一、axis
Pandas保持了Numpy对关键字axis的用法,用法在Numpy库的词汇表当中有过解释:
轴用来为超过一维的数组定义的属性,二维数据拥有两个轴:第0轴沿着行的方向垂直往下,第1轴沿着列的方向水平延伸。如果简单点来说,就是0轴匹配的是index, 涉及上下运算;1轴匹配的是columns, 涉及左右运算。
二、读取数据
根据文件类型,选择不同的函数
pandas.read_csv('file_path', skiprows=n)
pandas.read_excel('file_path', skiprows=n)
pandas.read_json('file_path', skiprows=n)
pandas.read_csv('file_path', skiprows=n)
pandas.read_sql('file_path')
三、两种数据类型,Series和DataFrame
从DataFrame中获取某一行还是某一列的Series
1、获取某一列。两种方法,对象方法( . )和字典key-value式( [ ] )。加点方法比较方便,但是如果字段含有空格则不方便使用,这时必须用第二种中括号方法了。
food_info = pd.read_csv('food_info.csv') food_info.head() food_info.NDB_No food_info['NDB_No']
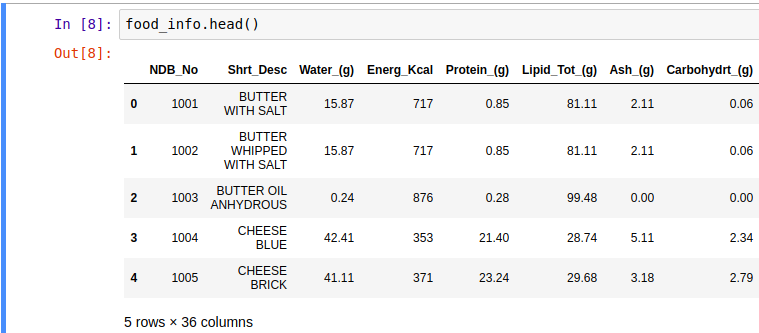
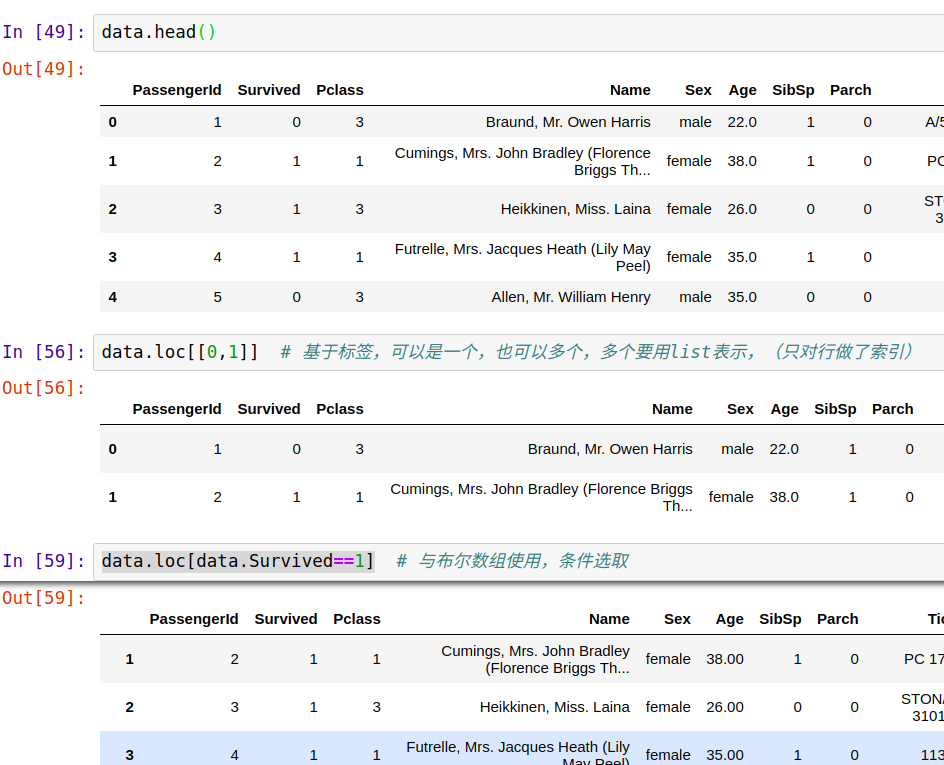
2、获取某行或者某行某列,iloc/loc。loc[ 1 ]索引时严格按照索引值匹配,即如果索引index是 ['a', 'b', 'c'],用loc索引时,如果要索引‘b’所在行,必须写为loc[ 'b' ],但iloc[ ]任何时候都可以用数据索引,表示索引第几行。

food_info.iloc[0]
3、获取子DataFrame,即选取某几列或者几行,两个中括号:【【 】】
选取多列
food_info[['NDB_No','Water_(g)']]
选取多行 loc()/iloc()
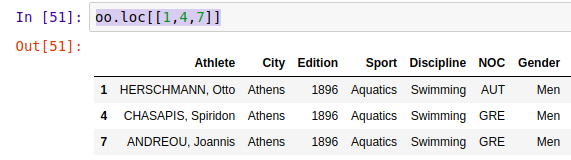
