由于spring cloud中涉及的组件比较多,东西比较杂。所以此文主要记录的是一些使用中的关键点,以便日后翻阅查看。
一、spring cloud是什么
spring cloud是基于spring boot实现的一系列框架的有序集合。为微服务提供了一整套解决方案。
二、在线资源
官网:https://spring.io/projects/spring-cloud
中文网:https://www.springcloud.cc/
三、版本号
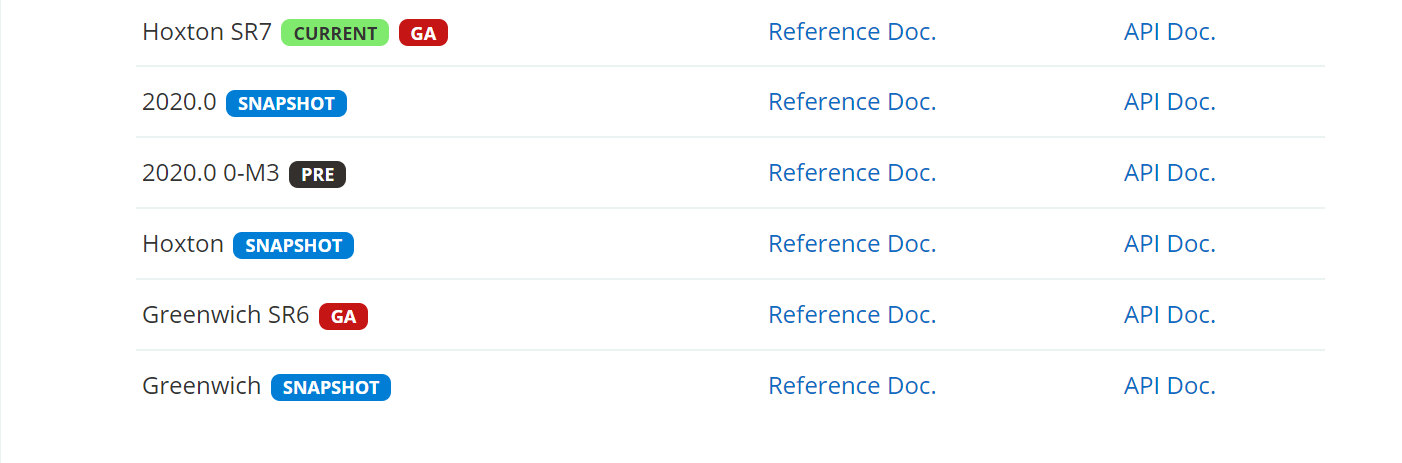
Spring Cloud 的版本号并不是我们通常见的数字版本号,而是一些很奇怪的单词。这些单词均为英国伦敦地铁站的站名。同时根据字母表的顺序来对应版本时间顺序。
● SNAPSHOP:快照版,可以使用,但其仍处理连续不断的开发改进中,不建议使用。
● M:里程碑版。其也会标注上 PRE,preview,预览版,内测版,不建议使用。
● RC:Release Candidate,发行候选版,主要是用于修复 BUG,一般该版本中不会再添加大的功能修改了。 正式发行前的版本。
● SR:Service Release,服务发行版,正式发行版。一般还会被标注上 GA,General Available 。
四、新建两个基础项目
基于RestTemplate新建两个基础项目备用:Consumer、Provider。实现数据库对象Depart的基本CRUD功能。
五、CAP定理
一致性:分布式各主机之间数据保持一致
可用性:系统服务一直可用(可用指的是在有限的时间内对用户做出响应)
分区容错性:当系统出现网络故障时能够对外正常提供一致性和可用性的服务。
Eureka是AP、zk是CP。
六、注册中心Eureka
架构图
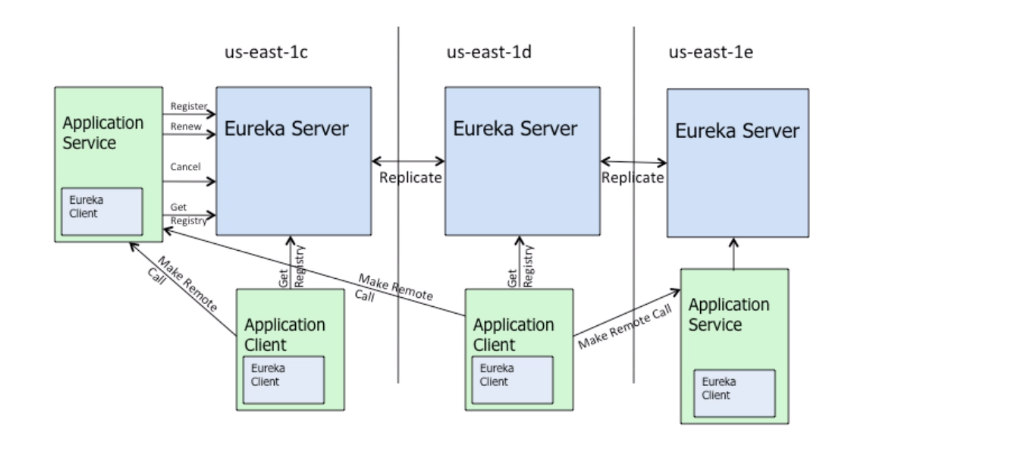
说明:
①服务提供者和服务调用者相对于Eureka Server来说都叫Eureka Client。
②Eureka Client每隔30s会向Eureka Server中发送一次心跳,拉取最新服务注册表。
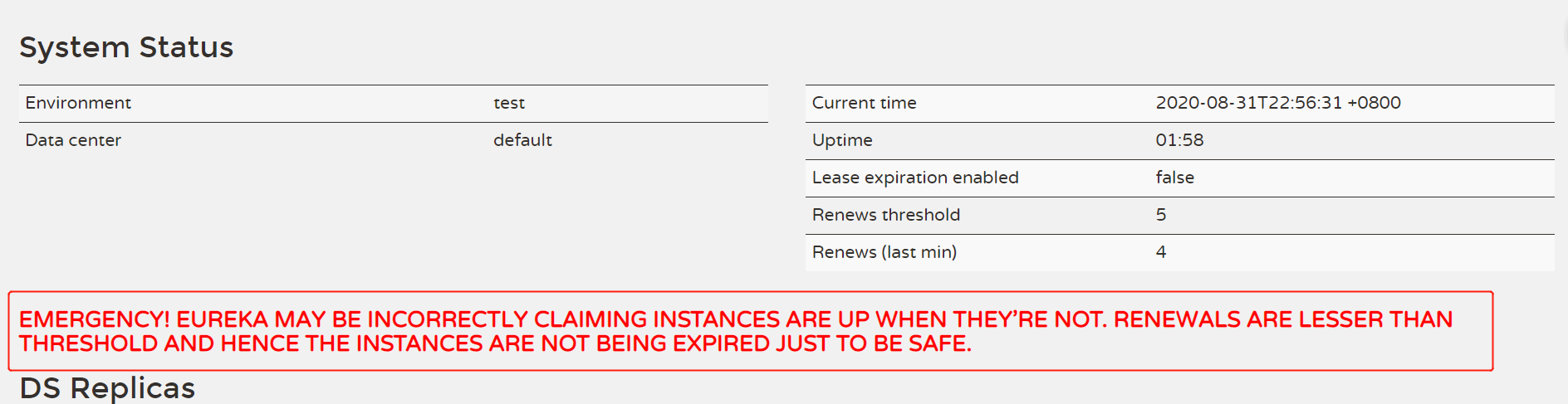
由于是每30s进行一次心跳。所以在这30s之间,有新的服务注册了或者旧的服务下架了,会造成三种可能:一可能有的Client是无法及时感知到服务变化;二可能会存在client之间数据不一致;三Eureka Server之间的数据不一致。因为Eureka是AP的,这是可以接受的,其次这个时间是较短的。
定义Eureka-server
pom.xml
<properties>
<java.version>1.8</java.version>
<maven-jar-plugin.version>3.1.1</maven-jar-plugin.version>
<mysql.version>5.1.47</mysql.version>
<!-- 指定spring cloud版本号 -->
<spring-cloud.version>Hoxton.SR1</spring-cloud.version>
</properties>
<!-- Eureka服务端依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<!-- 指定为spring cloud工程-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
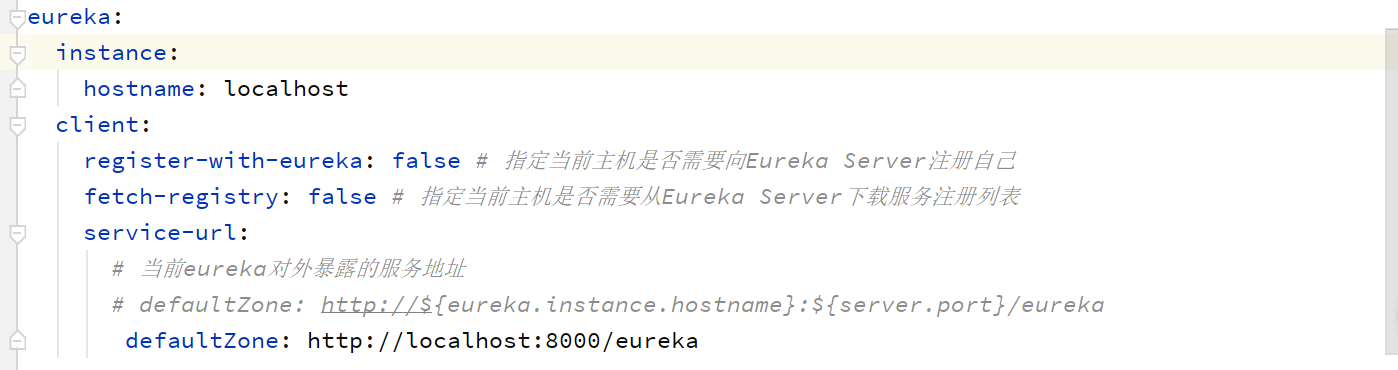
Eureka的基本配置:
在启动类上添加@EnableEurekaServer注解

定义Provider-Eureka
pom.xml
<properties>
<java.version>1.8</java.version>
<maven-jar-plugin.version>3.1.1</maven-jar-plugin.version>
<mysql.version>5.1.47</mysql.version>
<!-- 指定spring cloud版本号 -->
<spring-cloud.version>Hoxton.SR1</spring-cloud.version>
</properties>
<!-- Eureka客户端依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!-- 指定为spring cloud工程-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
简单配置:

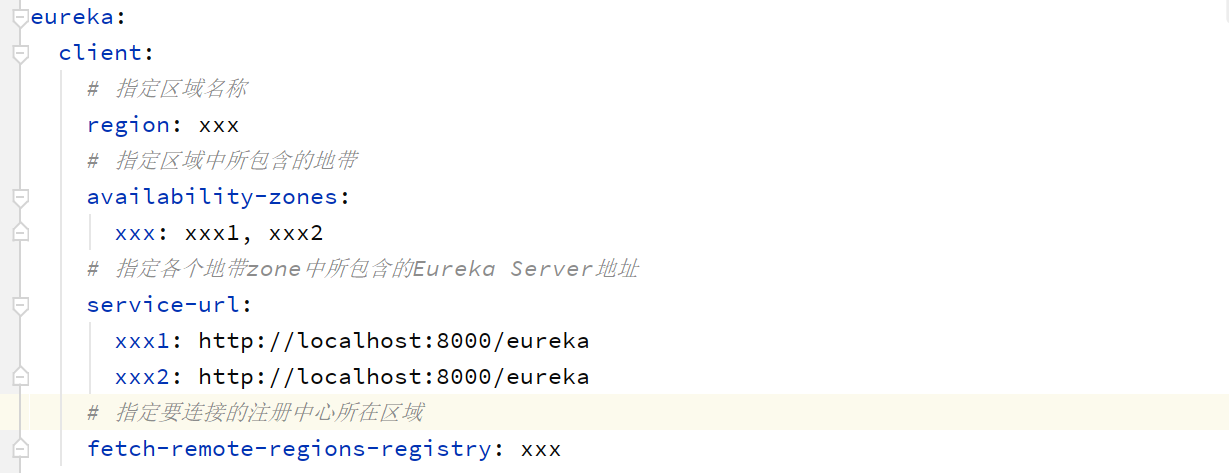
复杂配置:
定义Consumer-Eureka
①配置同Provider-Eureka
②修改controller调用地址为提供者的微服务名称
③RestTemplate使用@LoadBalance
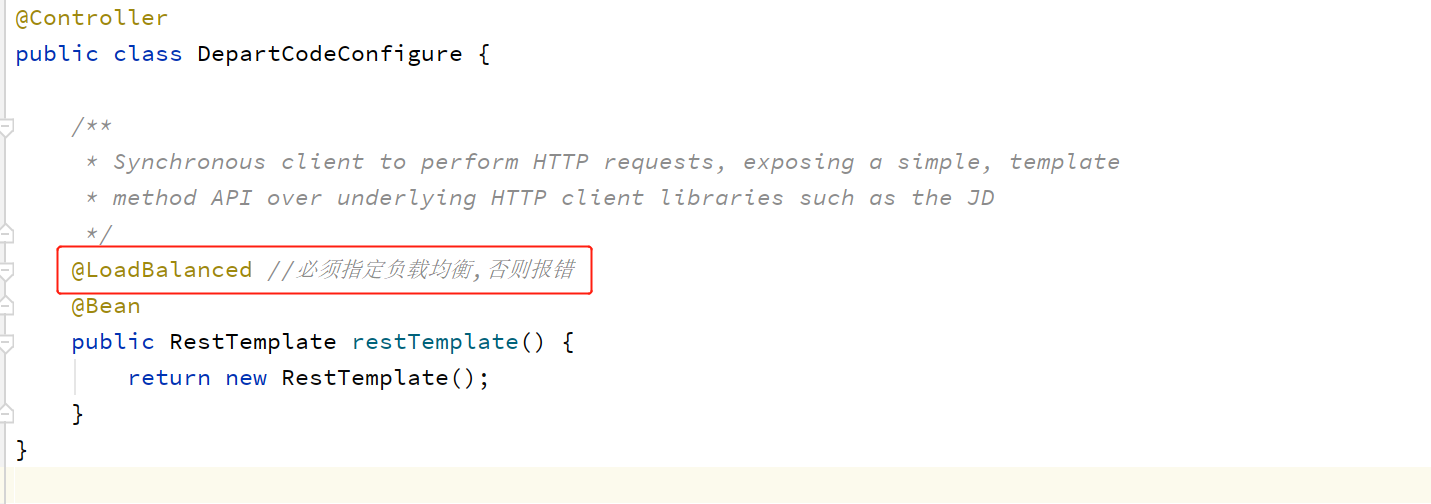

自我保护机制
默认是0.85,即85%。表示EurekaServer收到的心跳数量若小于应该收到数量的85%时,会启动自我保护机制,服务就不会下线。不建议关闭自我保护机制。

配置参考类
EurekaClientConfigBean.java
EurekaServerConfigBean.java
EurekaInstanceConfigBean.java
服务离线
服务下架:Eureka Client从Eureka Server注册表中移除。
服务下线:Eureka Client并没有从Eureka Server注册表中移除,其他Client仍可发现该服务,只是服务状态为“DOWN”不可用。正常状态为“UP”
如何实现:借助actuator监控器实现。

方式一:shutdown(服务直接下线)
post请求:http://localhost:8081/actuator/shutdown
这种方式直接向后台应用发送了一个关闭的命令,服务提供者进程直接停掉。
方式二:service-registry(服务平滑下线)
post请求:http://localhost:8081/actuator/service-registry
请求体:
{
"status":"DOWN"
}

这种方式,服务提供者进程并未直接停掉,但是服务调用者已经无法通过Eureka调用到服务了。
报错:"message": "No instances available for abcmsc-provider-depart",
集群搭建
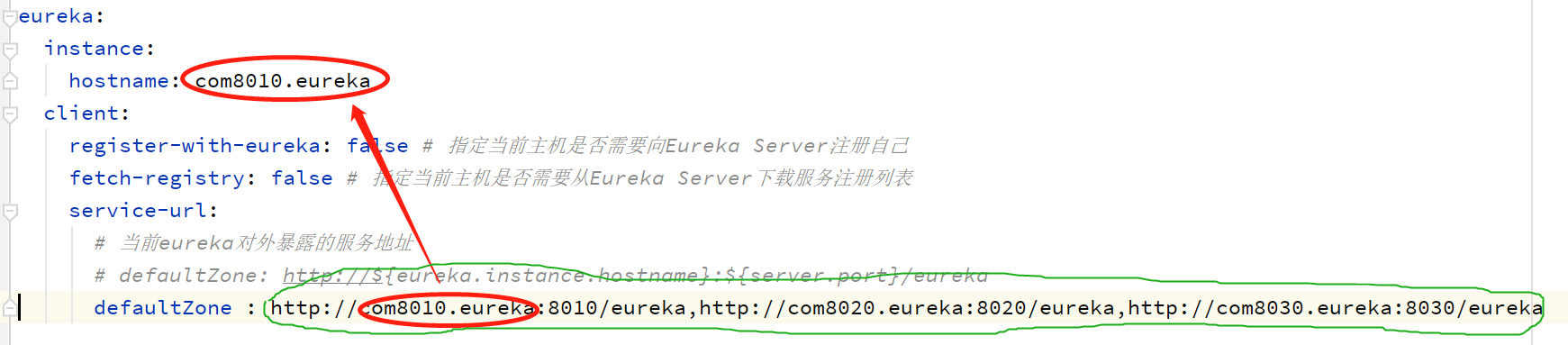
hostname是可选的。如果更改了就得相应的更改本地的hosts文件


