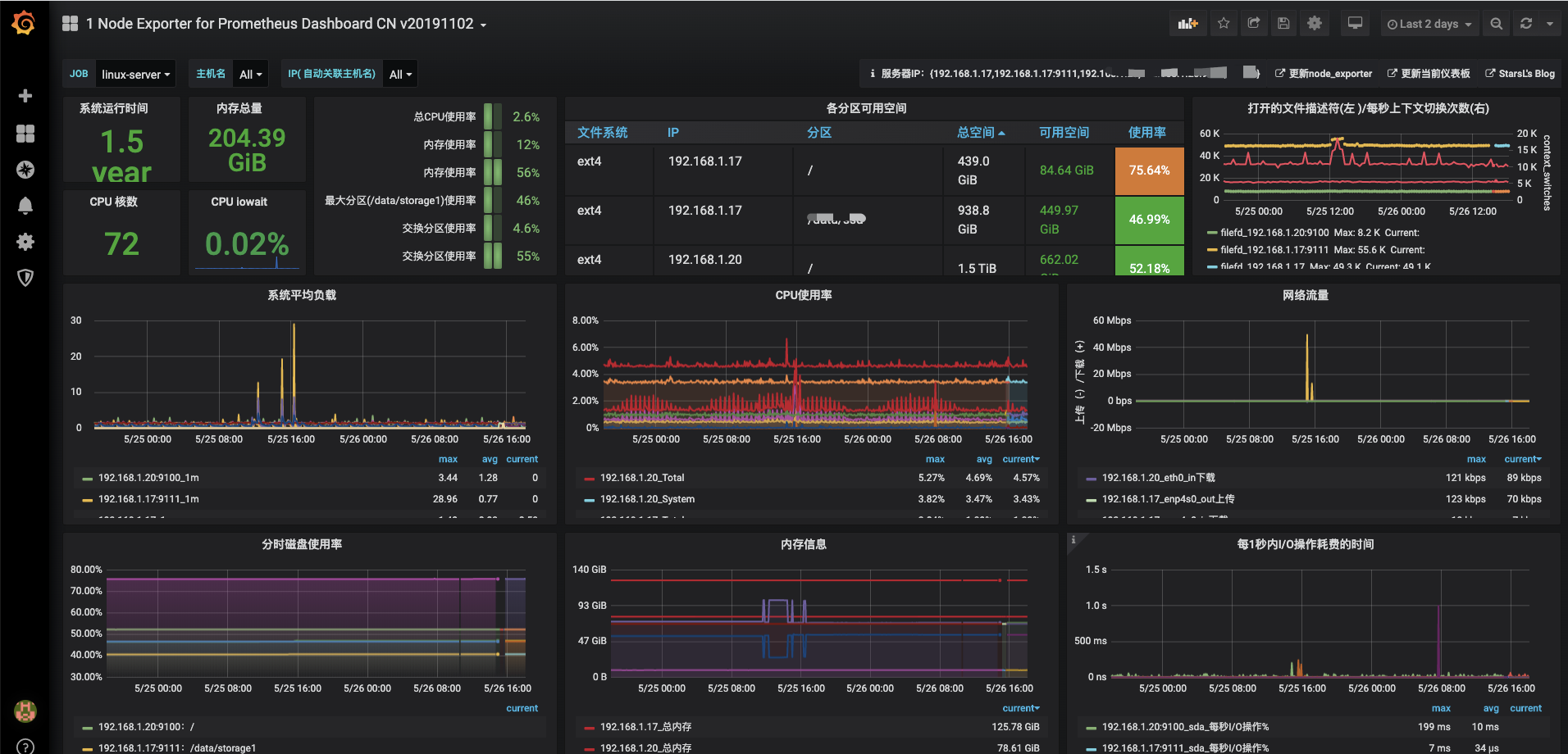
一款高大上的图表就展示出来了,个人根据自己的需要进行修改配置。
四、Alertmanager监控告警
- Pormetheus的警告由独立的两部分组成。
- Prometheus服务中的警告规则发送警告到Alertmanager。
然后这个Alertmanager管理这些警告。包括silencing, inhibition, aggregation,以及通过一些方法发送通知,例如:email,PagerDuty,HipChat,钉钉和企业微信等。 - 建立警告和通知的主要步骤:
创建和配置Alertmanager
启动Prometheus服务时,通过-alertmanager.url标志配置Alermanager地址,以便Prometheus服务能和Alertmanager建立连接
目录结构
alertmanager/
├── config
│ ├── alertmanager.yml
│ └── template
│ └── wechat.tmpl
├── data
├── docker-compose-alertmanager.yml
└── README.md
通过企业微信自建应用报警通知
mkdir -p config/template data
alertmanager.yml配置文件
//cat config/alertmanager.yml
global:
resolve_timeout: 5m #处理超时时间,默认为5min
# 定义模板信息,可以自定义html模板,发邮件的时候用自己定义的模板内容发
templates:
- '/etc/alertmanager/template/wechat.tmpl'