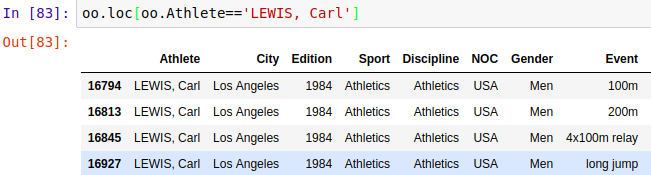
选取连续多行
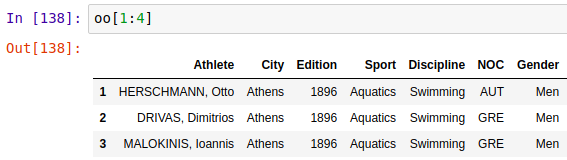
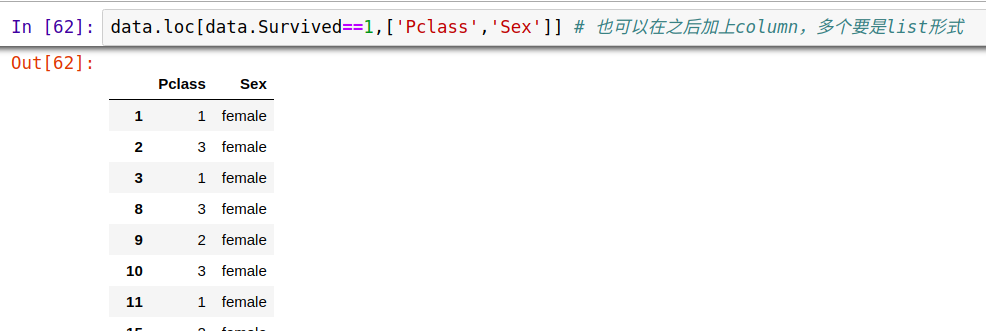
4. pd.Dataframe.loc()索引方法主要基于标签,但也可以与布尔数组一起使用。
5、对于一个dataframe,我们可以通过某行某列来定位到某个值,df.iloc[row, column],那如果知道某个值,如何通过全表扫描找到它的定位呢。这里要借助numpy.where
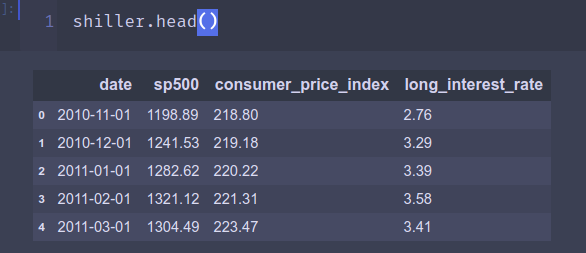
比如对于上面这个dataframe shiller, 想要在表中找到1282.62的定位,就可以用np.where,得到的结果是一个元祖(行,列),当要判断是否有知识,可用.size来判断,如下用location[0].size是否大于0来判断是否找到。

四、常用属性和方法
1、shape属性,读取数据框行列值

2、head()/tail(),查看前几行或后几行,可带参数制定查看几行。
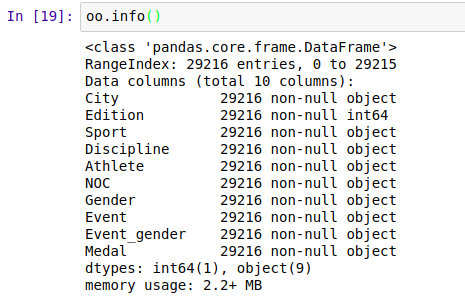
` 3、info(),查看数据的基本信息,有几行几列,每一列的数据类型是什么,有没有缺失的数据,数据所占内存空间大小等等。
五、基本数据分析
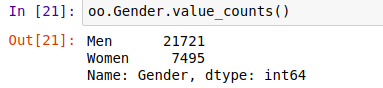
1、数据频率统计:
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
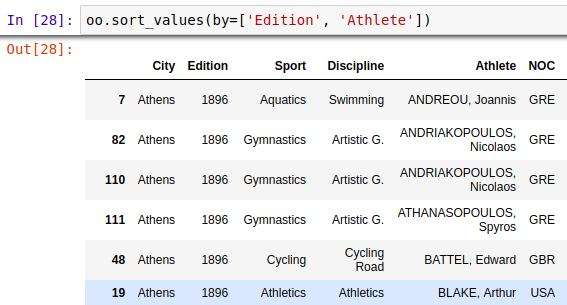
2、数据排序
Series.sort_values(axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
可见,对序列和数据框都可以进行排序,对数据框排序可以有多个优先等级排序条件
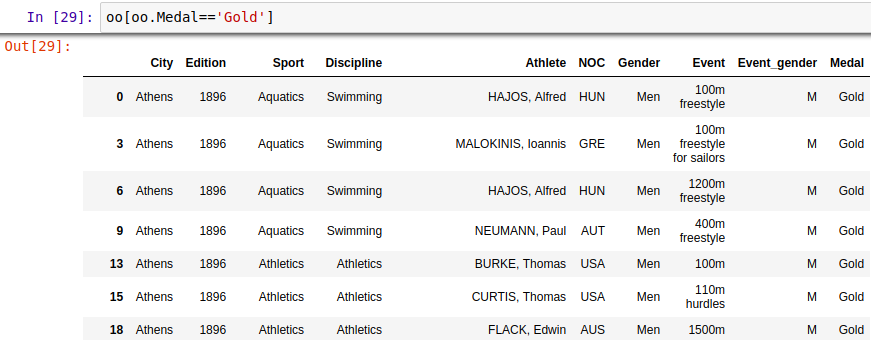
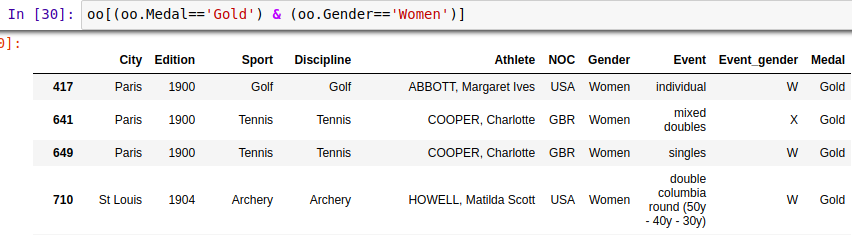
3、布尔值索引快速刷选数据