七、OpenFeign和Ribbon
Feign测试
添加依赖
<!-- openfeign依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
定义声明式客户端:使用feign接口对restTemplate进行替换。
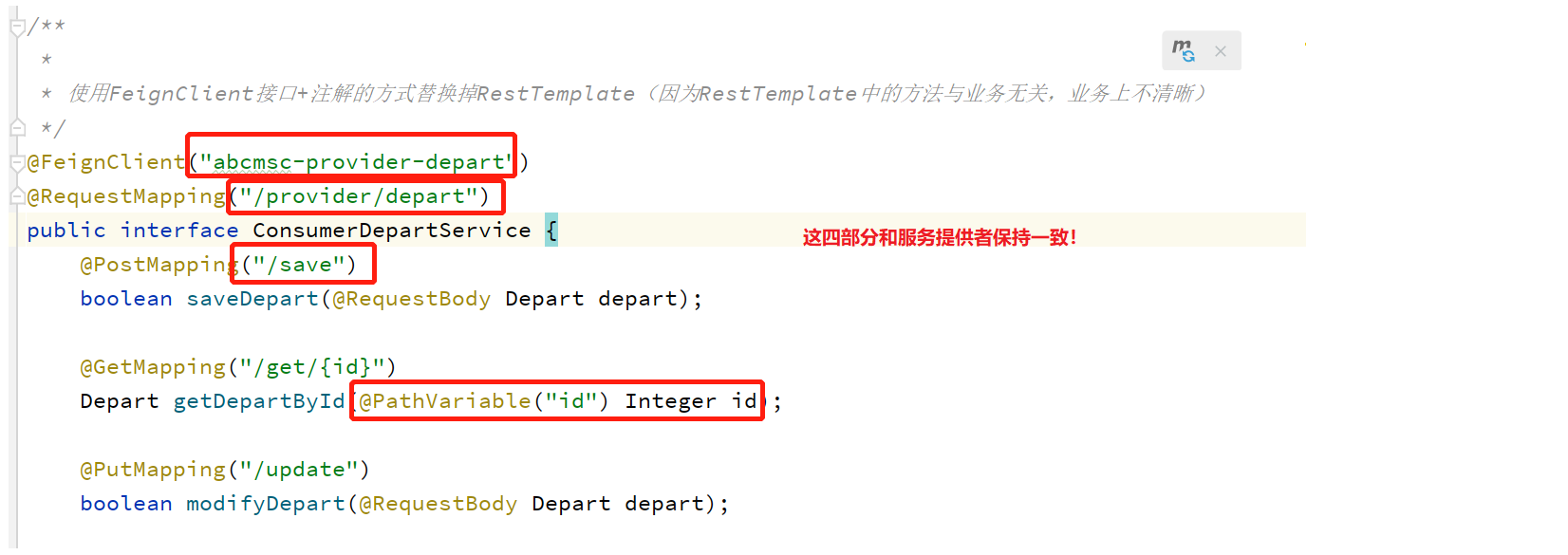
修改controller:

启动类:

其他配置(超时时间、请求/响应压缩等等)
可参考:https://docs.spring.io/spring-cloud-openfeign/docs/2.2.4.RELEASE/reference/html/

集群搭建
复制三份provider,看feign客户端(本质是基于ribbon)是否能够轮询负载。默认是轮询算法。
注意:eureka.instance-id不要一样了。否则只会看到一个服务提供者。

负载均衡
负载均衡有轮询、随机、重试时间、最可用、权重等等。默认采用轮询算法。可通过如下方式修改负载均衡算法:
方式一:配置文件

方式二:代码注入(优先级高)

自定义:当然我们也可以自定义算法。只需要实现IRule接口即可。实现以下三个方法。

例如:我们自定义一个算法,负载策略是随机选择端口号为奇数的服务提供者。
public class CustomRule implements IRule {
private ILoadBalancer lb;
@Override
// 参数key表示进行负载均衡时的一些外部条件,一般都为null
public Server choose(Object key) {
List<Server> availableServers = getAvailableServers(getLoadBalancer());
// 从可用的Server列表中随机获取一个
int index = new Random().nextInt(availableServers.size());
return availableServers.get(index);
}
// 获取所有可用的Server
private List<Server> getAvailableServers(ILoadBalancer lb) {
// 获取所有状态为“UP”的Server
List<Server> reachableServers = lb.getReachableServers();
List<Server> oddPortServers = new ArrayList<Server>();
// 过滤出所有端口号为奇数的Server
for (Server server: reachableServers) {
if(server.getPort()%2 == 1) {
oddPortServers.add(server);
}
}
return oddPortServers;
}
@Override
public void setLoadBalancer(ILoadBalancer lb) {
this.lb = lb;
}
@Override
public ILoadBalancer getLoadBalancer() {
return lb;
}
}
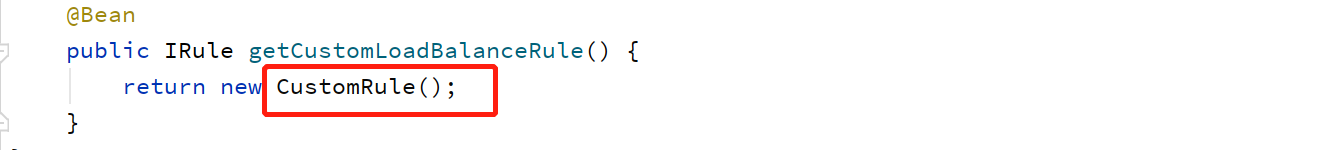
八、Hystrix服务熔断和服务降级
服务熔断:服务提供者关闭。404,用户体验不好。保险丝。
服务降级:服务降级是请求发生问题后一种增强用户体验的方式。返回一个用户可以接受的结果,但不是用户期望的结果。停电应急灯。
Spring Cloud是通过Hystrix来实现服务熔断与降级的。且都是在客户端实现的。
服务降级实现
分为方法级别和类级别。如果两者都存在,类级别的优先级更高一些。
方法级别降级实现
添加 Hystrix 依赖
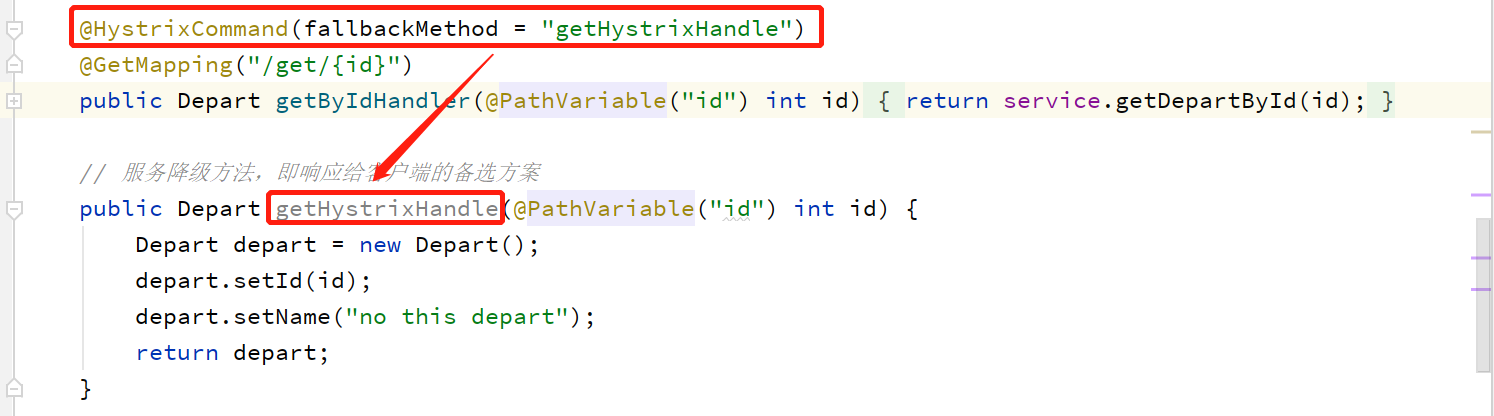
修改处理器方法。在处理器方法上添加@HystrixCommond 注解
在处理器中定义服务降级方法
在启动类上添加@EnableCircuitBreaker 注解(或将@SpringBootApplication 注解替换为
@SpringCloudApplication 注解,因为@SpringCloudApplication中包含了@EnableCircuitBreaker )
①添加依赖
<!--hystrix依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
②在处理器中定义降级方法
③修改启动类注解


类级别降级实现(两种方式)
添加 Hystrix 依赖
定义服务降级类
在 Feign 接口中指定服务降级类
修改配置文件,开启 Feign 对 Hystrix 的支持
在启动类上添加@EnableCircuitBreaker 注解(或将@SpringBootApplication 注解替换为
@SpringCloudApplication 注解)
添加pom依赖、修改启动类注解和上面一样,下面只说明不一样的地方。
A:使用fallbackFactory
①定义降级类,实现FallbackFactory接口,泛型为对应降级接口(声明一点:这里的降级接口使用的OpenFeign接口,但是降级和OpenFeign其实是没有必然联系的,完全可以对普通的处理器以同样的方式进行降级。只是通常情况下的做法Hystrix和Feign都同时存在)。降级类使用@Component交给Spring容器。

降级类重写所有的业务方法,这里以getDepartById方法为例:

②在Feign接口上声明降级类

③配置文件。开启feign对hystrix的支持,默认是false。

B:使用fallback
①定义降级类,实现对应降级接口。指定请求路径为/fallback+原路径

②在Feign接口上声明降级类

③配置文件,同上。
隔离策略
以上我们可以通过关闭服务提供者演示服务降级的效果,这个时候降级的是所有请求,真实环境中当然不是这样,应该是按需降级。真实的场景是:大量请求在短时间内到达服务器,超过了服务器的承受范围,需要对部分请求进行降级处理(即隔离部分请求)。
Hystrix中有两种隔离策略:线程隔离、信号量隔离。默认是线程隔离。
如何选择呢?高并发下应该用信号量隔离,因为相对来说:线程的数量是有限的。
隔离策略的设置

HystrixCommandProperties可以查看默认值:
 隔离其他属性
隔离其他属性
以下配置可参考:https://github.com/Netflix/Hystrix/wiki/Configuration
(1)线程执行超时时限
首先得开启超时开关:hystrix.command.default.execution.timeout.enabled=true。默认值是true。
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds可以设置超时时限,默认是1000即1秒。注意这个超时时间指的是接收请求到转发请求给服务提供者这段时间,表示的是Consumer内部处理的这段时间,而不是真正服务提供者Provider处理时间。真正业务处理时间(包含Consumer到Provider和Provider到Consumer这两段的网络传输时间)是由之前的feign配置实现,下图所示:

(2)超时中断
当线程执行超时时是否中断线程的执行。默认为 true,即超时即中断。通过以下属性进行设置。
hystrix.command.default.execution.isolation.thread.interruptOnTimeout
(3) 取消中断
在线程执行过程中,若请求取消了,当前执行线程是否结束呢?由该值设置。默认为 false,即取消后不中断。通过以下属性进行设置。
hystrix.command.default.execution.isolation.thread.interruptOnCancel
(4) 信号量数量
若采用信号量执行隔离策略,则可通过以下属性修改信号量的数量,即对某一依赖所允许的请求的最高并发量。
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests
服务降级属性
(1) 降级请求最大数量
该属性仅限于信号量隔离。当信号量已用完后再有请求到达,并不是所有请求都会进行降级处理,而是在该属性设置值范围内的请求才会发生降级,其它请求将直接拒绝。
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests
(2) 服务降级开关
无论是线程隔离还是信号量隔离,当请求数量到达其设置的上限后再有请求到达是否会对请求进行降级处理,取决于该属性值的设置。若该属性值设置为 false,则不进行降级,而是直接拒绝请求。 默认true。
hystrix.command.default.fallback.enabled
服务熔断属性
(1) 熔断功能开关
设置当前应用是否开启熔断器功能,默认值为 true。
hystrix.command.default.circuitBreaker.enabled
(2) 熔断器开启阈值
当在时间窗内(10 秒)收到的请求数量超过该设置的数量后,将开启熔断器。默认值为 20。
注意,开启熔断器是指将直接拒绝所有请求;关闭熔断器是指将使所有请求通过。
hystrix.command.default.circuitBreaker.requestVolumeThreshold
(3) 熔断时间窗
当熔断器开启该属性设置的时长后,会尝试关闭熔断器,以恢复被熔断的服务。默认值为 5000 毫秒。
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds
(4) 熔断开启错误率
当请求的错误率高于该百分比时,开启熔断器。默认值为 50,即 50%。
hystrix.command.default.circuitBreaker.errorThresholdPercentage
(5) 强制开启熔断器
设置熔断器无需条件开启,拒绝所有请求。默认值为 false。
hystrix.command.default.circuitBreaker.forceOpen
(6) 强制关闭熔断器
设置熔断器无需条件的关闭,通过所有请求。默认值为 false。
hystrix.command.default.circuitBreaker.forceClosed
线程池相关属性
可参考:https://github.com/Netflix/Hystrix/wiki/Configuration#ThreadPool
https://www.cnblogs.com/frankyou/p/10135212.html

集群监控
Hystrix既然能够对服务进行降级和熔断。固然其内部包含对请求的监控能力。通过hystrix-dashboard可以可视化。
(1)单机监控
主要修改consumer。
-
添加 hystrix-dashboard 与 actuator 依赖
-
配置文件中开启 actuator 的 hystrix.stream 监控终端
-
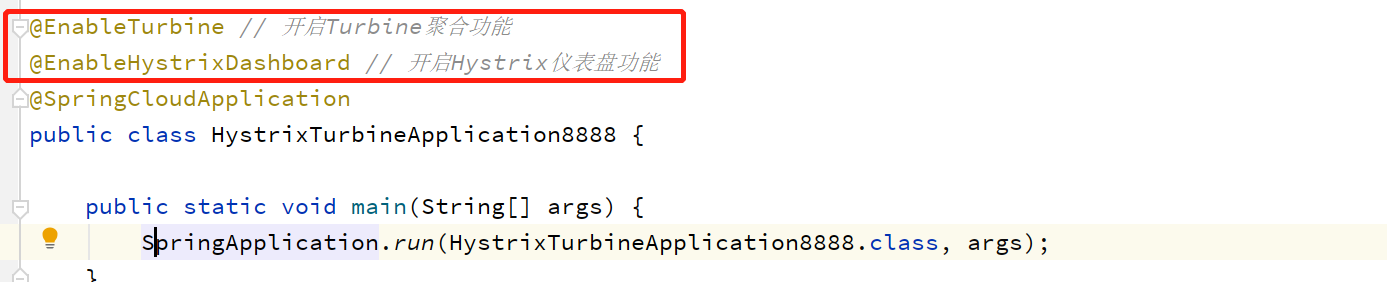
在启动类上添加@EnableHystrixDashboard 注解
<!-- hystrix-dashboard依赖 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId> </dependency> <!--actuator依赖不能少--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>

访问https://localhost:8080/hystrix即可访问到Hystrix登入界面:
【可以指定监控集群的地址、监控的时间窗】
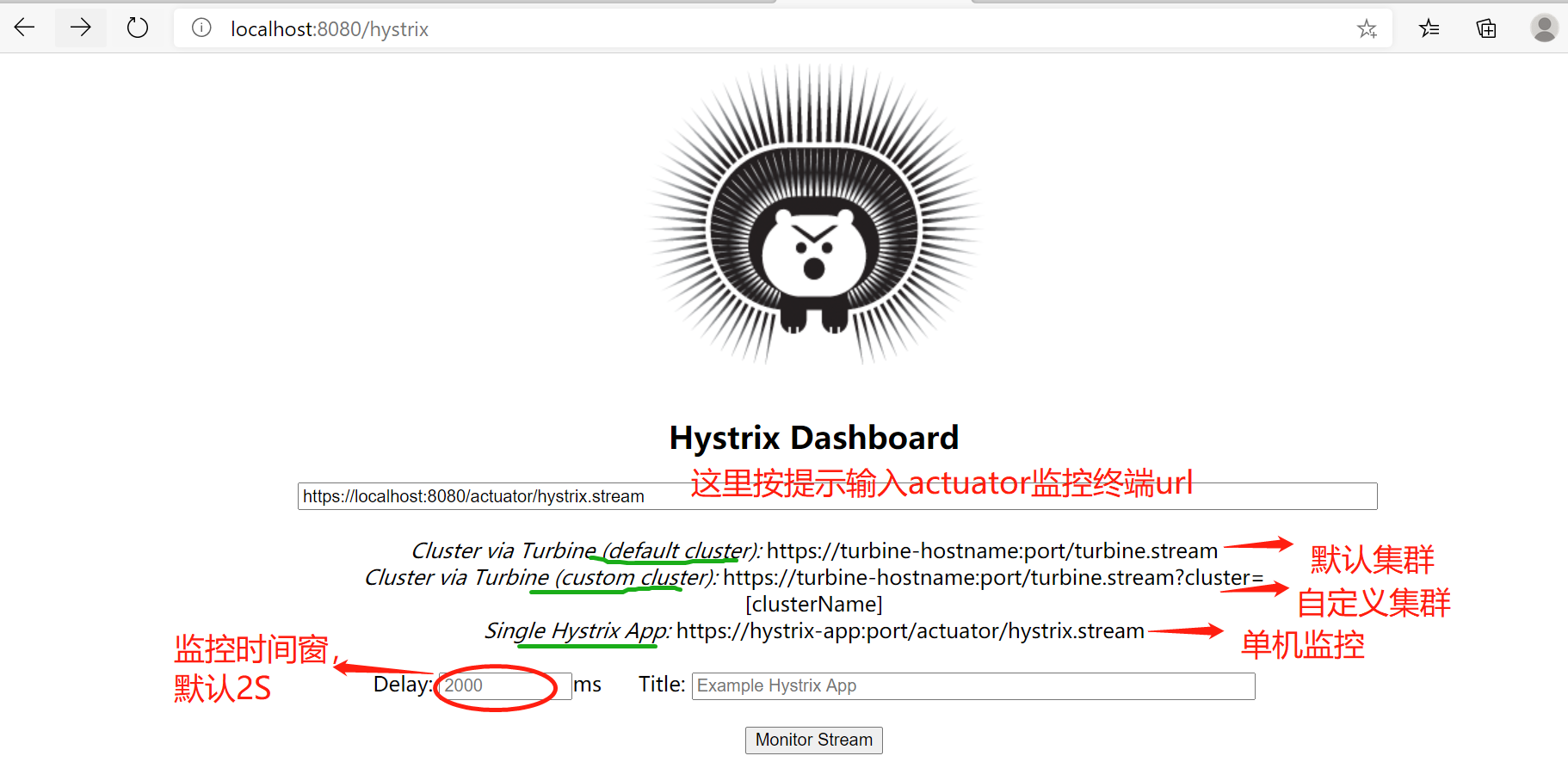
注意一点:如果https报错,可以使用http。
最终监控界面如下图:

(2)单个组集群监控
以上是对单个机器的监控。通常情况下我们监控的是整个集群。这时候就需要使用Turbine进行聚合监控。
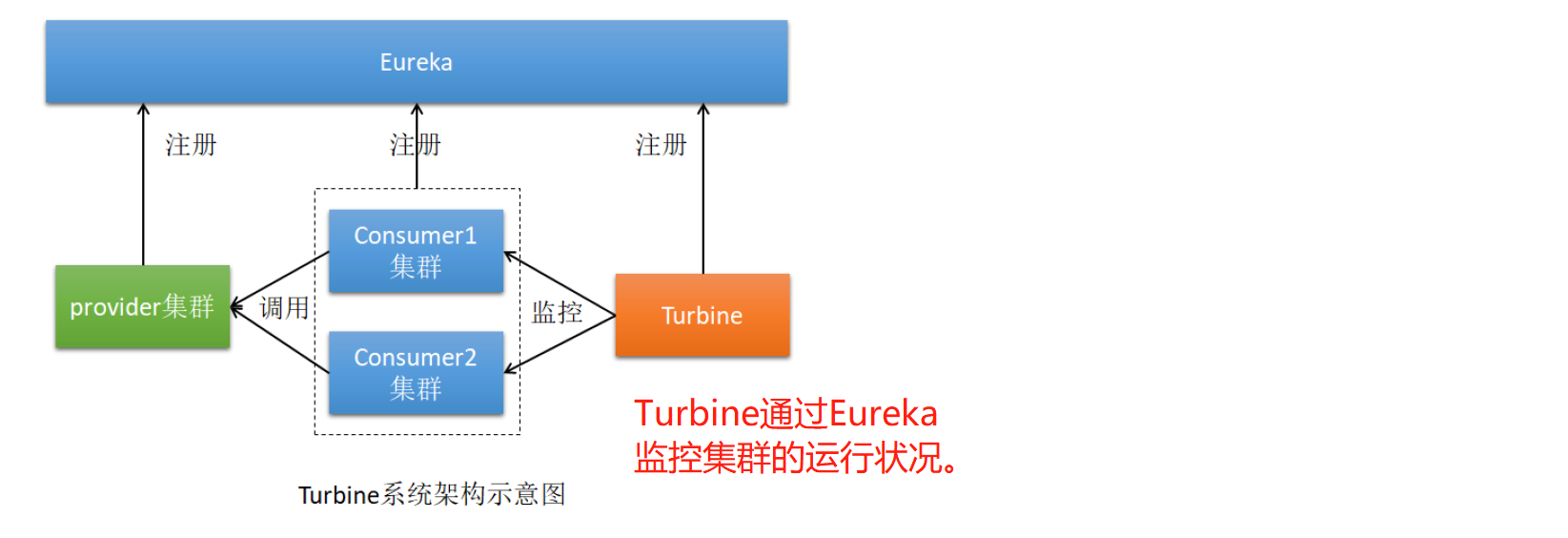
这个时候Consumer逻辑上属于Turbine的客户端。
总步骤:
(1) Turbine Client
至少要有 actuator 与 neflix-hystrix 依赖
在配置文件中必须开启 acturator 的 hystrix.stream 监控终端
(2) Turbine Server
至少要有如下依赖:
netflix-turbine 依赖
netflix -hystrix-dashboard 依赖
netflix -hystrix 依赖
actuator 依赖
eureka client 依赖
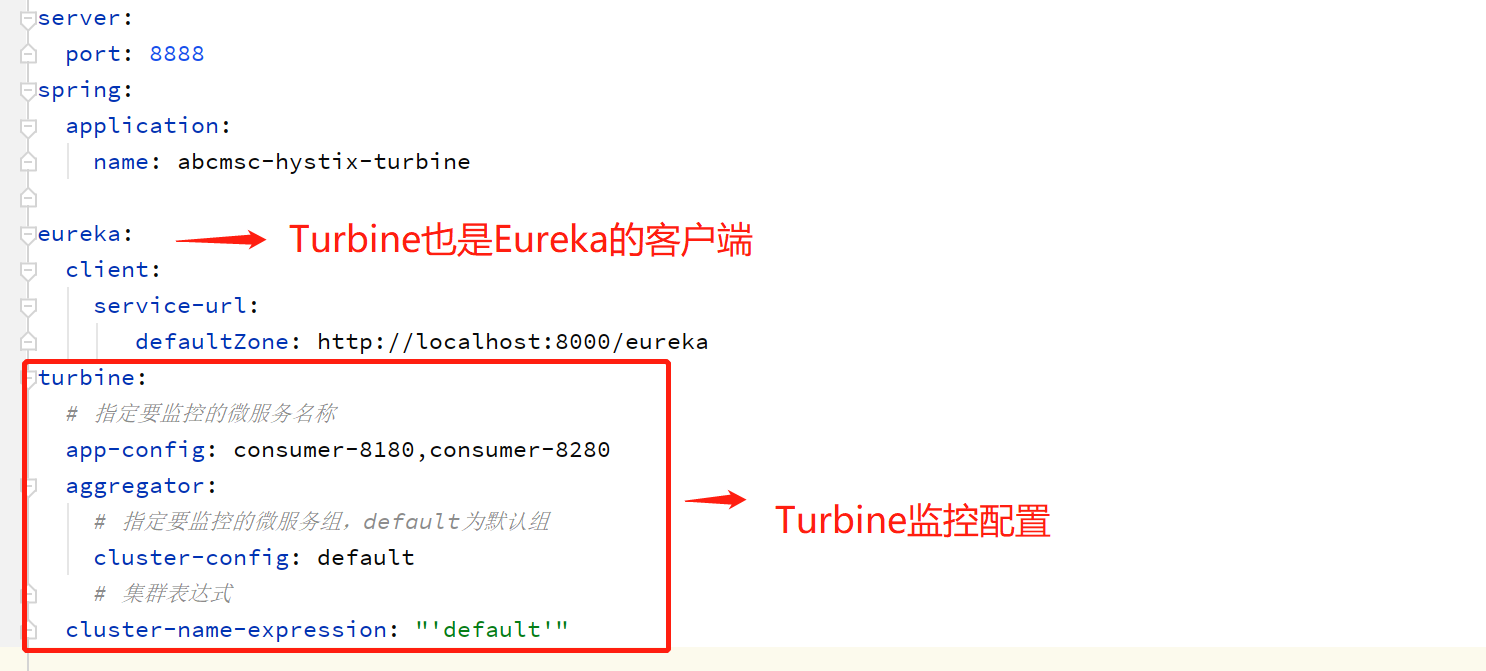
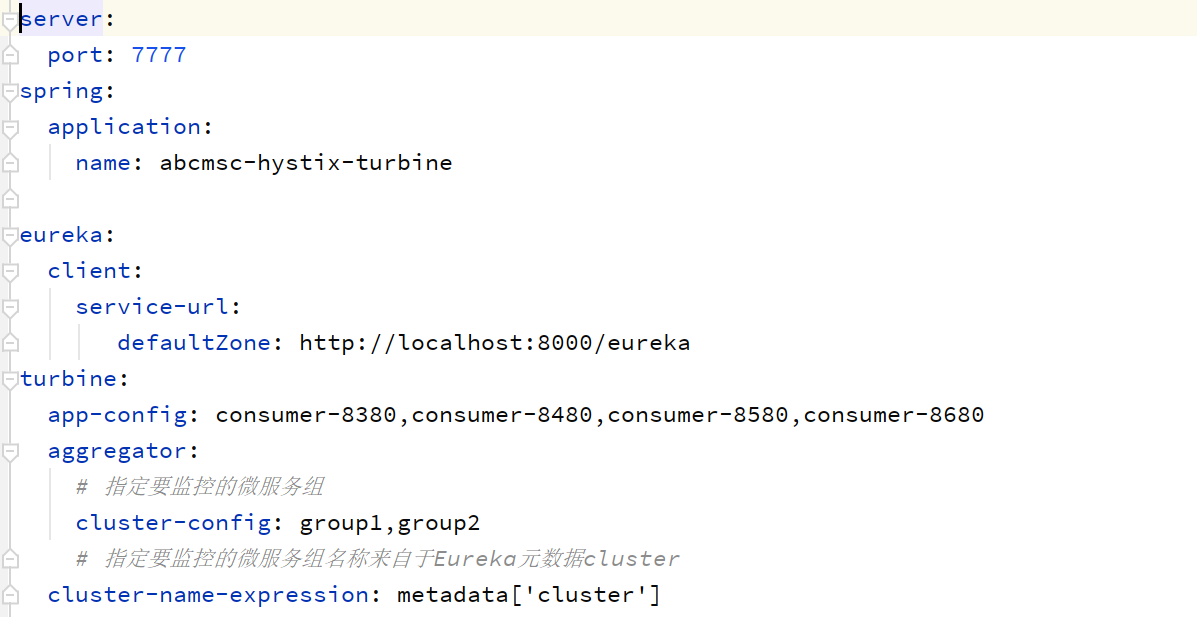
在配置文件中要配置 turbine:指定要监控的 group 及相应的微服务名称
以两个Consumer(Turbine Clinet)、一个Turbine Server、一个Eureka为例。
①consumer(Turbine Clinet)设置
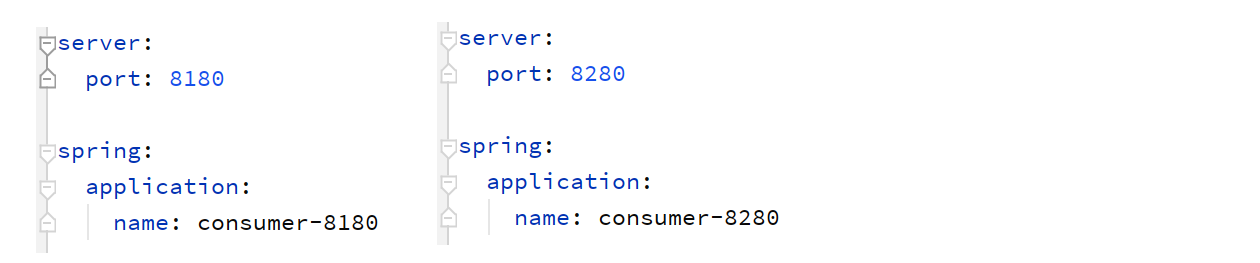
此时已经不需要dashboard,删除dashboard依赖,删除启动类@EnableHystrixDashboard。acturator 的监控终端 hystrix.stream依然保留。
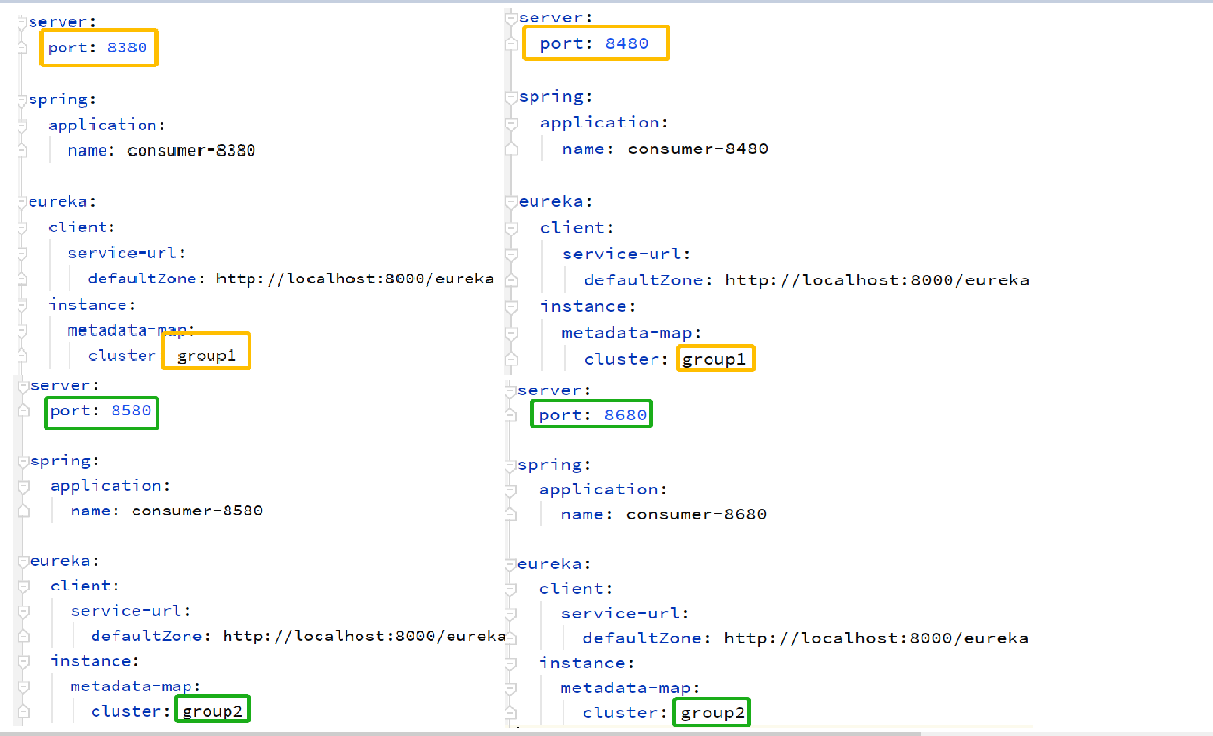
创建两个配置conusmer,区别如下(这里使用一个微服务表示一个集群。两个集群同属于Turbine的默认组default):
②Turbine Server设置
依赖比较杂,全部贴出来
<!-- Eureka服务端依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!-- hystrix-turbine依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
<!-- hystrix-dashboard依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<!--hystrix依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<!--actuator依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
yml配置
启动类配置
最终监控界面可以看到同时监控了默认组default下的两台host。
(3)多个组集群监控
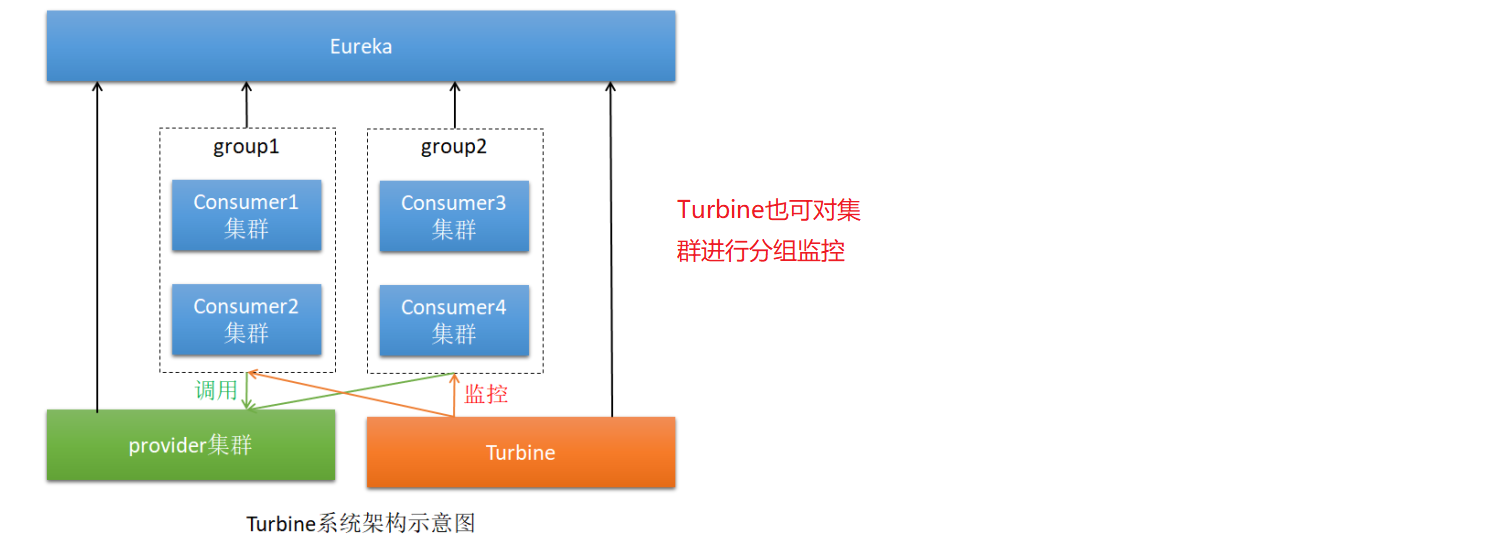
实现原理是,服务向Eureka注册的时候,添加一个元数据信息,key为cluster。Turbine最终通过cluster的值对集群进行不同的分组。
consumer配置如下:
Turbine配置如下:
最终可以通过Turbine分别监控多组host。
报警机制
无论是何种原因导致的服务降级,实际中都应该设置合理的措施向管理员发送报警。比如发送短信等。
九、微服务网关Zuul
网关是系统唯一对外的入口,介于Consumer之前,用于对请求进行鉴权、限流、路由、监控等功能。
路由规则
首先,zuul网关也是Eureka的客户端,因为需要从Eureka中读取微服务注册列表。
我们以两个普通的consumer工程、一个zuul、一个Eureka为例。说明主要的一些路由规则设置。
基础环境搭建
两个consumer,端口服务名分别为:8080:abcmsc-consumer-depart-8080;8090:abcmsc-consumer-depart-8090。搭建省略。
一个Eureka,端口8000。搭建省略。
主要是Zuul工程搭建:
(1)pom文件
<!-- Eureka服务端依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--zuul依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
(2)启动类
(3)配置文件,和普通Eureka Client一样

基础搭建完成,启动所有应用测试一下。一切ok,开始zuul。

以下配置可参考:ZuulProperties.java
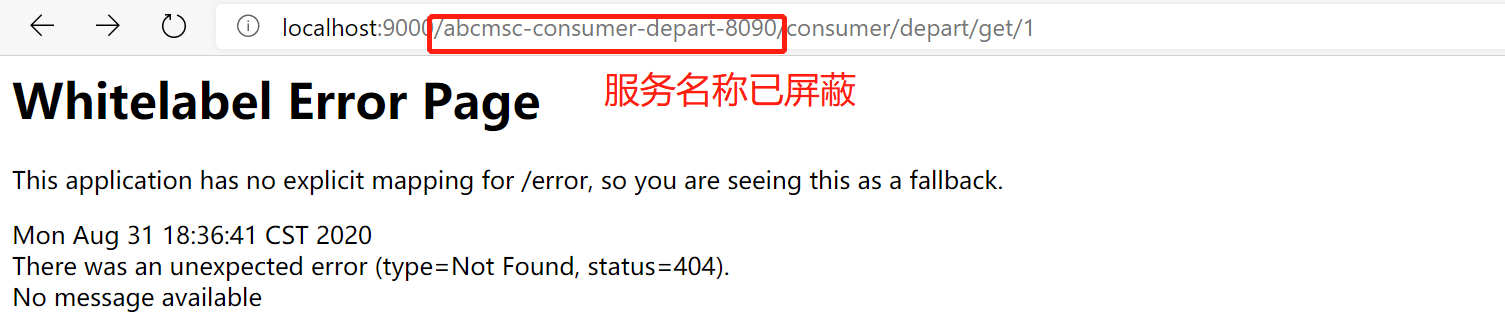
(1) 路由转发、服务名称屏蔽
前面的访问方式,需要将微服务名称暴露给用户,会存在安全性问题。所以,可以自定义路径来替代微服务名称,即自定义路由策略。