# 定义路由树信息,这个路由可以接收到所有的告警,还可以继续配置路由,比如project: APP(prometheus 告警规则中自定义的lable)发给谁
route:
group_by: ['alertname'] # 报警分组依据
group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 10s # 在发送新警报前的等待时间
repeat_interval: 10m # 发送频率。发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'wechat' # 发送警报的接收者的名称,以下receivers name的名称
# 定义警报接收者信息
receivers:
- name: 'wechat' # 路由中对应的receiver名称
wechat_configs: # 微信配置
- send_resolved: true
to_user: '617cxxxxxxxxxxxxx' #接受消息用户ID
# to_party: '2' # 接受消息部门ID,在企业微信后台-通讯录查看
# to_tag: '3' 接受消息标签ID,在企业微信后台-通讯录查看
agent_id: 1000014 # 企业微信agentid
corp_id: 'wwxxxxxxxxx56x' # 企业微信corpid
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' # 企业微信apiurl
api_secret: 'iIql3qxxxxxxxxxxxxxxxx4' # 企业微信,自建应用apisecret
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
告警&恢复模版
//cat config/template/wechat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
========【告警通知】=========
告警程序: prometheus_alert
告警级别: {{ .Labels.severity }}
告警类型: {{ .Labels.alertname }}
告警主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
========【恢复通知】=========
恢复类型: {{ .Labels.alertname }}
恢复主机: {{ .Labels.instance }}
恢复主题: {{ .Annotations.summary }}
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- end }}
- Prometheus 邮件告警自定义模板的默认使用的是utc时间。其中
Add 28800e9就是表示加8个小时。
Prometheus.yml配置文件增加如下:
# 配置alertmanager告警发送消息配置
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.1.20:9093']
记得重新加载:curl -X POST http://192.168.1.20:9090/-/reload
五、配置Grafana,实现钉钉告警通知
// 编辑config/grafana.ini
修改root_url为root_url = http://192.168.1.20:3000/否则如果通过grafana配置报警,报警通知的地址是localhost