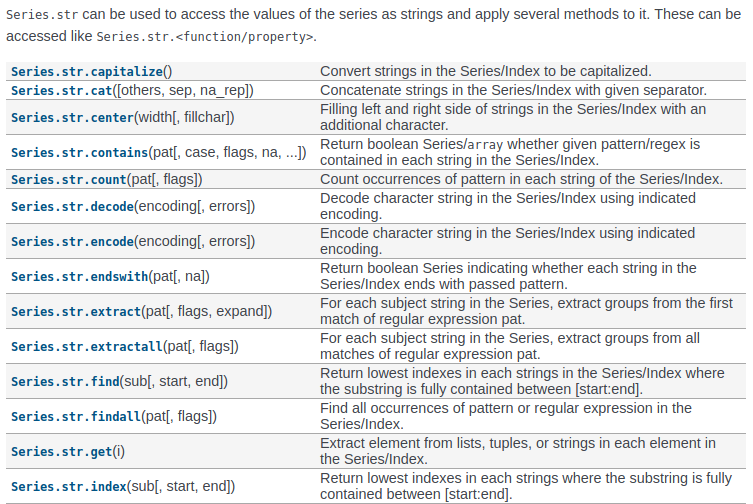
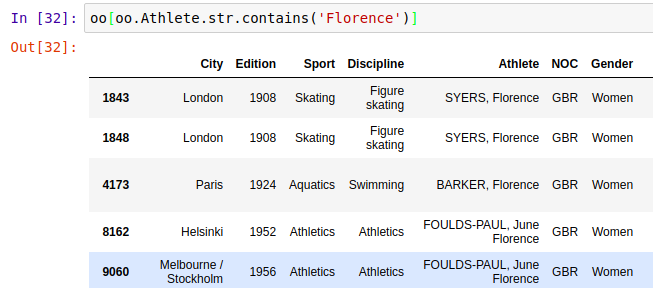
4、字符串处理——模糊查询(不止以下方法)
5、处理缺失数据
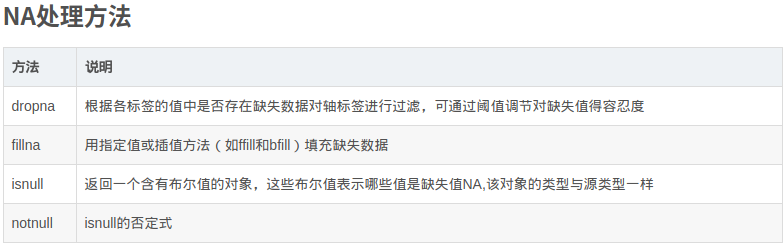
滤除缺失数据(dropna)
Series
In [1]: import pandas as pd In [2]: from pandas import DataFrame, Series In [3]: import numpy as np In [4]: from numpy import nan as NA In [5]: data = Series([1, NA, 3.5, NA, 7]) In [6]: data.dropna() Out[6]: 0 1.0 2 3.5 4 7.0 dtype: float64 In [7]: data[data.notnull()] Out[7]: 0 1.0 2 3.5 4 7.0 dtype: float64
DataFrame
-
DataFrame中dropna默认丢弃任何含有缺失值的行。
- 空值:在pandas中的空值是""
- 缺失值:在dataframe中为nan或者naT(缺失时间),在series中为none或者nan即可
-
传入how=’all’将只丢弃全为NA的行
-
如果想丢弃列,只需传入axis=1
填充缺失数据(fillna)!!
- 常数调用
df.fillna(0) - 字典调用,对不同的列填充不同的值
df.fillna({1:0.5, 3:-1}) - fillna默认会返回新对象!!,就地修改:
_ = df.fillna(0, inplace=True) - 对
reindex有效的插值方法也可用于fillna
替换值
利用fillna方法填充缺失数据可以看做值替换的一种特殊情况。而replace则提供了一种实现该功能的更简单、更灵活的方式。