(2)路由前缀


(3)屏蔽指定请求路径

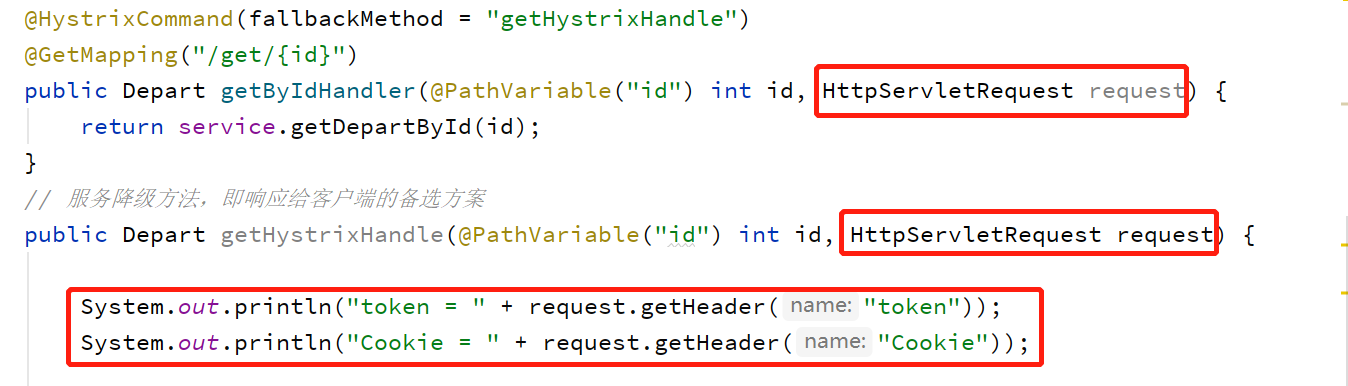
(4)屏蔽敏感请求头
a)默认情况下,"Cookie", "Set-Cookie", "Authorization"会被屏蔽掉

我们可以自定义屏蔽key。需要注意的是自己设定会覆盖掉默认值。
我们修改consumer,打印请求头信息验证一下:
可以使用postman传入如下参数测试:
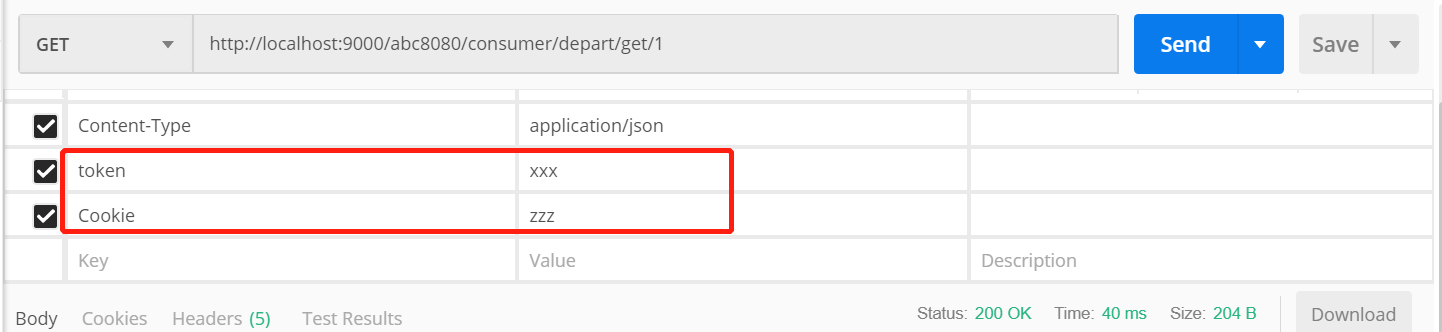
发现输出结果中Cookie为null,证明Zuul屏蔽了Cookie。

b)我们也可以通过设置屏蔽掉token

测试输出结果,也验证了自定义设置会覆盖掉默认设置:

如果想保留原有设置,则需要一并配置上:

负载均衡
负载均衡按理应该也属于路由规则篇章,单独摘出来是因为和Feign的负载均衡做一个比较说明。前者是网关对消费者的负载均衡,后者是消费者对提供者的负载均衡。
实现起来很简单,默认是轮询算法(因为本质是使用ribbon,和消费者对提供者实现方式一模一样),这里不多做介绍。如下为使用随机算法:
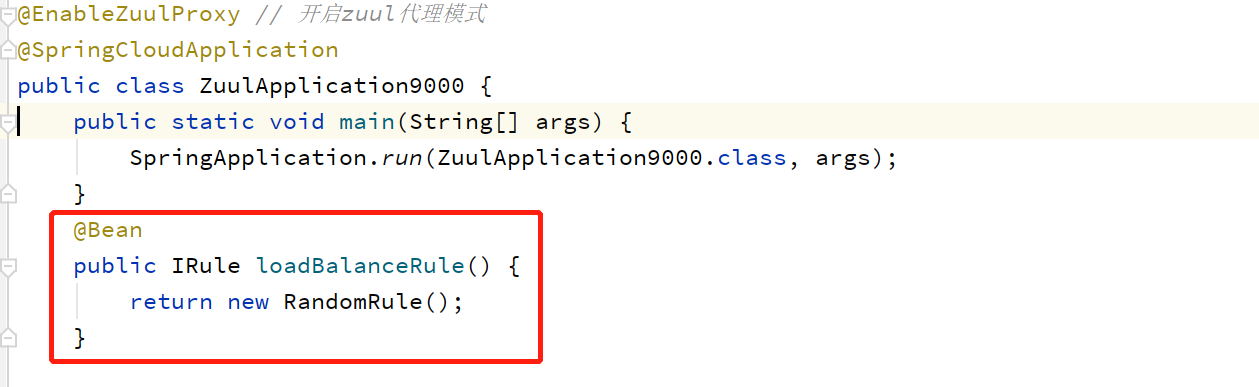
通过以上配置,即可实现Zuul对abcmsc-consumer-depart微服务的随机负载均衡。默认是轮询算法。

服务降级
同理。当消费者调用提供者时由于各种原因出现无法调用的情况时,消费者可以进行服务降级。那么,若客户端通过网关调用消费者无法调用时,是否可以进行服务降级呢?当然可以,zuul具有服务降级功能,本质也是Hystrix。
只需向容器注入一个实现FallbackProvider接口的Bean即可。
@Component
public class ConsumerFallback implements FallbackProvider {
@Override
public String getRoute() {
// 指定要降级的微服务名称
return "*";// 支持通配符
// return "abcmsc-consumer-depart-8080";
}
@Override
public ClientHttpResponse fallbackResponse(String route, Throwable cause) {
// 如果不是微服务abcmsc-consumer-depart-8080,则不降级处理
if (!"abcmsc-consumer-depart-8080".equals("")) {
return null;
}
return new ClientHttpResponse() {
@Override
public HttpStatus getStatusCode() throws IOException {
return HttpStatus.SERVICE_UNAVAILABLE;
}
@Override
public int getRawStatusCode() throws IOException {
return HttpStatus.SERVICE_UNAVAILABLE.value();
}
@Override
public String getStatusText() throws IOException {
// 状态码短语 “Service Unavailable”
return HttpStatus.SERVICE_UNAVAILABLE.getReasonPhrase();
}
@Override
public void close() {
// 这里可以进行资源释放
}
@Override
public InputStream getBody() throws IOException {
// 返回降级信息
String msg = "Zuul 实现了服务降级";
return new ByteArrayInputStream(msg.getBytes());
}
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
};
}
}

请求过滤原理
Zuul也支持请求过滤,通过ZuulFilter过滤器实现。
假设过滤要求是:对于请求“/abc8080”,如果参数中有user则通过过滤,如果没有user则提示“401未鉴权”。
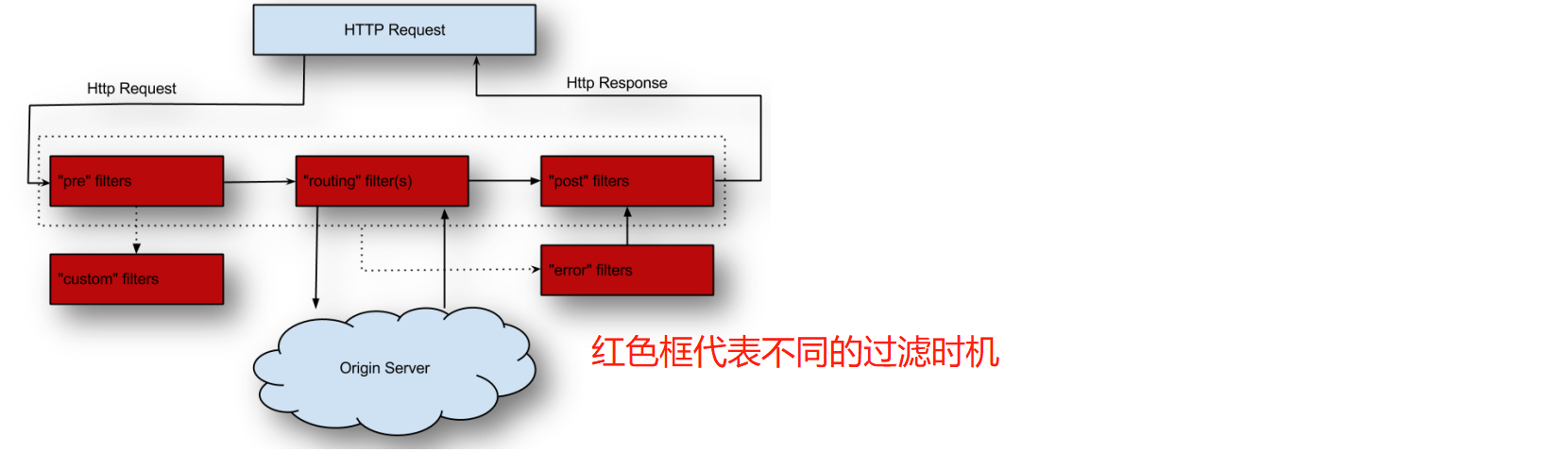
代码实现:
@Component
public class RouteFilter extends ZuulFilter {
@Override
public String filterType() {
// 指定路由之前进行过滤
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
// 过滤器优先级,值越小优先级越高。系统内置过滤器最小值为-3。
// 在FilterConstants.java中可以查看。
return -5;
}
/**
* 这个方法返回true才会执行run
*/
@Override
public boolean shouldFilter() {
//com.netflix.zuul.context.RequestContext
// 获取上下文信息
RequestContext context = RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
String user = request.getParameter("user");
String uri = request.getRequestURI();
if (uri.contains("/abc8080") && StringUtils.isEmpty(user)) {
// 指定当前请求未通过Zuul,默认值为true
context.setSendZuulResponse(false);
context.setResponseStatusCode(HttpStatus.SC_UNAUTHORIZED);
return false;
}
return true;
}
@Override
public Object run() throws ZuulException {
System.out.println("通过过滤");
return null;
}
}

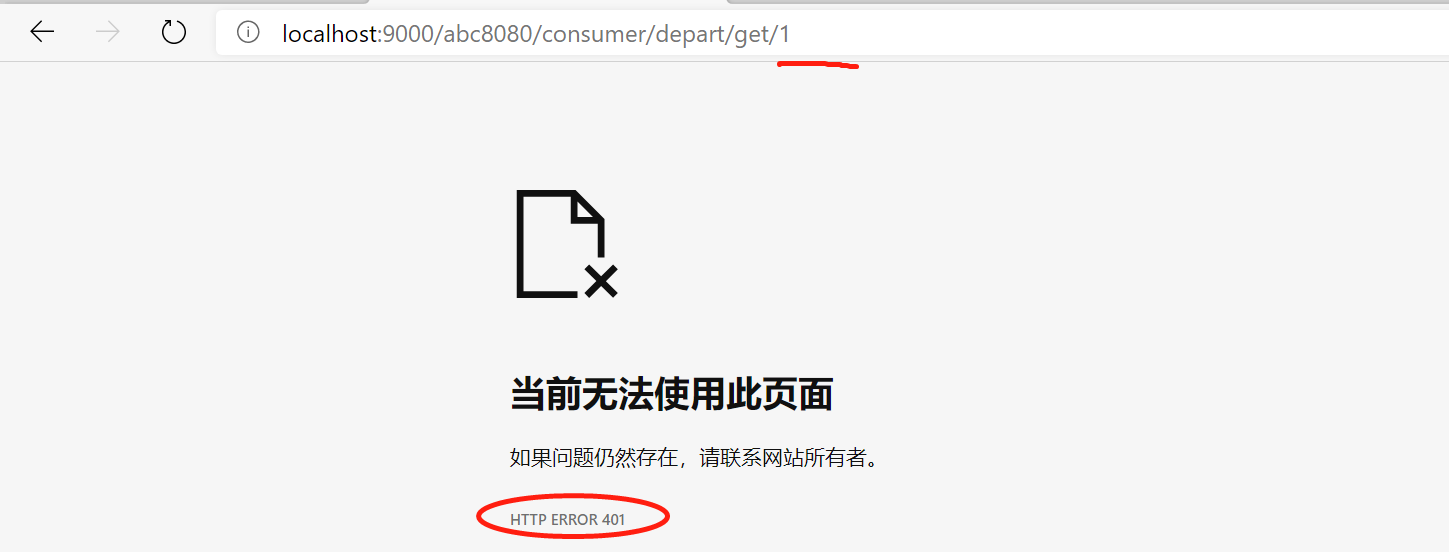
以上是Zuul过滤的基础原理实现,下面再通过令牌桶算法学习一下Zuul基于过滤器进行限流的具体实现。
令牌桶限流
原理图:

以一定的速率生产令牌,每到达一个请求就需要申请一定的令牌资源,如果申请不到令牌,则按照业务进行服务降级或者其他处理。
实现:
修改以上的过滤器。使用令牌桶,代码如下:
// com.google.common.util.concurrent.RateLimiter(spring已经集成了这个包,无需其他包)
// 每秒产生2个令牌
private static final RateLimiter RATE_LIMITER = RateLimiter.create(2);
@Override
public boolean shouldFilter() {
RequestContext context = RequestContext.getCurrentContext();
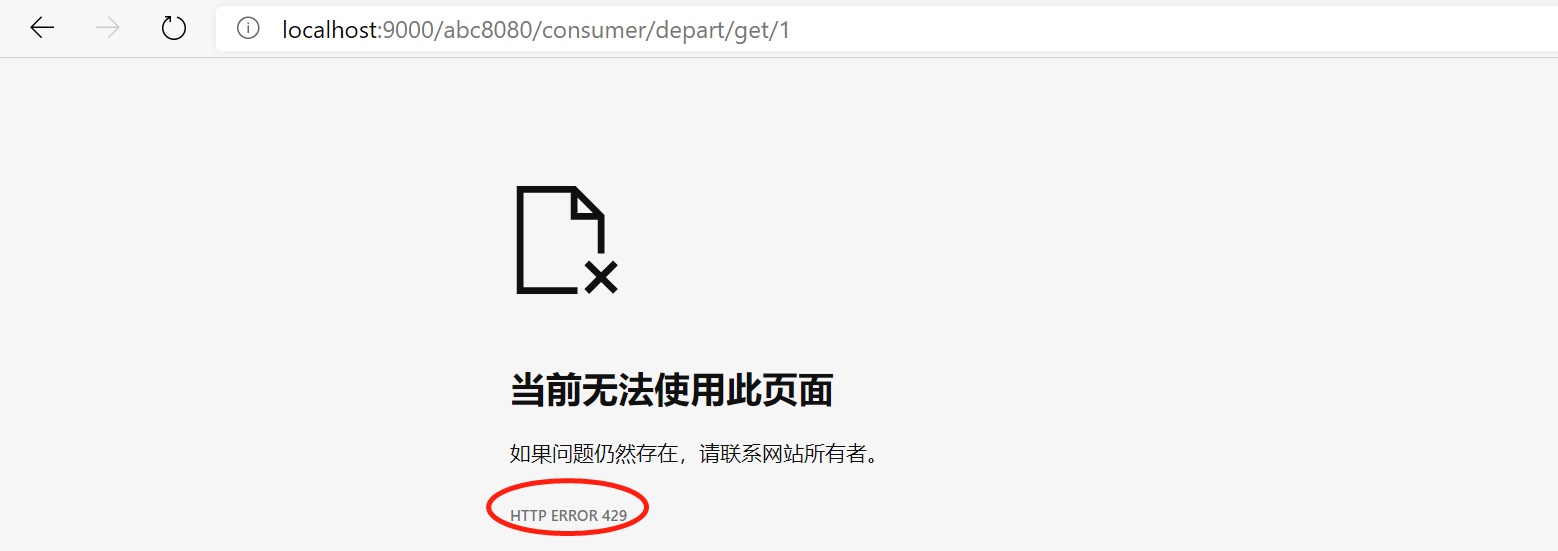
// 立即获取一个令牌,获取不到则返回false
if (!RATE_LIMITER.tryAcquire()) {
context.setSendZuulResponse(false);
context.setResponseStatusCode(429); // 429-Too Many Requests
return false;
}
return true;
}
如果请求频繁超过令牌生产速率,则报错(当然实际中不是直接报错,可以进行其他处理,错误页面等):
多维请求限流
令牌桶限流的粒度比较粗。一个老外使用路由过滤,针对Zuul编写了更细粒度的限流库(spring-cloud-zuul-ratelimit)。支持:
- user:针对用户的限流,即对单位时间窗内经过网关的用户数量的限制。
- origin:针对客户端 IP 的限流,即对单位时间窗内经过网关的 IP 数量的限制。
- url:针对请求 URL 的限流,即对单位时间窗内经过网关的 URL 数量的限制。
导入依赖
<!-- spring-cloud-zuul-ratelimit依赖 -->
<dependency>
<groupId>com.marcosbarbero.cloud</groupId>
<artifactId>spring-cloud-zuul-ratelimit</artifactId>
<version>2.0.5.RELEASE</version>
</dependency>
配置限流策略
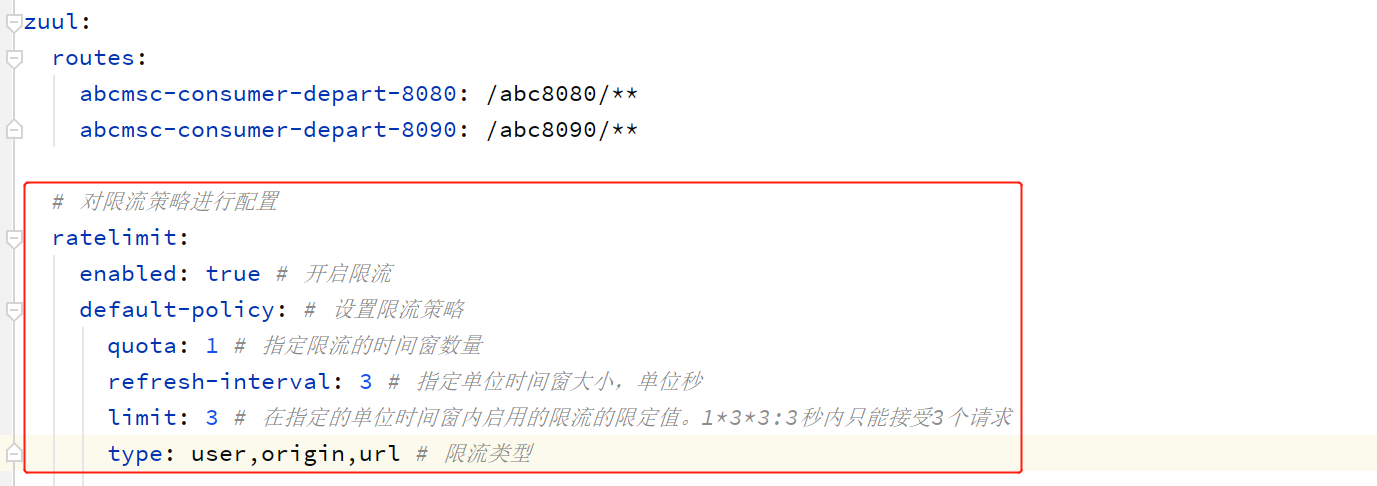
测试
测试url,3秒之内请求量超过3次则报错。
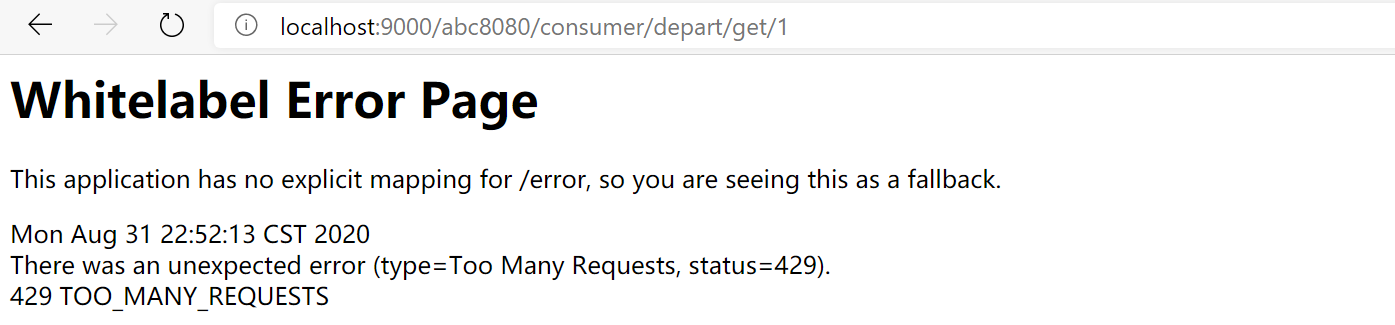
灰度发布
灰度发布是一种系统更新迭代的平滑处理方式。
前面介绍actuator的平滑上下线时是基于Eureka的元数据,这里也是基于Eureka元数据实现。
以一种场景演示:将请求均衡的转发到新版Consumer和旧版Consumer上。
为Consumer添加Eureka元数据
以两个host为例。
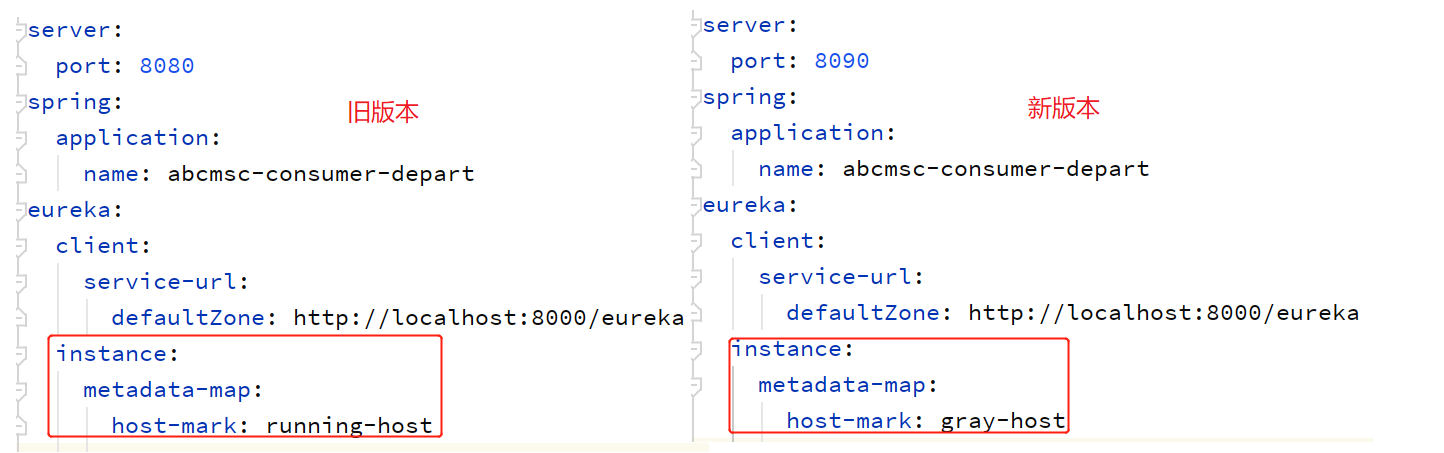
配置Zuul路由转发
首先导入依赖:
<dependency>
<groupId>io.jmnarloch</groupId>
<artifactId>ribbon-discovery-filter-spring-cloud-starter</artifactId>
<version>2.1.0</version>
</dependency>
借助ZuulFilter过滤器将请求转发到不同版本的微服务:
package com.abc.filter;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import com.netflix.zuul.exception.ZuulException;
import io.jmnarloch.spring.cloud.ribbon.support.RibbonFilterContextHolder;
import org.apache.http.HttpStatus;
import org.springframework.cloud.netflix.zuul.filters.support.FilterConstants;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import javax.servlet.http.HttpServletRequest;
import java.util.concurrent.atomic.AtomicBoolean;
@Component
public class RouteFilter2 extends ZuulFilter {
@Override
public String filterType() {
// 指定路由之前进行过滤
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
// 过滤器优先级,值越小优先级越高。系统内置过滤器最小值为-3。在FilterConstants.java中可以查看。
return -5;
}
private AtomicBoolean flag = new AtomicBoolean(true);
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() throws ZuulException {
System.out.println("通过过滤");
if (flag.get()) {
RibbonFilterContextHolder.getCurrentContext().add("host-mark", "running-host");
flag.set(false);// 更改值,下一次路由到新版本
} else {
RibbonFilterContextHolder.getCurrentContext().add("host-mark", "gray-host");
flag.set(true);// 更改值,下一次路由到旧版本
}
return null;
}
}
十、分布式配置管理Spring Cloud Config
主要基于两点原因,就诞生了许多统一配置的产品。如:Spring Cloud Config:
①集群配置的重复性;
②配置文件更改的不便性。
Spring Cloud Config 就是对微服务的配置文件进行统一管理的。
相关产品:
百度:disconf, 阿里:diamand, zookeeper
工作原理图:
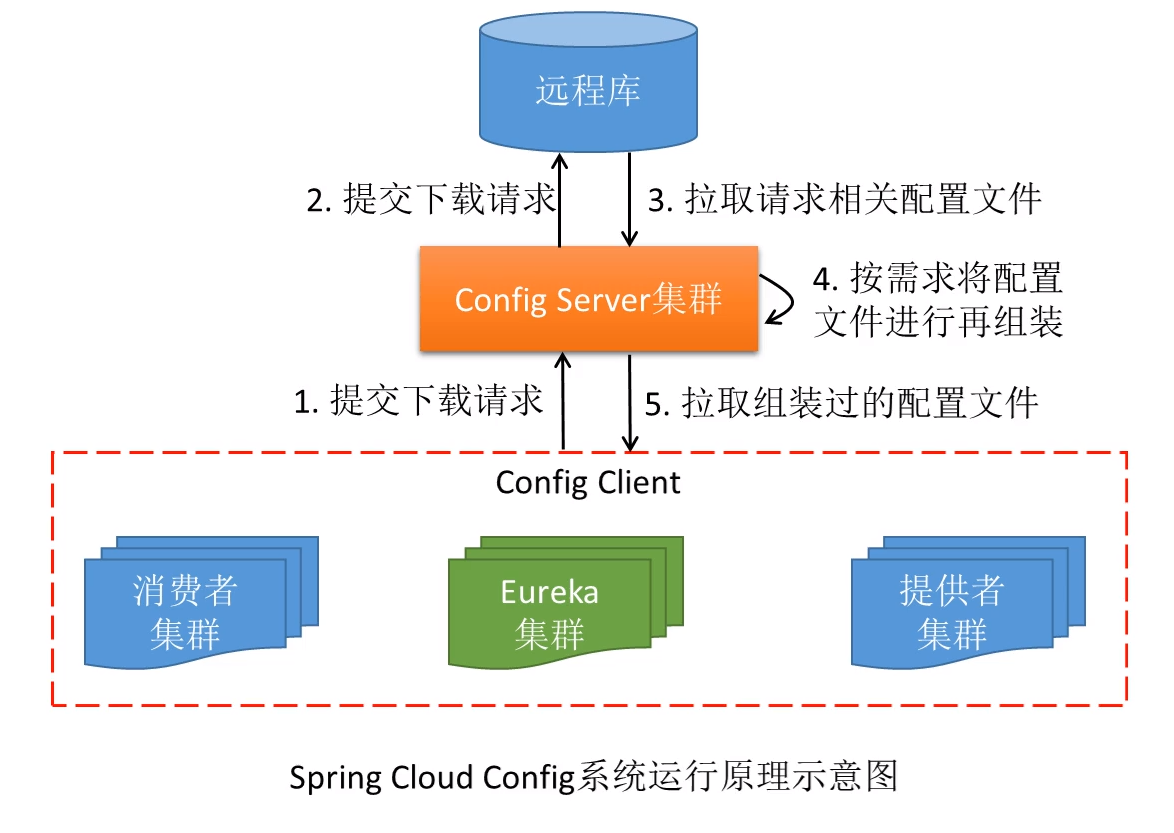
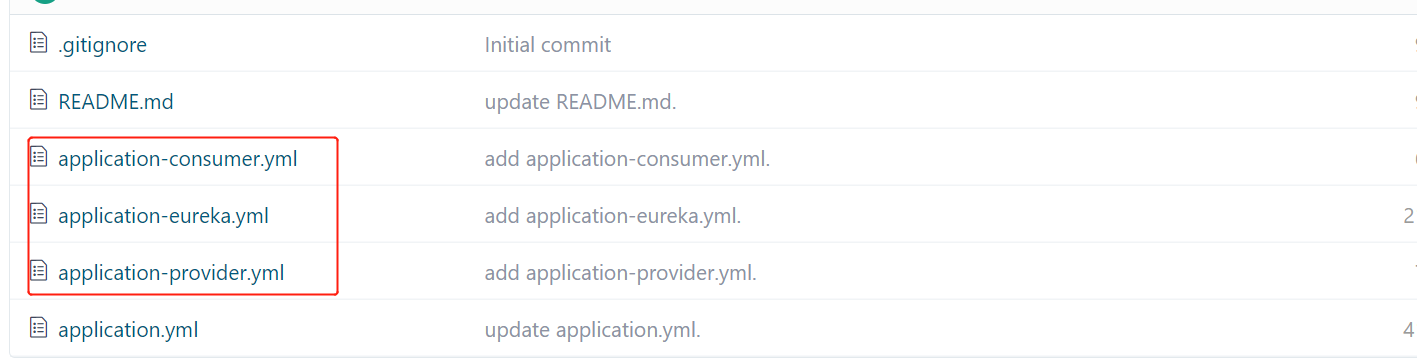
远程库可以采用github、gitlab、gitee等等。此文采用的是gitee。远程库资源如下:
Config-Server
导入 config server 的依赖
在启动类上添加@EnableConfigServer 注解
在配置文件中指定要连接的 git 远程库地址等信息
<!-- Spring Cloud Config Server 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>

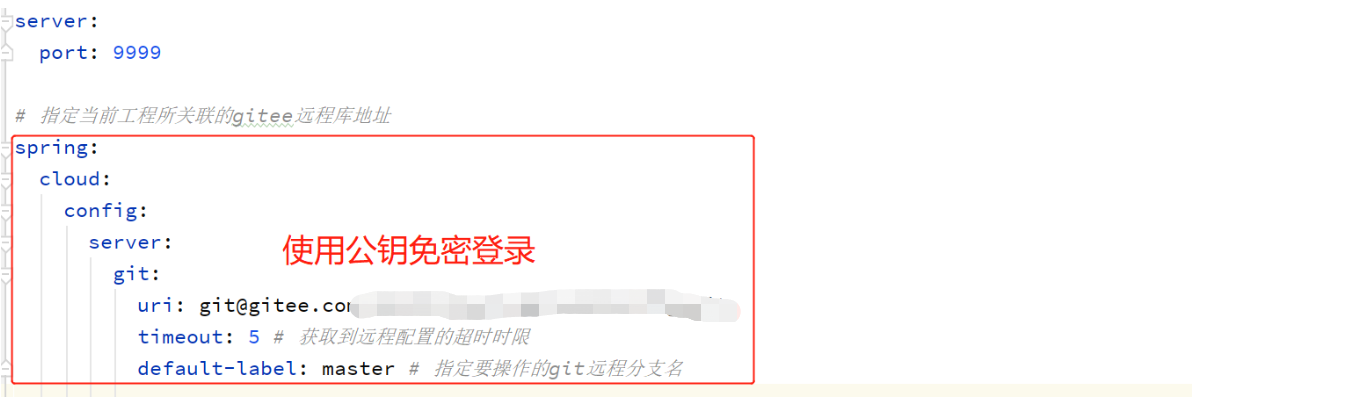
地址来源(此处使用的是SSH免密登录,也可以使用https方式,需要配置用户名密码):

Config-Eureka
导入 config 的客户端依赖
定义 bootstrap.yml 配置文件,在其中指定要连接的 config server 地址
删除application.yml 文件
主要配置bootstrap.yml启动文件:
bootstrap.yml 中配置的是应用启动时所必须的配置信息。
application.yml 中配置的是应用运行过程中所必须的配置信息
bootstrap.yml 优先于 application.yml 进行加载。
原有配置文件移至远程库,本地配置bootstrap.yml,

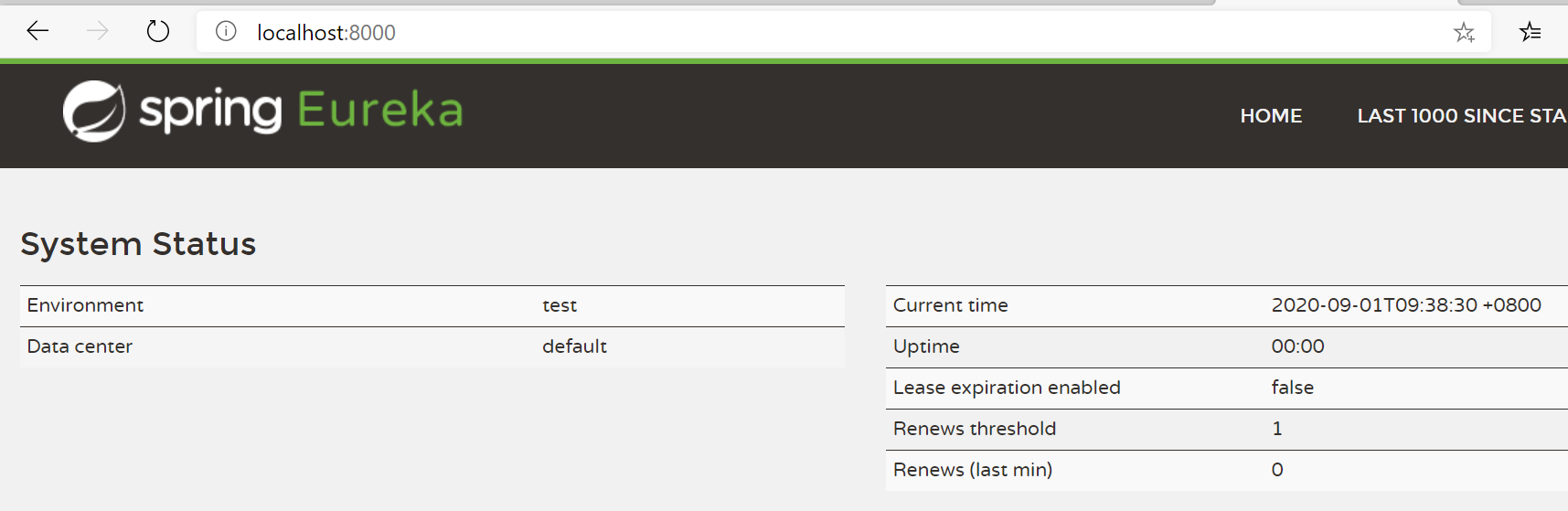
启动测试,Eureka Server正常:
启动日志中可以看到:Fetching config from server at : http://localhost:9999。表示拉取配置文件。
Config-Provider
同上。注意Spring Cloud Config Server 依赖不要缺少。

