参考《deeplearning.ai 卷积神经网络 Week 2 听课笔记》。
1. AlexNet(Krizhevsky et al. 2012),8层网络。
学会计算每一层的输出的shape:对于卷积层,输出的边长 =(输入的边长 - filter的边长)/ 步长 + 1,输出的通道数等于filter的数量。每个filter的通道数等于输入的通道数。卷积层的参数 = filter的长 * filter的宽 * 输入的通道数 * filter的数量。池化层没有需要学习的参数。

图中分成两个通道是为了在不同GPU上处理。
2013年的ZFNet延续了AlexNet的架构(也是8层网络),优化了参数,取得了更好的效果(错误率从16.4%降到11.7%)。
2. VGGNet(Simonyan and Zisserman, 2014),16~19层网络。

三个3*3的filter串联等价于一个7*7的filter,用更小的filter的好处是增加了网络的深度,增加了非线性程度,更少的参数。
3. GoogLeNet(Szegedy et al., 2014)
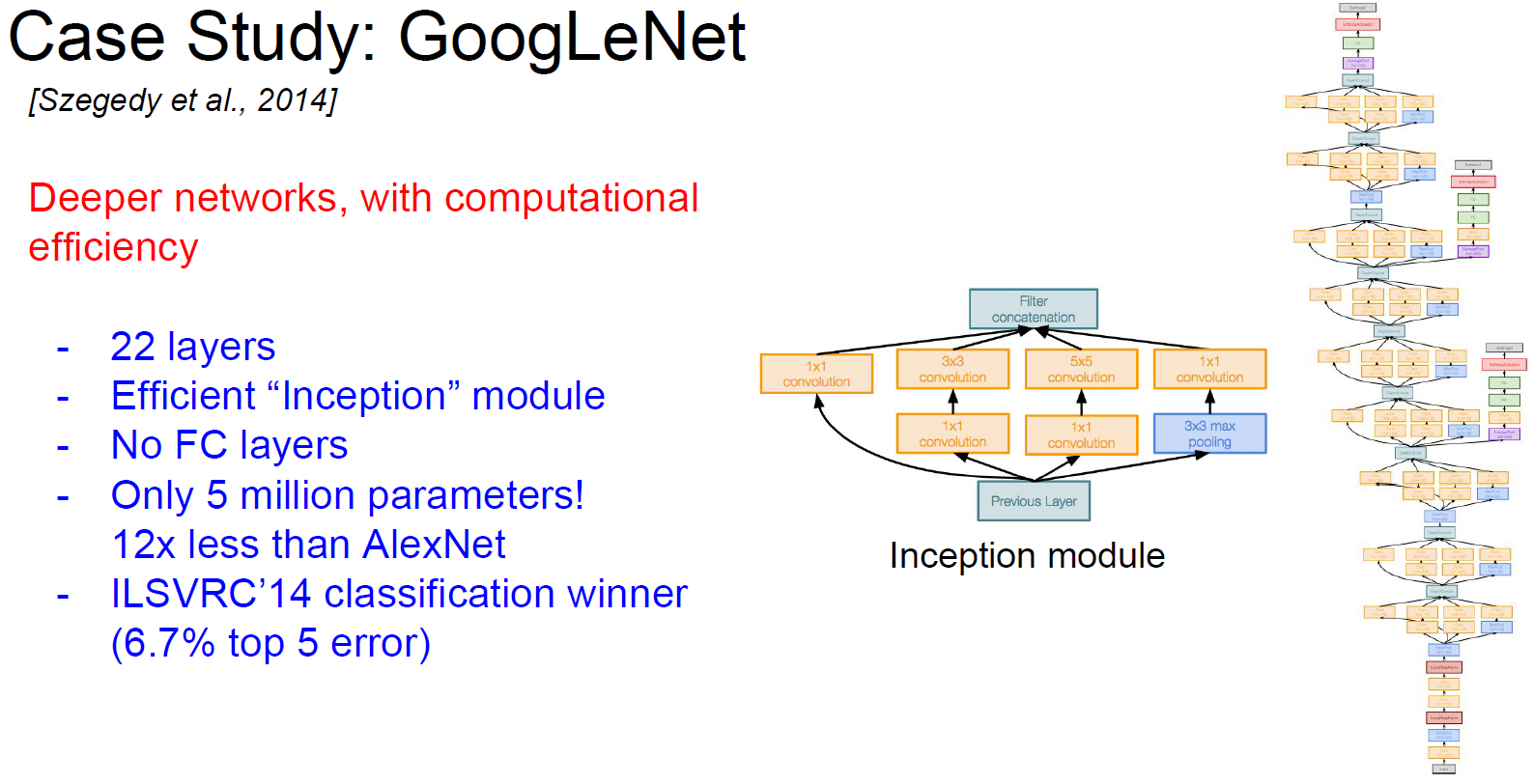
Inception module是同时用不同的filter(1*1,3*3,5*5,Pooling),并把结果堆叠起来。这样做的缺点是计算量变大。解决的办法是先用1*1的卷积压缩通道数量(参考《deeplearning.ai 卷积神经网络 Week 2 听课笔记》)。
4. ResNet(He et al., 2015),152层网络。
解决了很深的网络难优化的问题。
对于深度的网络(ResNet-50+),类似GoogLeNet用1*1的卷积层去压缩通道数以提高效率。