In [11]: data = Series([1.,-999.,2.,-999.,-1000.,3.]) In [12]: data Out[12]: 0 1.0 1 -999.0 2 2.0 3 -999.0 4 -1000.0 5 3.0 dtype: float64 In [13]: data.replace(-999, np.nan) Out[13]: 0 1.0 1 NaN 2 2.0 3 NaN 4 -1000.0 5 3.0 dtype: float64 In [14]: data.replace([-999,-1000], np.nan) Out[14]: 0 1.0 1 NaN 2 2.0 3 NaN 4 NaN 5 3.0 dtype: float64 In [15]: data.replace([-999,-1000], [np.nan,0]) Out[15]: 0 1.0 1 NaN 2 2.0 3 NaN 4 0.0 5 3.0 dtype: float64 In [16]: data.replace({-999 : np.nan, -1000 : 0}) Out[16]: 0 1.0 1 NaN 2 2.0 3 NaN 4 0.0 5 3.0 dtype: float64
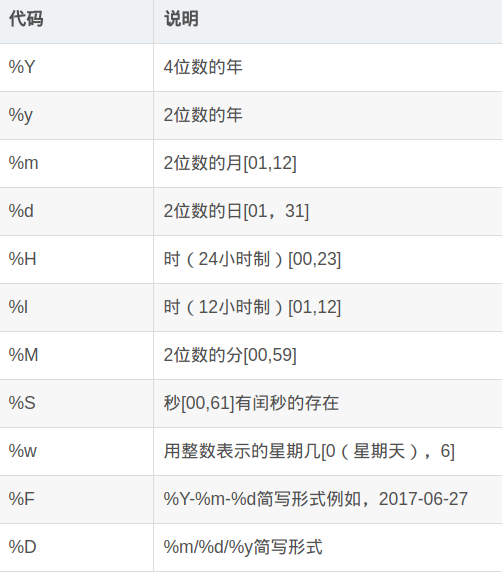
6、快速处理date_time日期格式
当数据很多,且日期格式不标准时的时候,如果pandas.to_datetime 函数使用不当,会使得处理时间变得很长,提升速度的关键在于format的使用。
示例数据:
date 格式:02.01.2013 即 日.月.年
数据量:3000000
transcation.head() --------------------------------------------- date date_block_num shop_id item_id item_price item_cnt_day 0 02.01.2013 0 59 22154 999.00 1.0 1 03.01.2013 0 25 2552 899.00 1.0 2 05.01.2013 0 25 2552 899.00 -1.0 3 06.01.2013 0 25 2554 1709.05 1.0 4 15.01.2013 0 25 2555 1099.00 1.0
处理方式一:
transactions['date_formatted'] = pd.to_datetime(transactions['date']) # 处理时间: 10min
处理方式二:
transactions['date_formatted'] = pd.to_datetime(transactions['date'], format='%d.%m.%Y') # 处理时间:10s
# 变成标准格式 transcation.head() --------------------------------------------- date date_block_num shop_id item_id item_price item_cnt_day 0 2013-01-02 0 59 22154 999.00 1.0 1 2013-01-03 0 25 2552 899.00 1.0 2 2013-01-05 0 25 2552 899.00 -1.0 3 2013-01-06 0 25 2554 1709.05 1.0 4 2013-01-15 0 25 2555 1099.00 1.0
附录:format相关
五、索引(indexing)
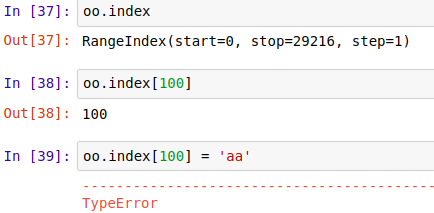
1、原索引值不可更改
2、set_index() 方法重新设定全部索引
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
其中,inplace为False时,不会改变元数据的index,如果为True,则改变。keys可以时columns标签,也可以是给定的list。
oo.set_index('Athlete', inplace=True)
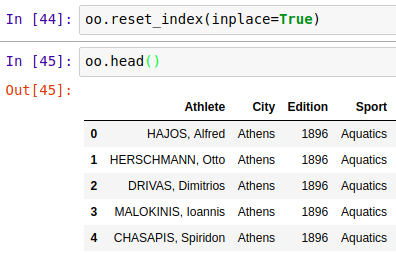
3、索引复位,reset_index()
4、按索引排序数据
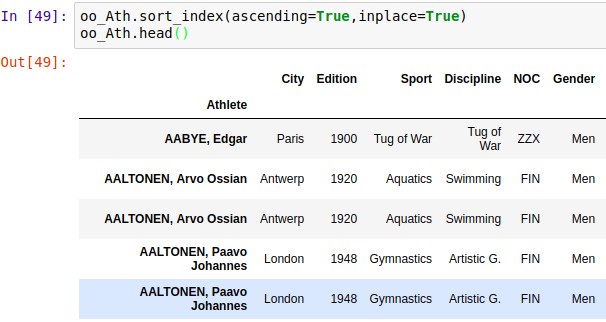
六、数据分组
1、groupby( ) 方法,可以按某列进行分组,然后对每一种情况进行分析,比如对性别分组,分成男女两组,然后分别对男女数据进行分析,可以存到list列表里,这样每一组值以tuple的方式存入list中,也可以用
for循环遍历,分组和得到的仍然是DataFrame.