Config-Consumer
同上。

启动Config-Server、Config-Eureka、Config-Provider、Config-Consumer。测试结果正常:



配置文件动态更新
Gitee、Github上提供了WebHooks功能,支持配置文件的动态更新。配置文件更新时,需要每一个Config Client手动发送一个actuator的post请求,同时要求每一个Config Client在Gitee上进行注册。如果Config Client很多的话,实际操作中不是很方便。有兴趣可参考:https://blog.csdn.net/qq_32423845/article/details/79579341
由于这些弊端,所以,在Spring Cloud中,有另一种解决方案。Spring Cloud Config。

当配置文件更新时,只需要任意一个Config Client手动向Config Server发送post请求即可,这个配置文件的变更会基于Spring Cloud Bus消息总线在Config Client中广播开来。实现原理图如下:

(1)修改远程库中的配置文件
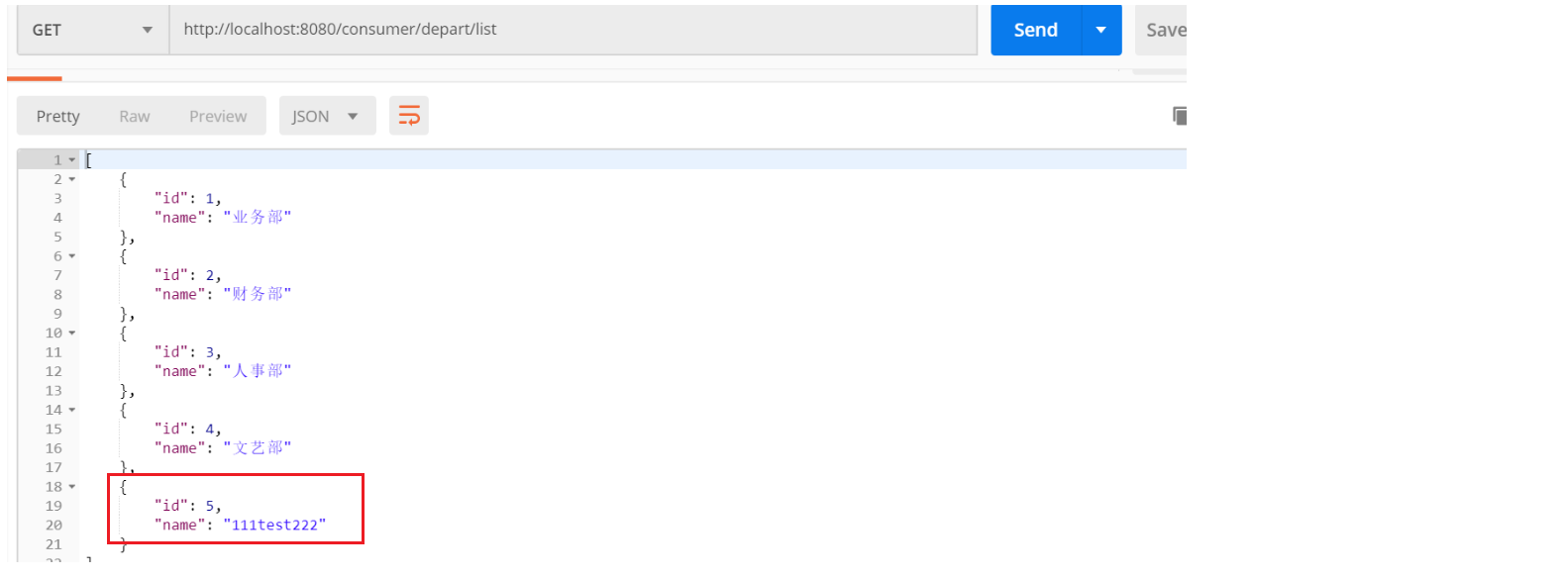
为了方便后面的测试,这里分别在提供者配置文件 application-provider.yml 与消费者配置文件 application-consumer.yml 中各添加了一个自定义属性。
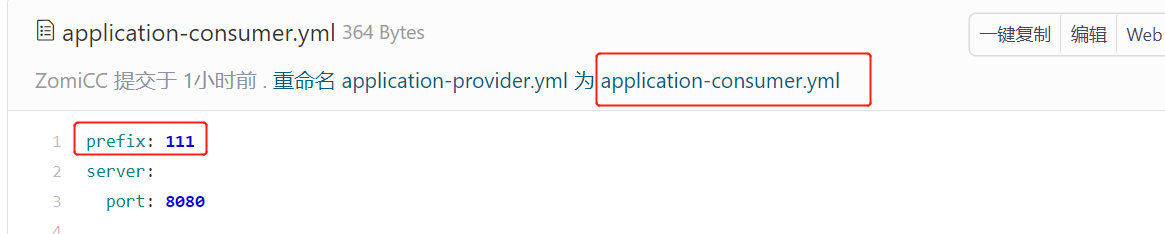

修改consumer、provider的controller,将这两个自定义属性添加到name的前缀和后缀。比如:输入name=test,则保存到数据库中就是111test222。
(2)修改Config-Provider
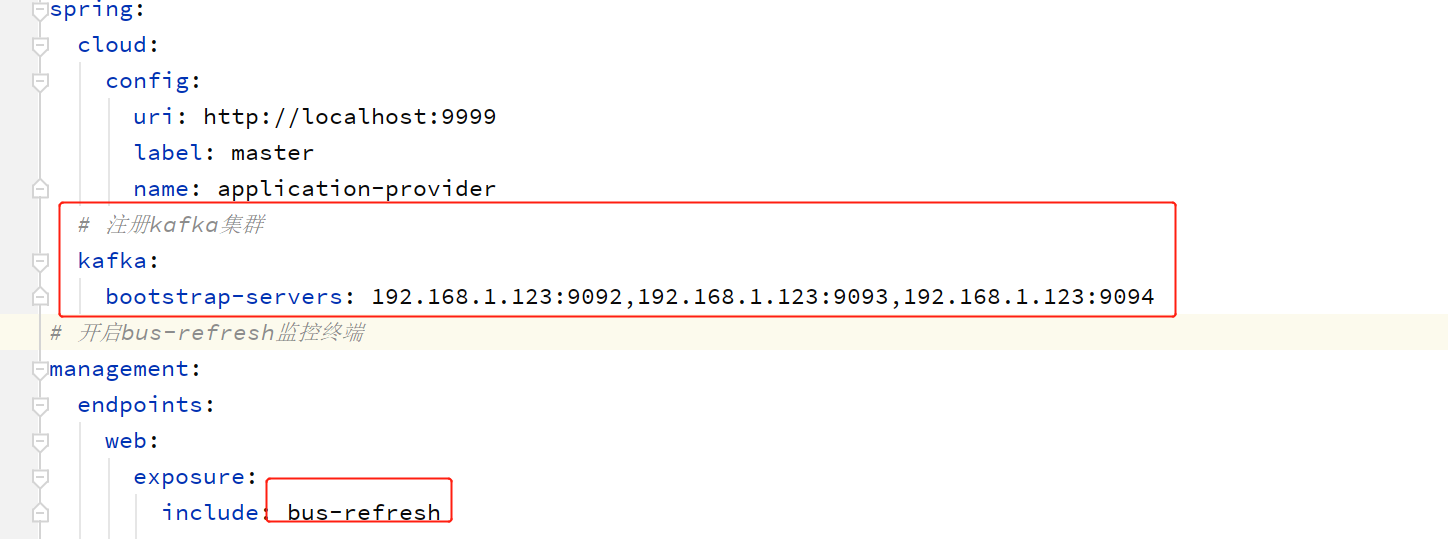
导入 actuator 与 bus-kafka 依赖
在配置文件中指定要连接的 kafka 集群,并开启 actuator 的 bus-refresh 监控终端
在需要自动更新的类上添加@RefreshScope 注解
导入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-actuator</artifactId>
</dependency>
修改配置文件:
修改provider处理器,并添加@RefreshScope 注解:
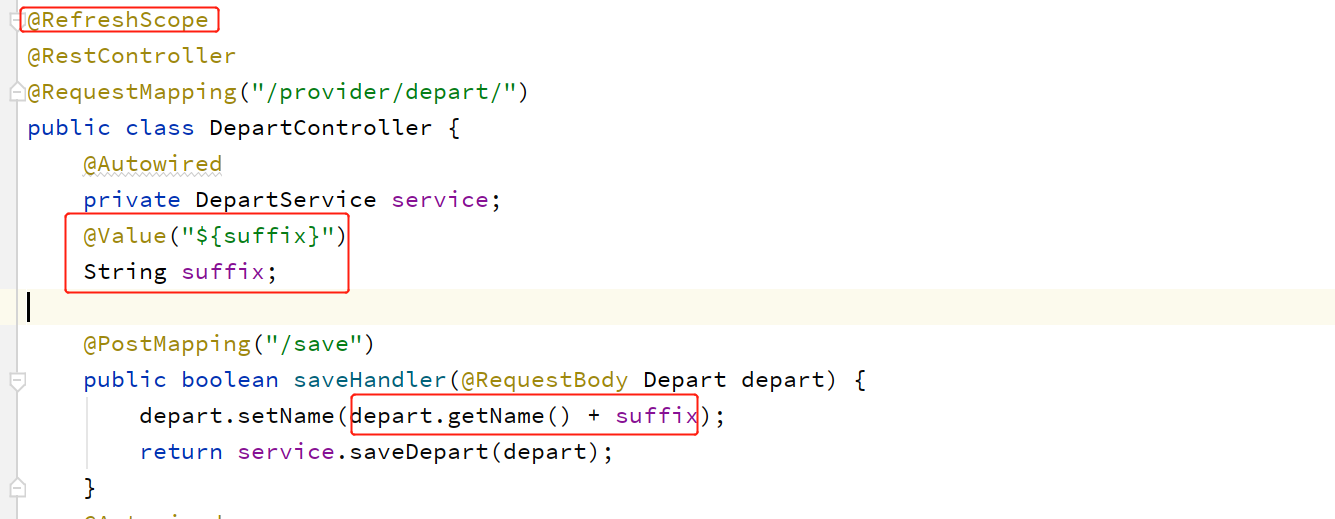
(3)修改Config-Consumer
依赖和配置和Config-Provider一样。
修改Consumer处理器,并添加@RefreshScope注解:
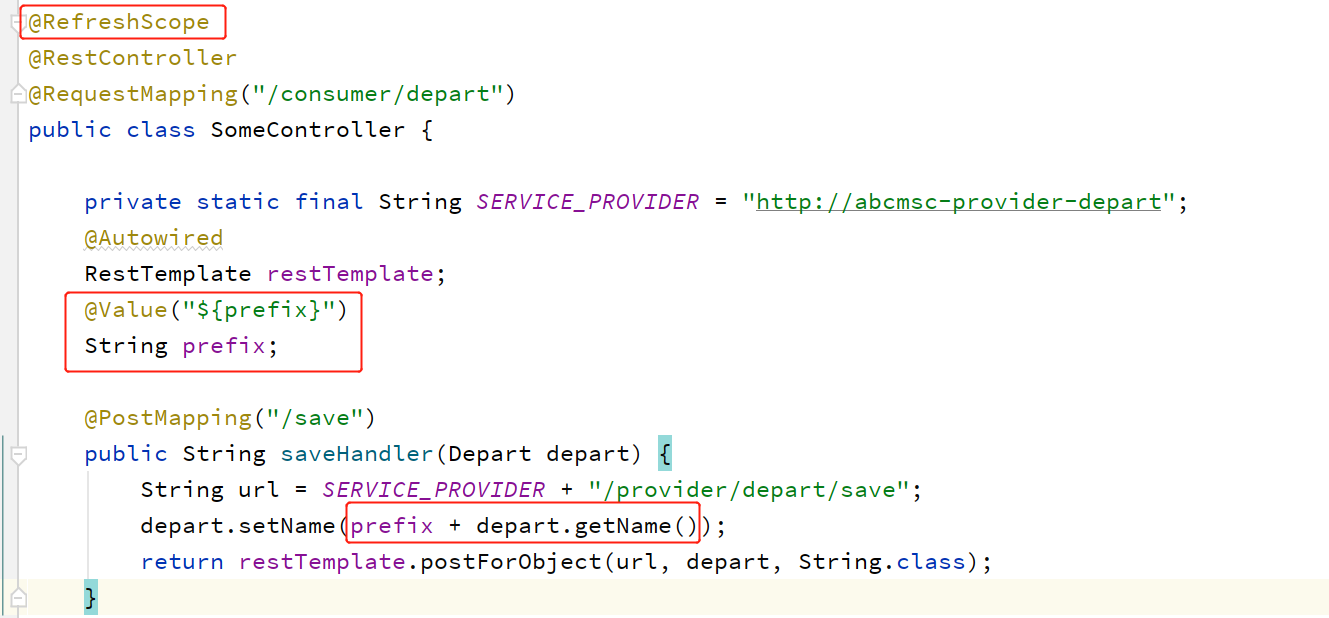
启动测试:

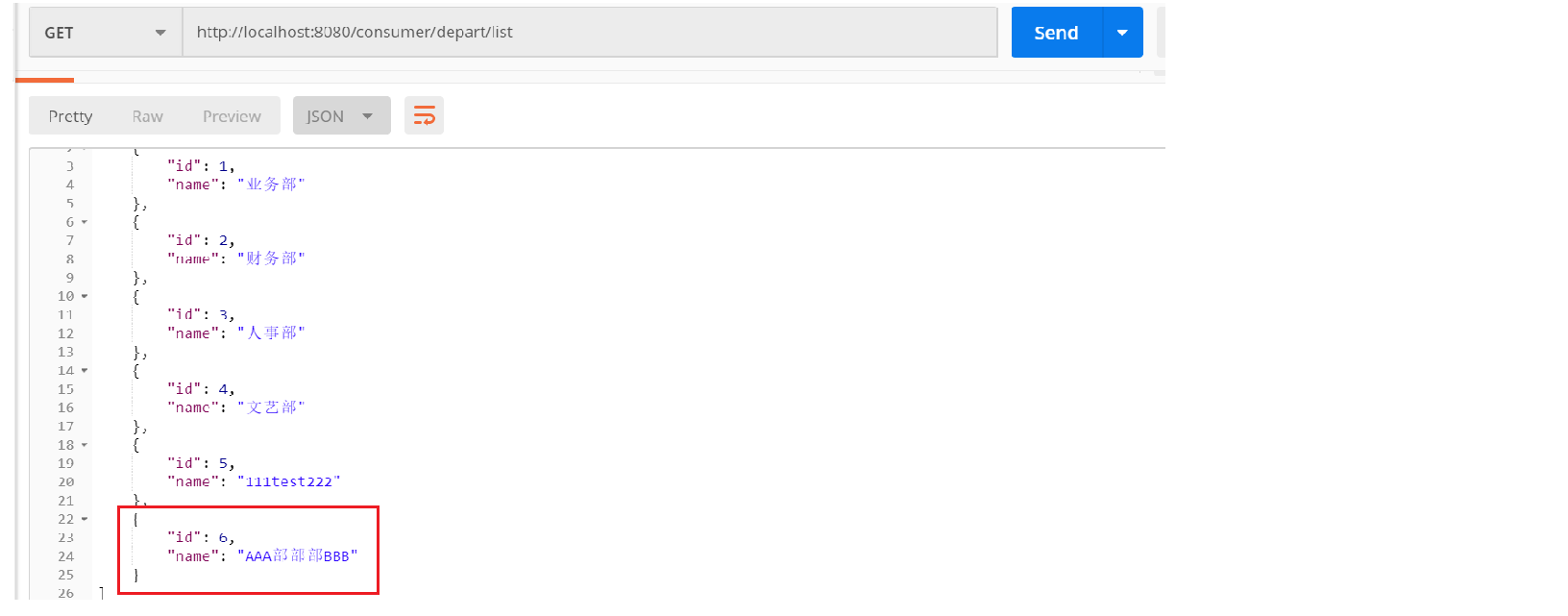
动态修改配置文件。prefix改为AAA,suffix改为BBB。然后向任意一个Config-Client发送一个post请求。(可以看到后台是进行了重新拉取配置文件,然后向Eureka重新注册。UP->DOWN->STARTING->UP)
 再测试:
再测试:

十一、调用链跟踪SpringCloudSleuth+Zipkin
微服务架构,微服务的数量固然庞大,解决问题也显得比较困难。所以知道微服务之间的调用关系是很有必要的。Spring Cloud Sleuth + Zipkin为这种调用链跟踪提供了很好的解决方案。Sleuth负责日志的生成,Zipkin负责对日志的收集和解析。
真实应用前,有必要了解一下Sleuth中的三个重要的概念:
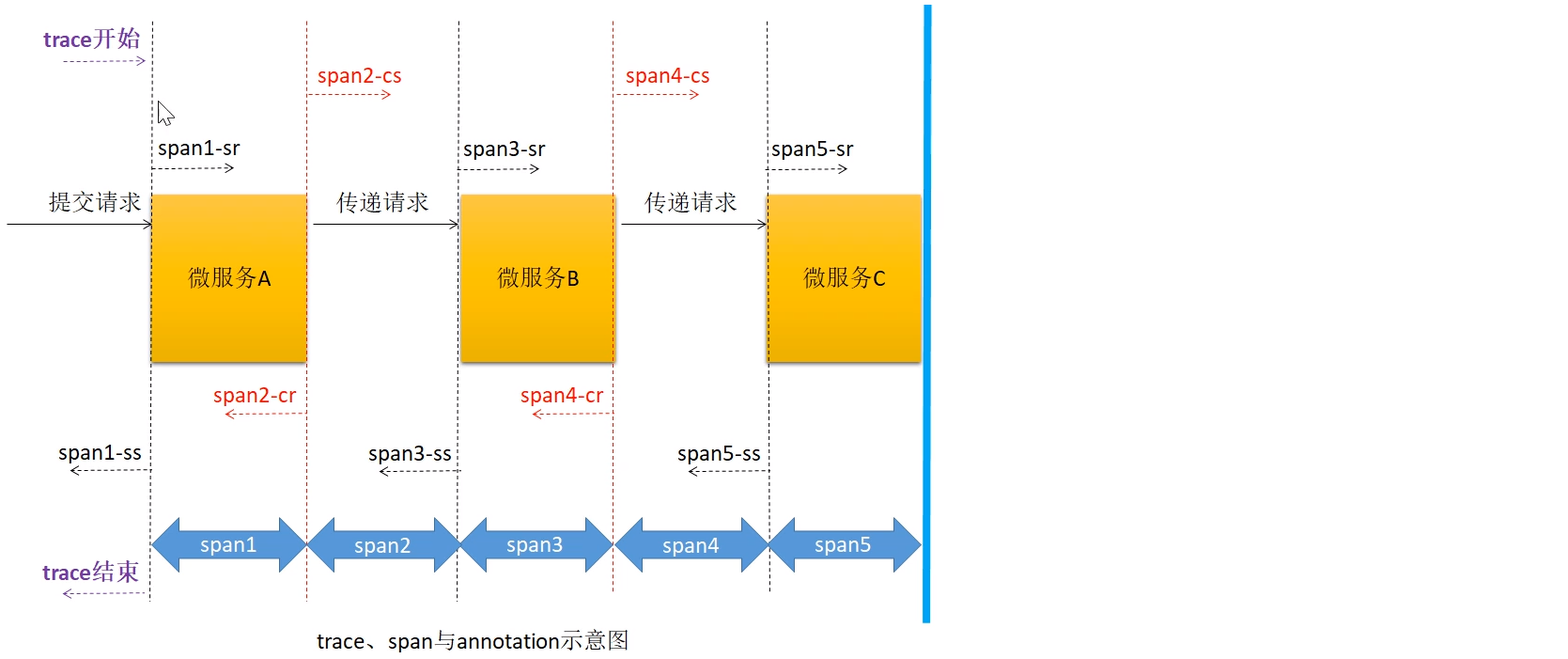
①trace:服务调用的整个过程。
②span:每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用所消耗的时间等信息,在每次调用服务时,埋入一个调用记录,这样两个调用记录之间的区域称为一个 span。
关系:一个 Trace 由若干个有序的 Span 组成。
Spring Cloud Sleuth 为服务之间调用提供链路追踪功能。为了唯一的标识 trace 与 span,系统为每个 trace 与 span 都指定了一个 64 位长度的数字作为 ID,即 traceID 与 spanID。
③annotation:用于及时记录事件的实体,表示一个事件发生的时间点。这些实体本身仅仅是为了原理
叙述的方便,对于 Spring Cloud Sleuth 本身并没有什么必要性。这样的实体有多个,常用的有四个:
cs:Client Send,表示客户端发送请求的时间点。
sr,Server Receive,表示服务端接收到请求的时间点。
ss:Server Send,表示服务端发送响应的时间点。
cr:Client Receive,表示客户端接收到服务端响应的时间点。
通过这些span、annotation信息我们就可以分析出服务调用链路,以及耗时情况。后面通过Zipkin可视化看到。
(1)日志生成
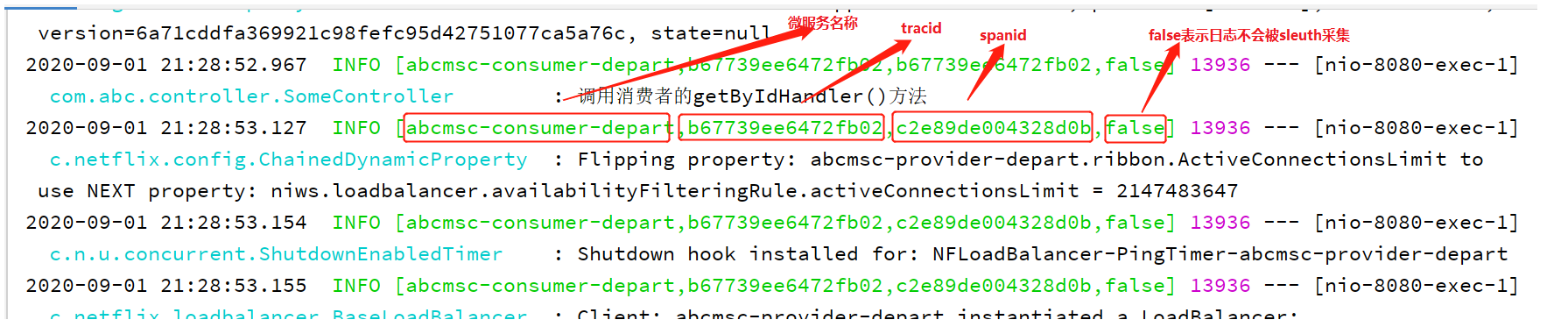
只要在工程中添加了 Spring Cloud Sleuth 依赖, 那么工程在启动与运行过程中就会自动生成很多的日志。Sleuth 会为日志信息打上收集标记,需要收集的设置为 true,不需要的设置为 false。这个标记可以通过在代码中添加自己的日志信息看到。
(2)日志采样率
Sleuth 对于这些日志支持抽样收集,即并不是所有日志都会上传到日志收集服务器,日志收集标记就起这个作用。默认的采样比例为: 0.1,即 10%。在配置文件中可以修改该值。若设置为 1 则表示全部采集,即 100%。
Sleuth 默认采用的是水塘抽样算法。
Sleuth日志采样
为Consumer、Provider添加依赖:
<!--sleuth依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!--日志打印依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
添加一点日志打印:
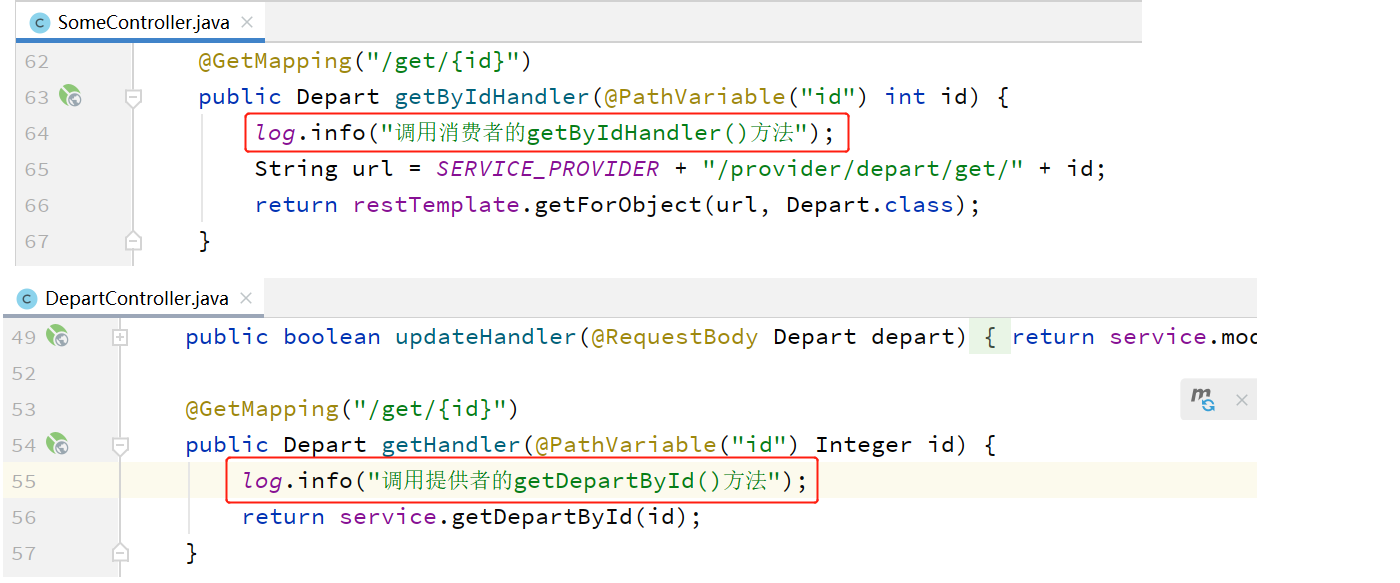
运行服务可以看到一些日志信息。
Zipkin日志收集
工作流程:
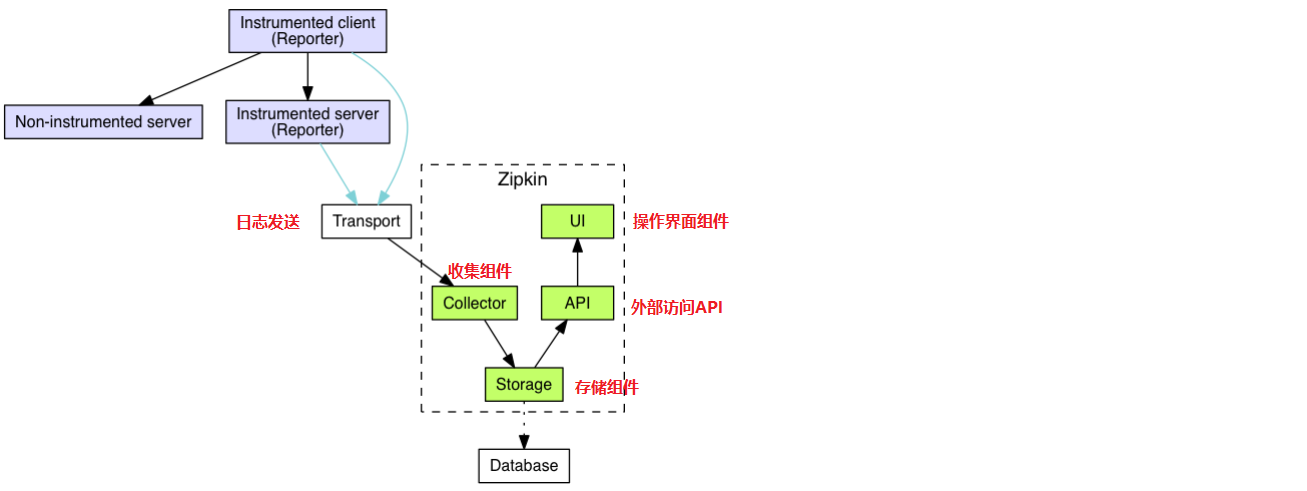
两种日志发送方式:
在 Spring Cloud Sleuth + Zipkin 系统中,客户端中一旦发生服务间的调用,就会被配置在微服务中的 Sleuth 的监听器监听,然后生成相应的 Trace 和 Span 等日志信息,并发送给Zipkin 服务端。发送的方式主要有两种,一种是通过 via HTTP 报文的方式,这也是默认方式,也可以通过 Kafka、RabbitMQ 发送。
Sleuth + Zipkin
(1)下载安装启动Zipkin
参考官网:https://zipkin.io/pages/quickstart.html
(2)访问Zipkin服务器
暂时还没有数据。
(3)修改Consumer、Provider
导入依赖:
<!--sleuth依赖-->
<!--<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>-->
<!--zipkin客户端依赖,其包含了 sleuth依赖,所以去掉spring-cloud-starter-sleuth-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置Zipkin服务器:

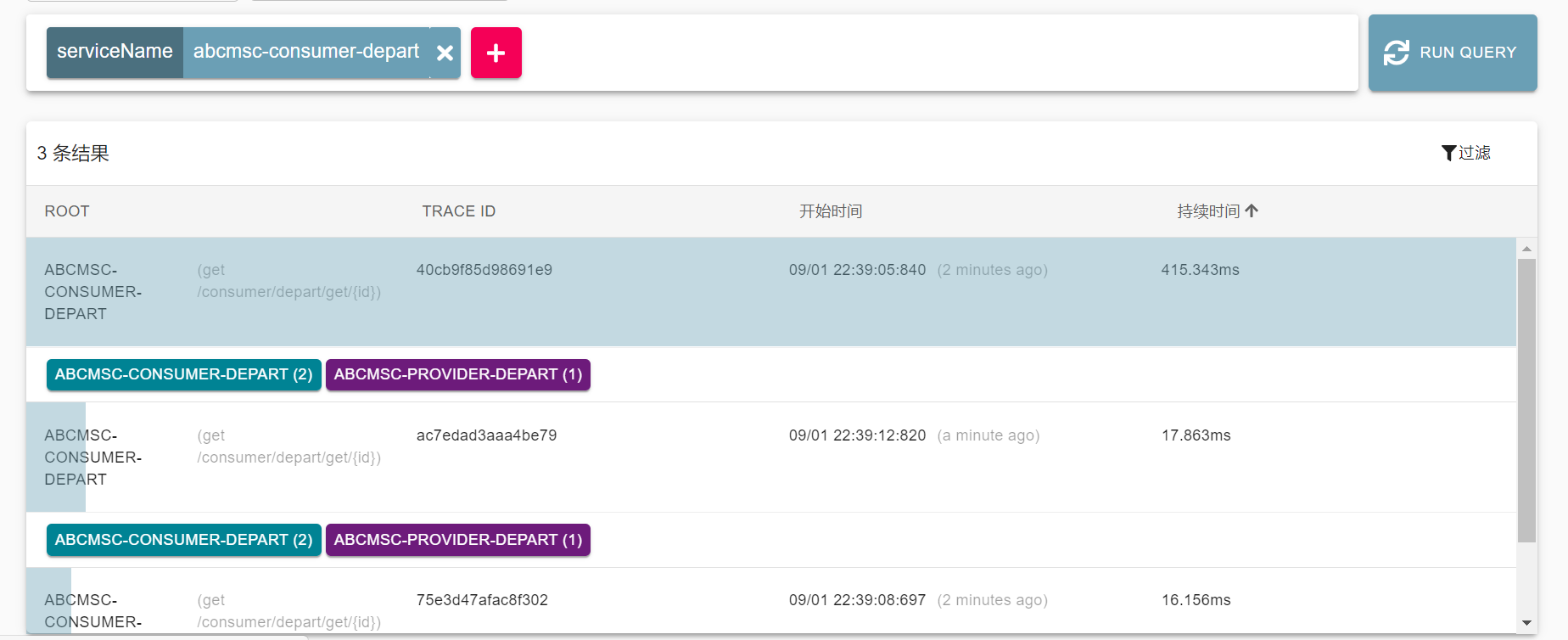
(4)通过zipkin查看调用情况
调用服务查看Zipkin服务器的监控记录:
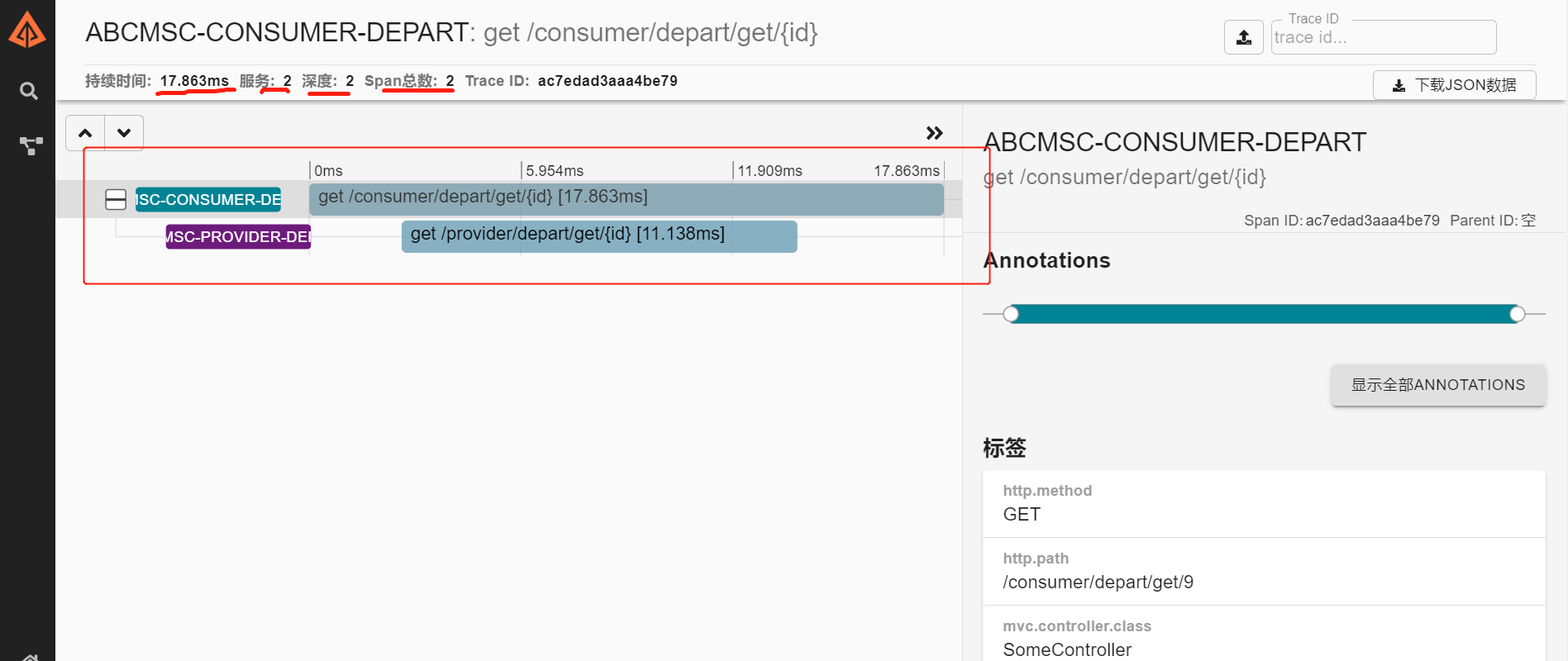
点开其中某一条,可以看到调用链路,调用耗时等,还是比较直观的:
Sleuth + Kafka + Zipkin