记得重启grafana服务
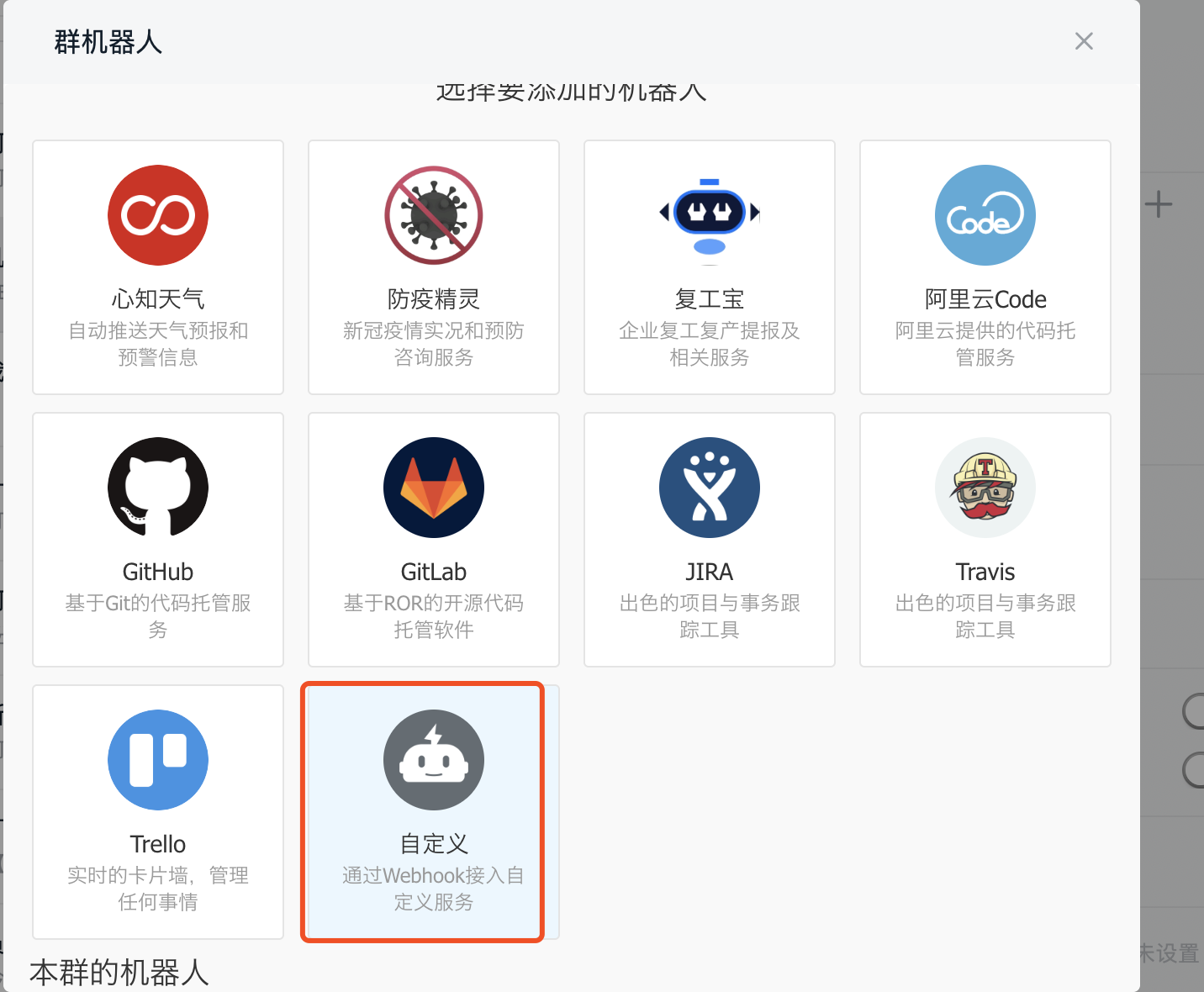
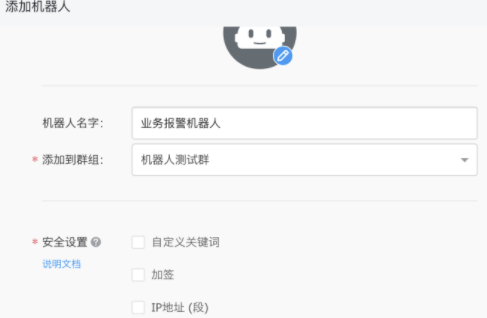
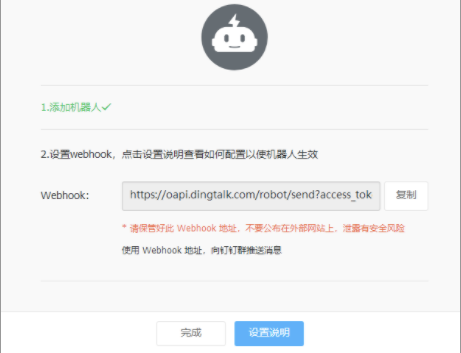
钉钉群聊创建机器人,获取webbook
步骤一:【电脑钉钉 】-【群聊】-【群设置】-【智能群助手】-【添加更多】-【添加机器人】-【自定义】-【添加】,编辑机器人名称和选择添加的群组。完成必要的安全设置(至少选择一种),勾选 我已阅读并同意《自定义机器人服务及免责条款》,点击“完成”即可
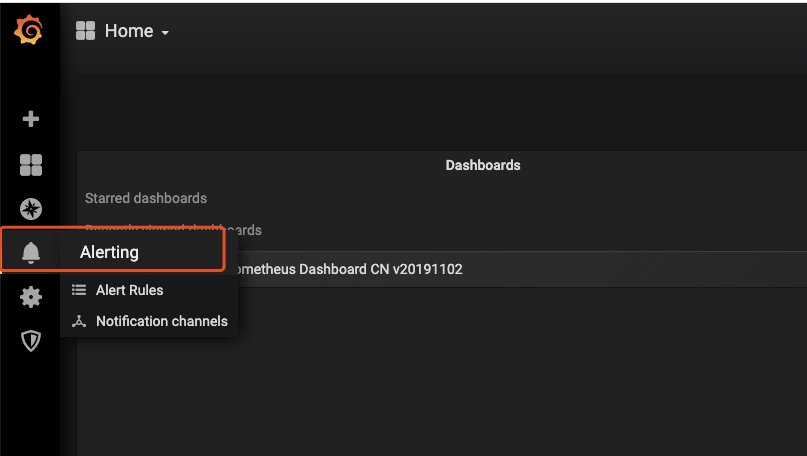
//登录Grafana页面,添加告警

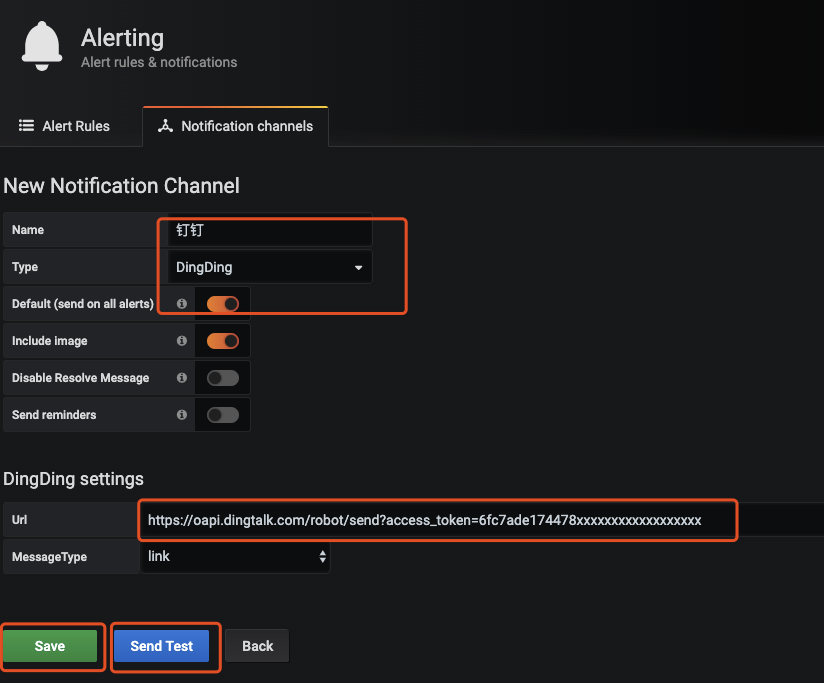
模版配置相应的规则
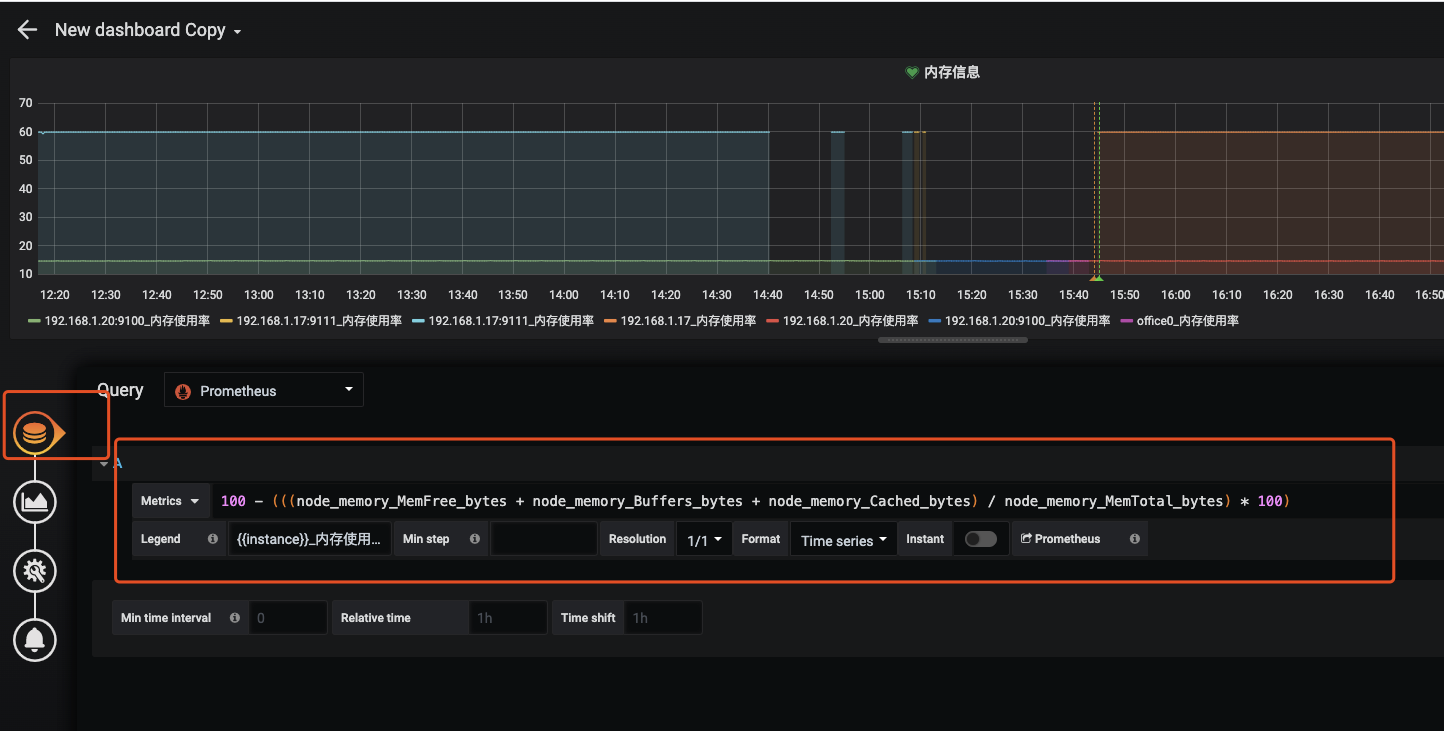
告警信息
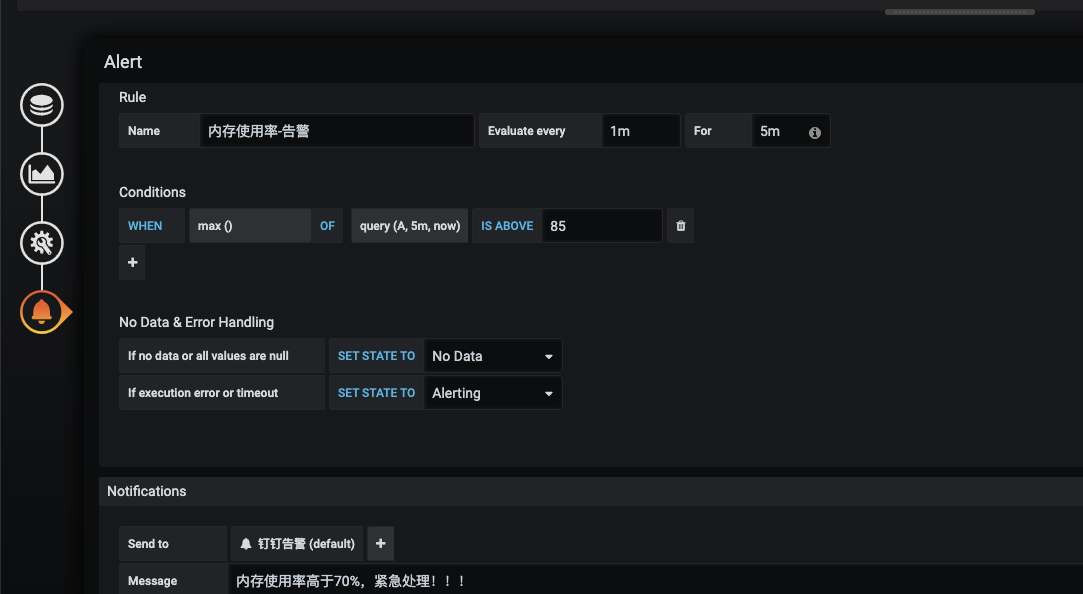
根据配置的规则触发报警

最后附上,完整的Prometheus.yml配置文件
global:
scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据。
external_labels:
monitor: 'codelab-monitor'
# 这里表示抓取对象的配置
scrape_configs:
#这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签
- job_name: 'prometheus'
scrape_interval: 5s # 重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090']
- job_name: 'linux-server' # 定义任务名
scrape_interval: 5s
static_configs:
- targets: ['192.168.1.20:9100'] # 客户端地址
labels:
instance: '192.168.1.20' # 标签,实例名,在后续报警通知获取此值
- targets: ['192.168.1.17:9111']
labels:
instance: '192.168.1.17'
# Pushgateway 方式配置
# - job_name: 'pushgateway'
# scrape_interval: 5s
# static_configs:
# - targets: ['192.168.1.17:9091']
# labels:
# instance: '192.168.1.17'
# 配置告警规则位置
rule_files:
- "rules/*rules.yml"
# 配置alertmanager告警发送消息配置
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.1.20:9093']
参考资料-从零搭建Prometheus监控报警系统(推荐)
参考资料-Prometheus+Grafana监控简介(推荐)
参考资料-prometheus-book
参考资料-prometheus配置企业微信报警
参考资料-prometheus报警规则模版
参考资料-监控指标-报警规则
官网文档