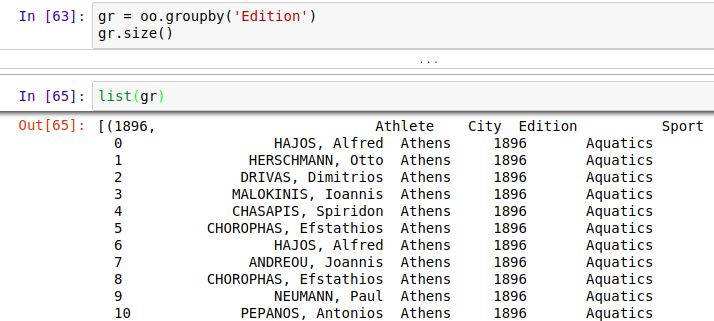
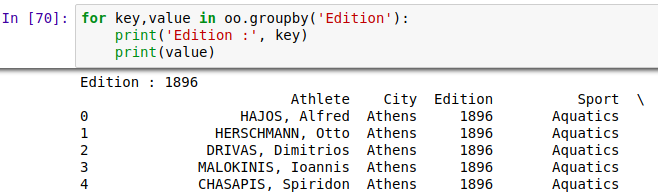
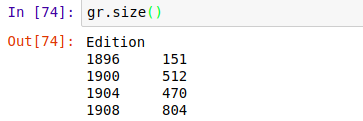
2、分组数据常用操作
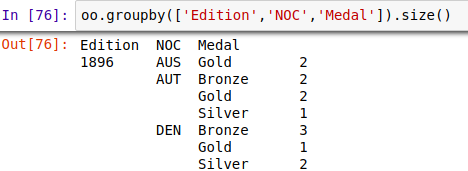
a、size()查看分组后的统计结果
b、按照多重条件分组,并统计分析,看着比较直观,有对比性
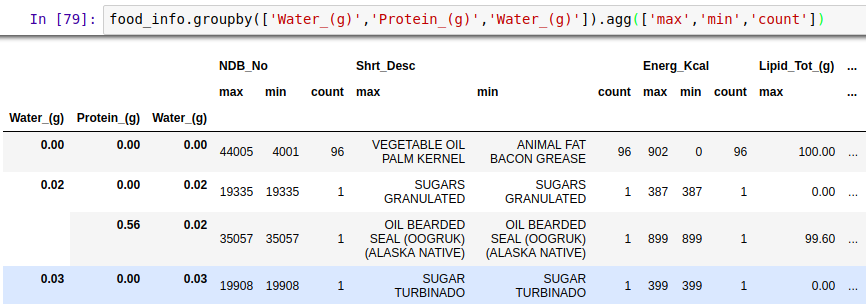
也可在聚合函数中制定对某一项或几项进行统计分析,用字典的形式。

七、数据重塑
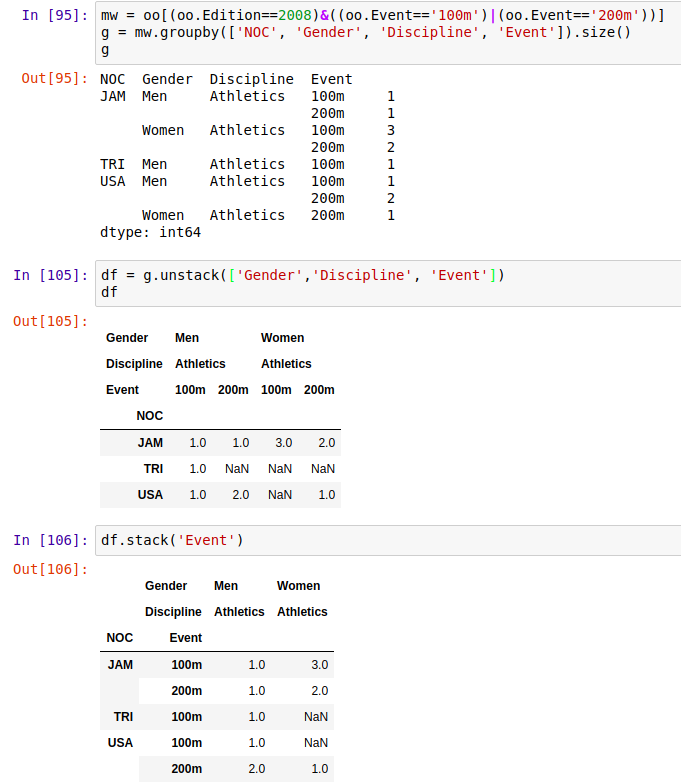
1、stack() 把某些行变成列,使得数据更加集中
unstack() 把某些列变成行,使得数据更加扁平化
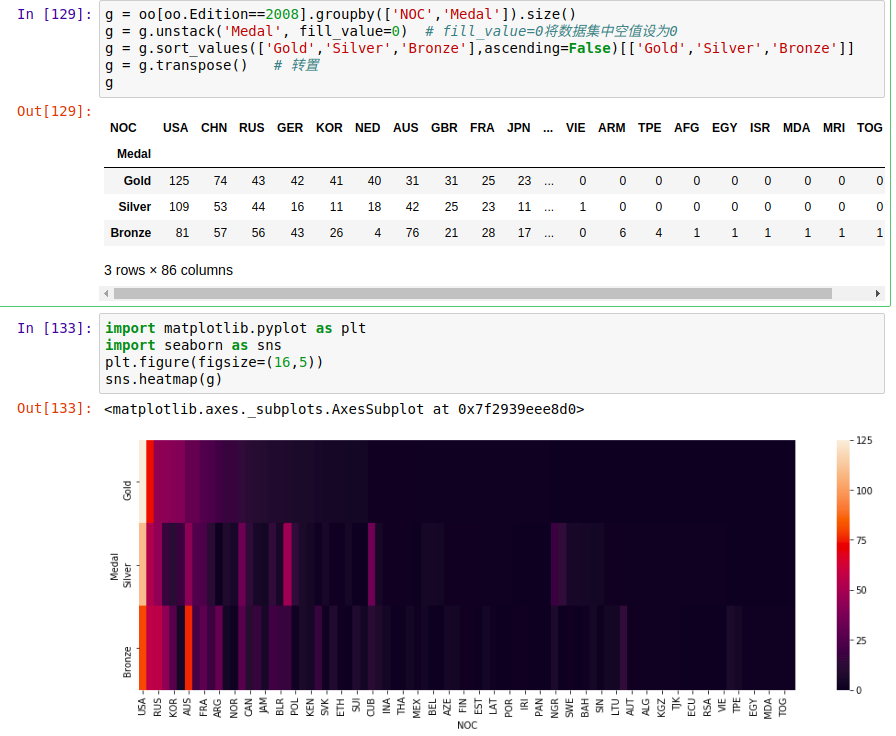
2、实战,统计2008奥运会所有参加国家的奖牌数
八、apply函数
运用apply(function)函数可以批量处理某一个操作,使用时只需传入函数名即可,函数可以时自定义的function函数。这在数据清理时可以很灵活。
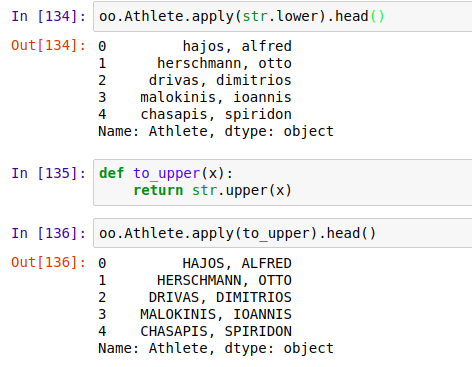
apply,applymap 和map的区别
- apply() 和applymap()是DataFrame数据类型的函数,map()是Series数据类型的函数。
- apply()的操作对象DataFrame的一列或者一行数据, applymap()是element-wise的,作用于每个DataFrame的每个数据。 map()也是element-wise的,对Series中的每个数据调用一次函数。
- * apply works on a row / column basis of a DataFrame, applymap works element-wise on a DataFrame, and map works element-wise on a Series.