5. 复杂度的比较
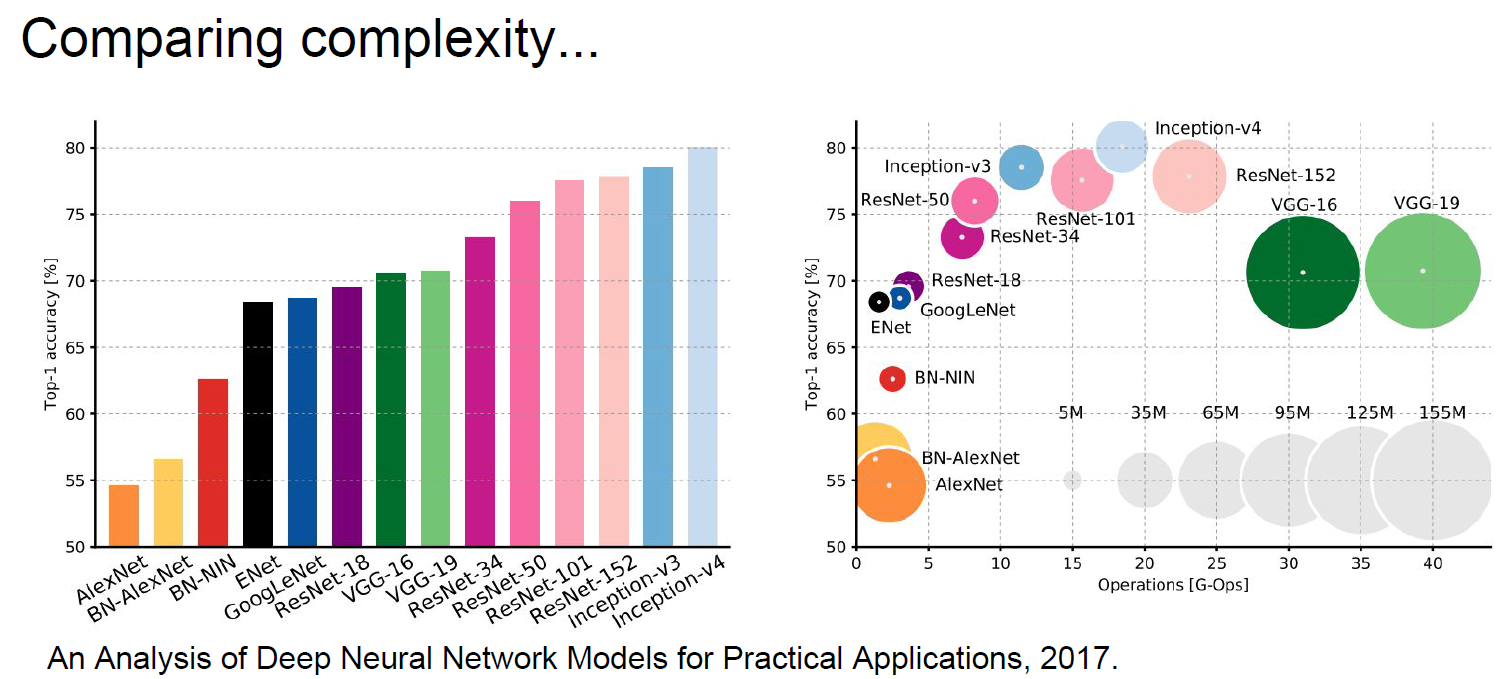
6. 其他一些网络
Network in Network (NiN)(Lin et al., 2014):启发了GoogLeNet和ResNet的“bottleneck”层(1*1卷积层)。
Identity Mappings in Deep Residual Networks (He et al., 2016):ResNet的改进。
Wide Residual Networks (Zagoruyko et al., 2016):认为residuals是很重要的,而不是深度。增加宽度而不是深度,会计算更有效。50层的宽的ResNet比152层的原始的ResNet更好。
ResNeXt (Xie et al., 2016):也是增加宽度,和Inception module很类似的想法。
Deep Networks with Stochastic Depth (Huang et al., 2016):为了解决梯度消失的问题,随机地drop掉一些层。在测试阶段使用全部的网络,不drop任何层。
FractalNet (Larsson et al., 2017):认为residual不是必须的,重要的是浅层到深层的有效传递(transitioning),训练阶段也是随机drop掉一些层,测试阶段不drop任何层。
Densely Connected Convolutional Networks (Huang et al., 2017):为了解决梯度消失的问题,每一层与其他层更稠密的连接。
SqueezeNet (Landola et al., 2017):更少的参数,更好的准确度。
7. 总结
VGG、GoogLeNet、ResNet被广泛应用,现在已经是集成到各个现成框架。
ResNet是当今最佳,默认选项。
趋势是越来越深的网络。
很多研究集中在设计层与层之间的连接方式,为了改善梯度的传播。
最新的研究在争论深度和宽度,以及residual的必要性。