一直对Fast RCNN中ROI Pooling层不解,不同大小的窗口输入怎么样才能得到同样大小的窗口输出呢,今天看到一篇博文讲得挺好的,摘录一下,方便查找。
Introduction
在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小(fixed-size)。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小。然而通常的手法就是裁剪(crop)和拉伸(warp)。

这样做总是不好的:图像的纵横比(ratio aspect) 和 输入图像的尺寸是被改变的。这样就会扭曲原始的图像。而Kaiming He在这里提出了一个SPP(Spatial Pyramid Pooling)层能很好的解决这样的问题, 但SPP通常连接在最后一层卷基层。

SPP 显著特点
1) 不管输入尺寸是怎样,SPP 可以产生固定大小的输出
2) 使用多个窗口(pooling window)
3) SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
其它特点
1) 由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting)
2) 实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence)
3) SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)
4) 不仅可以用于图像分类而且可以用来目标检测
使用SPP的CNN
Convolutional Layers and Feature Maps
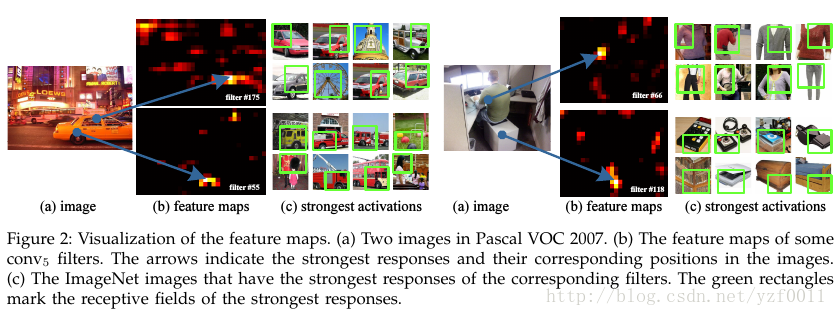
作者使用上图意在说明保留原图片的尺寸对实验的特征提取和结果都很重要
The Spatial Pyramid Pooling Layer

为什么会得固定大小的输出?
注意我们上面曾提到使用多个窗口(pooling窗口,上图中蓝色,青绿,银灰的窗口, 然后对feature maps 进行pooling,将分别得到的结果进行合并就会得到固定长度的输出), 这就是得到固定输出的秘密原因。
我们接下来用一个例子来弄懂这张图
Single-size network
我们先假定固定输入图像的尺寸s=224, 而此网络卷积层最后输出256层feature-maps, 且每个feature-map大小为13×13(a=13),全连接层总共256×(9+4+1)个神经元, 即输全连接层输入大小为256×(9+4+1)。即我们需要在每个feature-map得到一个数目为(f=9+4+1)的特征。
由于pooling窗口(w×ww×w)很明显如果我们用一个pooling窗口怎么也很难得到f=9+4+1,再加上如果输入图像尺度变化的话,是根本不可能。
这里用了3个pooling窗口(w×w), 而对应的pooling stride 为t, 经多这3个窗口pooling池化得到3个n×n,n=3,2,1的结果。
饼画好了,怎么得到我们的窗口大小w和stride t呢?
n=2,n=1以此类推,将3个pooling后的结果合并,很容易发现和我们的期望一致。

muti-size training(证明其可能性)
有这一公理以及其推理:
公理: 任何一个数都可以写成若干个数的平方和。
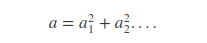
推理: 任何一个数的平方(为一个数)可以表达成若干个数的平方和

由于我们的输入图像尺寸是多样的,致使我们在最后一层得到的每个featrue-map大小为a×b(a 和 b大小是可变的)且feature-maps数为c,我们全连接层的输入为c×f, 也就是我们每个feature-map 要得到f个特征。
由公理可得
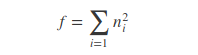

SPP分类
作者在分类的时候得到如下几个结果
1) 多窗口的pooling会提高实验的准确率
2) 输入同一图像的不同尺寸,会提高实验准确率(从尺度空间来看,提高了尺度不变性(scale invariance))
3) 用了多View(multi-view)来测试,也提高了测试结果
4)图像输入的尺寸对实验的结果是有影响的(因为目标特征区域有大有有小)
5)因为我们替代的是网络的Poooling层,对整个网络结构没有影响,所以可以使得整个网络可以正常训练。
SPP目标检测
是基于RCNN而改进的,现在有比其更快的Fast-RCNN, 和Faster-RCNN。我们在这里主要提出论文中的重要的点。
1) 在目标检测中,许多实验可以从feature-maps中使用窗口,来提取目标特征。见原文描述:
regions of the feature maps, while R-CNN extracts directly from image regions. In previous works, the Deformable Part Model (DPM) [23] extracts features from windows in HOG [24] feature maps, and the Selective Search (SS) method [20] extracts from win- dows in encoded SIFT feature maps. The Overfeat detection method [5] also extracts from windows of deep convolutional feature maps, but needs to pre- define the window size. On the contrary, our method enables feature extraction in arbitrary windows from the deep convolutional feature maps.
2)接下来分析目标检测的整体过程:
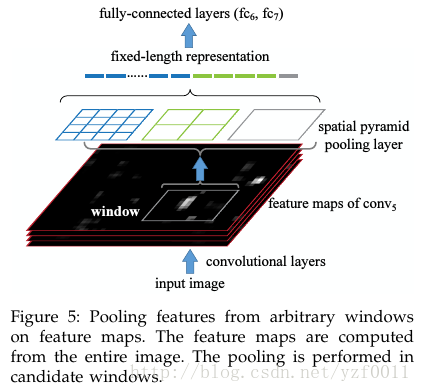
从上面的描述,我们应该懂了作者的意思。作者是整体先对整张图片进行卷积然后,在把其中的目标窗口拿出来Pooling,得到的结果用作全连接层的输入。
特点:只需要计算一次卷积层,训练速度快。
文章转自: https://blog.csdn.net/yzf0011/article/details/75212513