九、多表操作
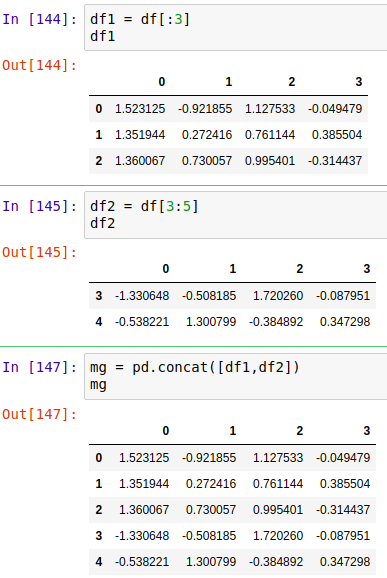
1、数据多表合并------concat() ======= 使用较少
pandas.concat(objs, axis=0) 默认沿着y轴方向合并,合并时根据情况选择不同的坐标方向合并。
2、merge( ) 方法
pd.merge(left, right, how='inner', left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
how决定采用不同的合并方式,为inner时取left和right的交集显示,其余部分抛弃;how=‘left’时,只取left的全部数据;how= ‘right’,只取right的全部数据;how='outer',保留两个表的所有数据,外连接。
通过设置merge参数'on','left_on','right_on'可以指定用来连接的列(即关键的重复内容列),也可以将index作为连接键,只要传入left_index=True或right_index=True(或两个都传)来说明索引被用作连接键
left1 = DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],
'value': range(6)})
right1 = DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])
lr=pd.merge(left1, right1, left_on='key', right_index=True)
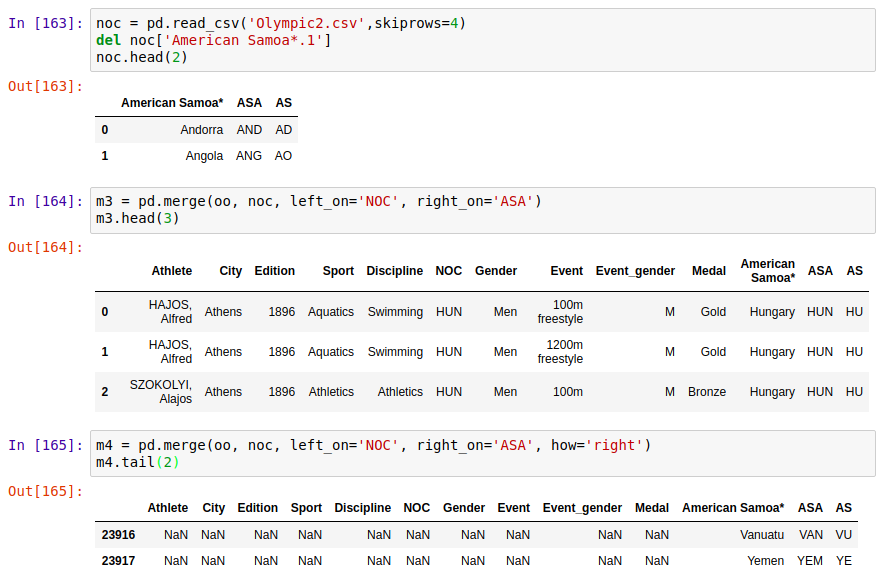
也可以把参照字段改成同样的名字,这样就不用分left_on和right_on了,直接使用on。

3、join()
实例方法join默认通过index来进行连接,也可以通过列来连接,同样设置参数‘on’即可
left2 = DataFrame([[1., 2.], [3., 4.], [5., 6.]], index=['a', 'c', 'e'], columns=['Ohio', 'Nevada']) right2 = DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]], index=['b', 'c', 'd', 'e'], columns=['Missouri', 'Alabama']) lr2=left2.join(right2, how='outer')
十、问题锦集
1、在Windows下使用pandas.read_csv()读取csv文件,注意当csv文件命名为中文时,会报错如下:
pandas_libsparsers.pyx in pandas._libs.parsers.TextReader.cinit() pandas_libsparsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source() OSError: Initializing from file failed
这时候把csv文件名换成英文就可以读取了,可能对中文不支持吧