此时:Consumer、Provider、Zipkin都是kafka的客户端了。Consumer、Provider相当于是生产者,Zipkin相当于是消费者。
Consumer、Provider添加依赖:
<!--kafka依赖-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
Consumer、Provider修改配置:(不用直接连接zipkin,而是连接kafka。)
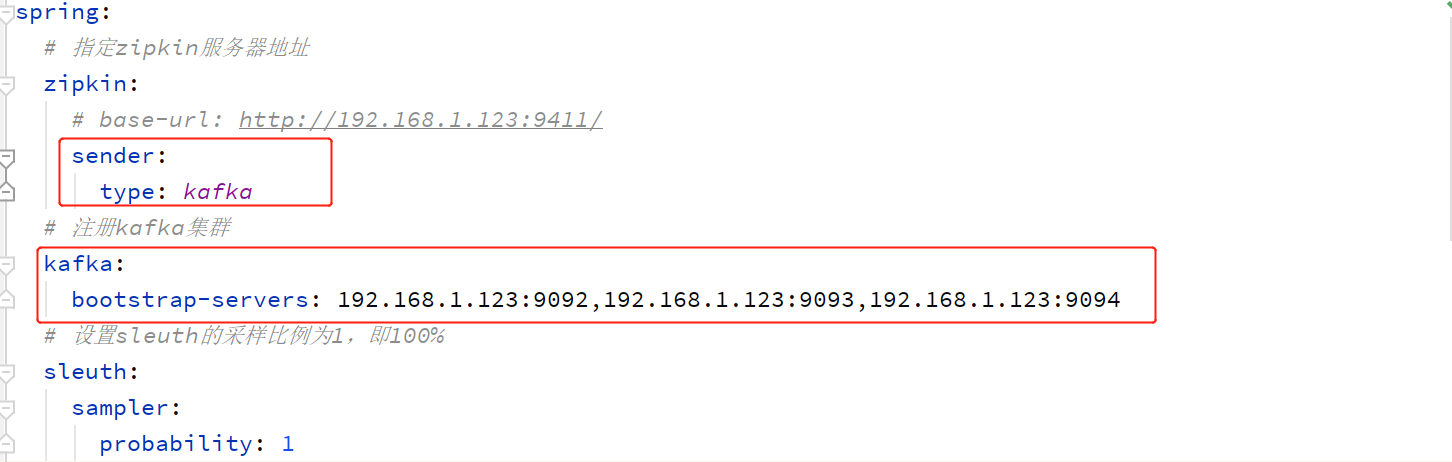
Zipkin启动需要注意指定kafka:
// 如果使用的是jar包启动需要使用-D指定kafka地址
java -DKAFKA_BOOTSTRAP_SERVERS=192.168.1.123:9092 –jar zipkin.jar
// 如果使用的是docker容器需要使用-e指定kafka地址
docker run -d -p 9411:9411 -e KAFKA_BOOTSTRAP_SERVERS=192.168.1.123:9092 openzipkin/zipkin
十二、消息系统整合框架Spring Cloud Stream

简单来说,是一款轻量级的用于构建应用之间连接的事件驱动微服务框架。主要是用于简化消息中间件的使用,支持Kafka和RabbitMQ。
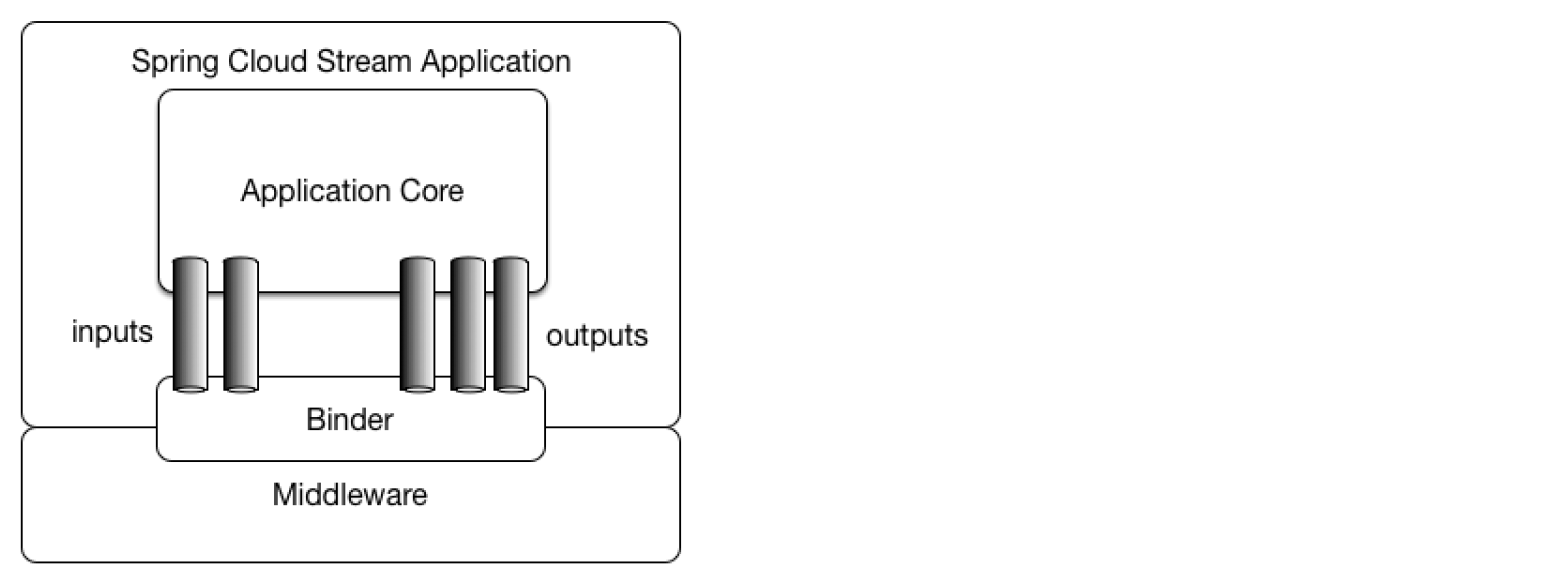
应用程序通过管道(inputs,outputs)的方式与消息中间件(Middelware)进行绑定(Binder),从而实现应用(Application)之间的消息通讯。
一个管道绑定一个主题。
下面以Kafka为例实现:
实现生产者
- 导入 spring-cloud-stream-binder-kafka 依赖
- 创建生产者类。在生产者类上添加@EnableBinding()注解,并声明管道
- 定义处理器,在处理器中调用消息生产者,使其发送消息
- 在配置文件中注册 kafka 集群,并指定管道所绑定的主题及类型
导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
定义生产者SomeProducer.java
package com.abc.producer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Component;
@Component
// Source是spring cloud中的一个默认输出管道
// 将kafka与生产者类通过管道进行绑定
@EnableBinding(Source.class)
public class SomeProducer {
//必须使用byName注入管道,因为系统还定义了名称为nullChannel和errorChannel的两个同类型管道
@Autowired
@Qualifier(Source.OUTPUT)
private MessageChannel channel;
public boolean sendMsg(String message) {
// 通过消息管道发送消息
return channel.send(MessageBuilder.withPayload(message).build());
}
}
定义业务类SomeController.java
package com.abc.controller;
import com.abc.producer.SomeProducer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class SomeController {
// 注入消息生产者
@Autowired
private SomeProducer producer;
@PostMapping("/send/msg")
public String postHandler(@RequestParam("message")String msg) {
return producer.sendMsg(msg) ? "message send success" : "message send failure";
}
}
配置文件application.yml
server:
port: 1111
spring:
cloud:
stream:
kafka:
binder:
# 指定kafka集群。其他属性参考KafkaBinderConfigurationProperties.java
brokers: 192.168.1.123:9092,192.168.1.123:9093,192.168.1.123:9094
bindings:
# 将管道与主题绑定
output:
# 指定Topic名称,消息类型(配置参考BindingProperties.java)
destination: citys
content-type: text/plain
启动测试(消费者先使用命令行方式)
可以看到主题已经创建:

使用postman发送消息:
命令行消息接收:

发送给多个主题
前面提过一点:一个管道只能绑定一个主题。所以,要想发送给多个Topic,我们就需要指定多个管道,然后为每个管道指定不同的主题。我们仿造Source自定义一个管道。
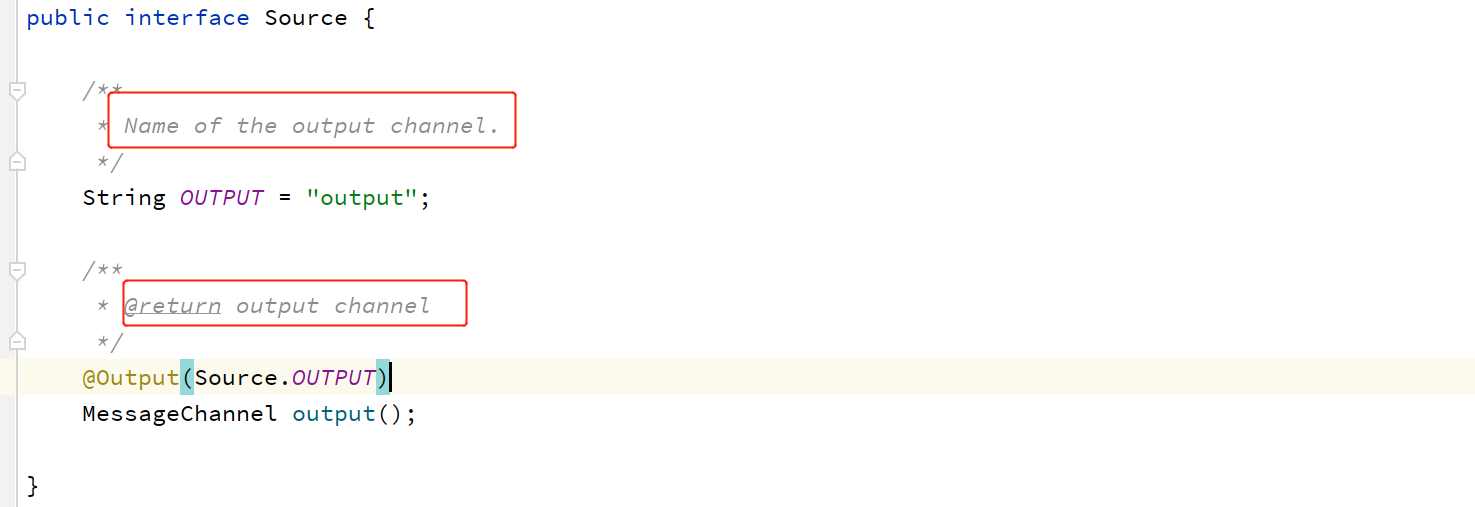
自定义一个管道

修改生产者
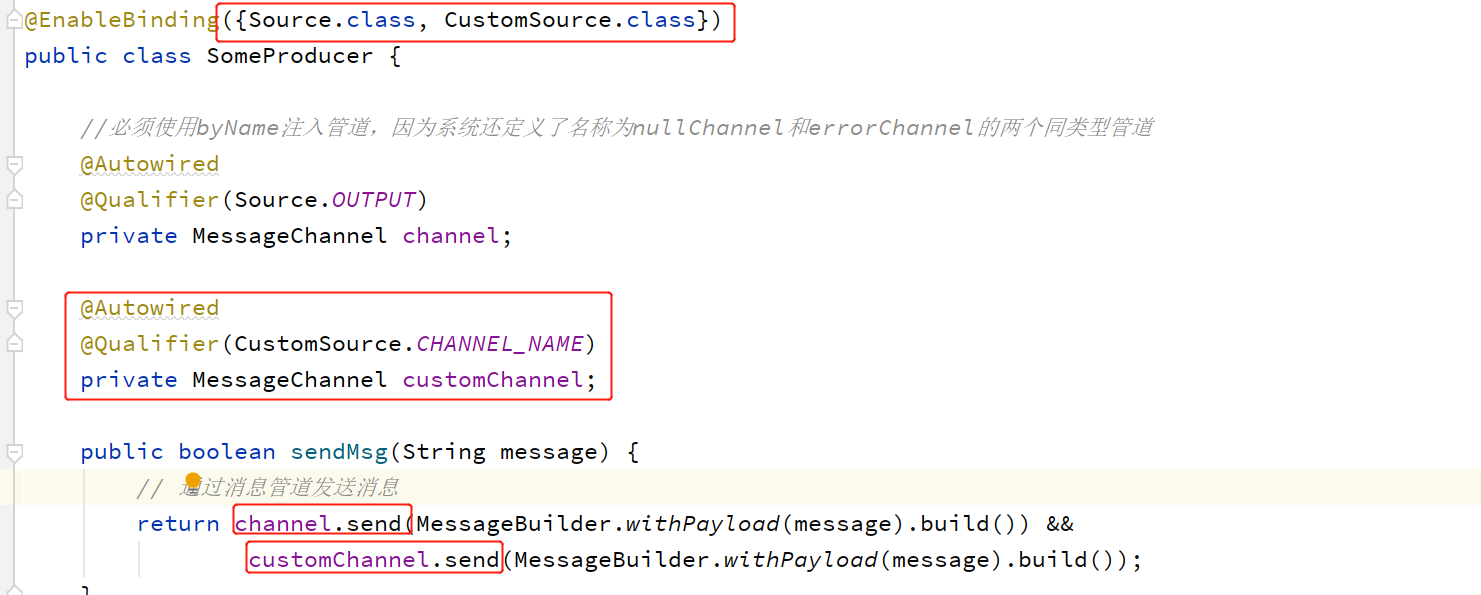
修改配置文件增加一个主题

发送消息测试
两个主题都可以接受到消息。


实现消费者
Spring Cloud Stream 提供了三种创建消费者的方式,这三种方式的都是在消费者类的“消费”方法上添加注解。只要有新的消息写入到了管道,该“消费”方法就会执行。只不过三种注解,其底层的实现方式不同。即当新消息到来后,触发“消费”方法去执行的实现方式不同。
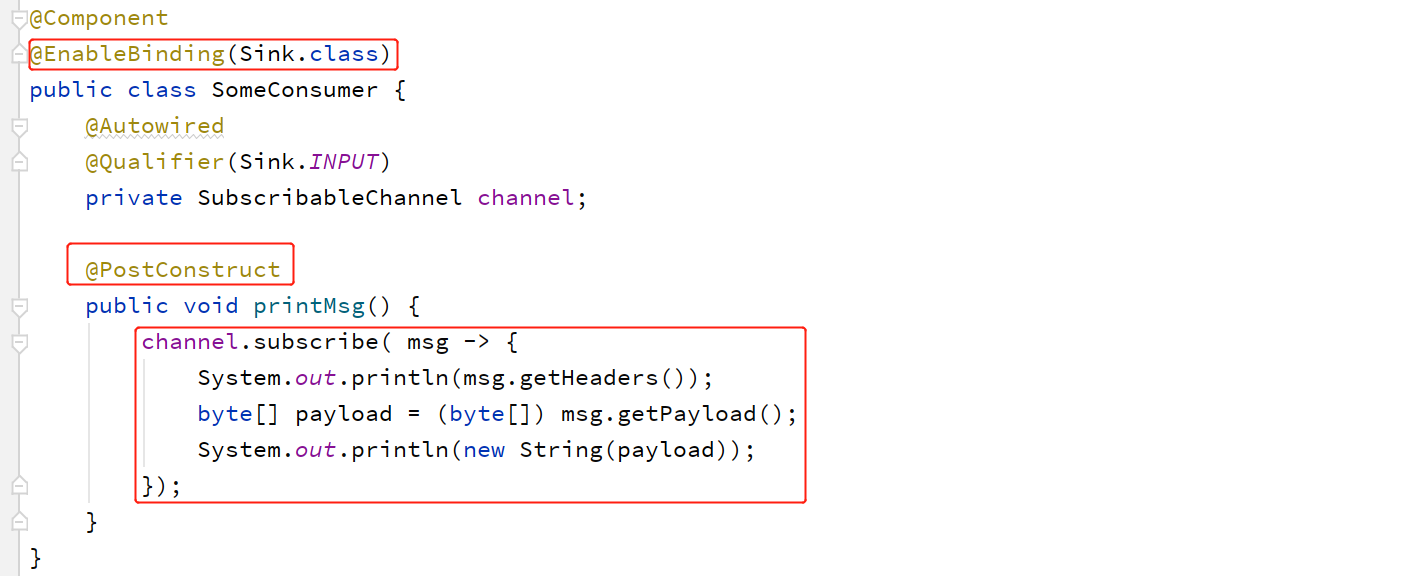
- @PostConstruct:以发布/订阅方式实现
- @ServiceActivator:以新消息激活服务的方式实现
- @StreamListener:以监听方式实现
配置和生产者类似。这里简单起见直接在同一个工程中实现。
(1)方式一:@PostConstruct

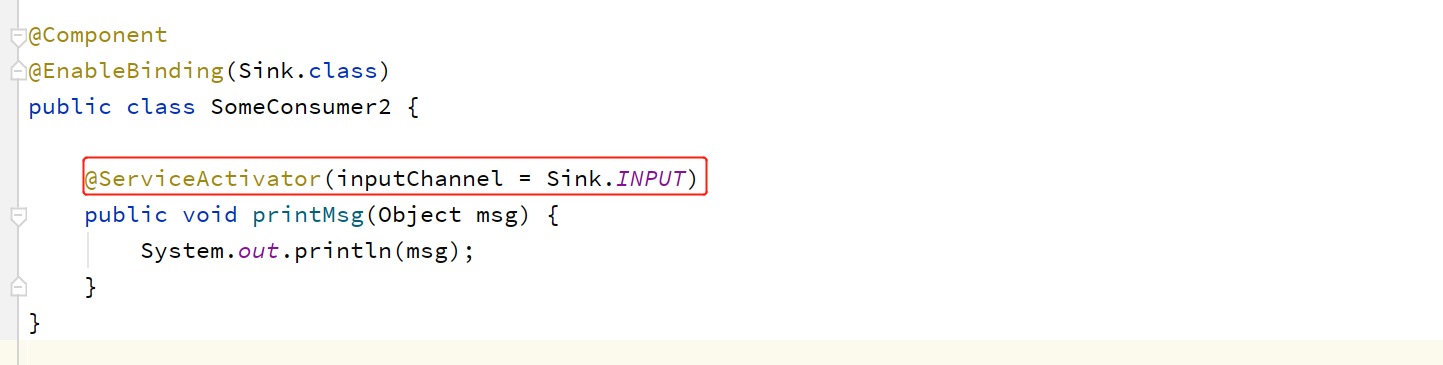
(2)方式二:@ServiceActivator
该注解所标注的方法是以服务的形式出现的,只要管道中的数据发生了变化就会激活该服务。
(3)方式三:@StreamListener
该方式是以监听的方式实现,只要管道中的流数据发生变化,其就会触发该注解所标注的方法的执行。

以上就是Spring Cloud中的常用组件,基本满足日常使用。查阅官网可了解更多组件: