一、介绍
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录 FOREIGN KEY (FK) 标识该字段为该表的外键 NOT NULL 标识该字段不能为空 UNIQUE KEY (UK) 标识该字段的值是唯一的 AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键) DEFAULT 为该字段设置默认值 UNSIGNED 无符号 ZEROFILL 使用0填充
说明:
1,是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值 2,字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值 sex enum('male','female') not null default 'male' age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20 3,是否是key 主键 primary key 外键 foreign key 索引 (index,unique...)
二、not null 与 default
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1( nid int not null defalut 2, num int not null )
验证:
1)not null
==================not null==================== mysql> create table t1(id int); # id字段默认可以插入空 mysql> desc t1; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ mysql> insert into t1 values(); # 可以插入空 mysql> create table t2(id int not null); # 设置字段id不为空 mysql> desc t2; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | +-------+---------+------+-----+---------+-------+ mysql> insert into t2 values(); # 不能插入空 ERROR 1364 (HY000): Field 'id' doesn't have a default value
2)default
==================default==================== #设置id字段有默认值后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值 mysql> create table t3(id int default 1); # 插入空值,会变成默认值 1 mysql> alter table t3 modify id int not null default 1; # 改成不为空,但如果插入空值,还是会变成默认值 1 ==================综合练习==================== mysql> create table student( -> name varchar(20) not null, -> age int(3) unsigned not null default 18, -> sex enum('male','female') default 'male', -> hobby set('play','study','read','music') default 'play,music' -> ); mysql> desc student; +-------+------------------------------------+------+-----+------------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+------------------------------------+------+-----+------------+-------+ | name | varchar(20) | NO | | NULL | | | age | int(3) unsigned | NO | | 18 | | | sex | enum('male','female') | YES | | male | | | hobby | set('play','study','read','music') | YES | | play,music | | +-------+------------------------------------+------+-----+------------+-------+ mysql> insert into student(name) values('zixi'); mysql> select * from student; +------+-----+------+------------+ | name | age | sex | hobby | +------+-----+------+------------+ | zixi | 18 | male | play,music | +------+-----+------+------------+
三、unique
设置唯一约束:
1)单列唯一(单列主键)
# 单列唯一,单列主键
============设置唯一约束 UNIQUE=============== 方法一: create table department1( # 存放部门信息 id int, name char(20) unique, # 部门名不能重复,设置唯一 comment char(100) ); 方法二: create table department2( id int, name varchar(20), comment varchar(100), unique(name) # 单列唯一 ); mysql> insert into department1 values(1,'IT','技术'); Query OK, 1 row affected (0.00 sec) mysql> insert into department1 values(1,'IT','技术'); ERROR 1062 (23000): Duplicate entry 'IT' for key 'name'
not null + unique 的化学反应:
mysql> create table t1(id int not null unique); Query OK, 0 rows affected (0.02 sec) mysql> desc t1; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | +-------+---------+------+-----+---------+-------+ 1 row in set (0.00 sec)
2)联合唯一(多列唯一):
mysql> create table service( -> id int, -> name char(20), -> ip char(15) not null, -> port int not null, -> unique(ip,port) # 联合唯一 -> ); Query OK, 0 rows affected (0.30 sec) mysql> desc service; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | char(20) | YES | | NULL | | | ip | char(15) | NO | PRI | NULL | | | port | int | NO | PRI | NULL | | +-------+----------+------+-----+---------+-------+ 4 rows in set (0.00 sec) mysql> insert into service values -> (1,'nginx','192.168.0.10',80), -> (2,'haproxy','192.168.0.20',80), -> (3,'mysql','192.168.0.30',3306); Query OK, 3 rows affected (0.07 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> insert into service(name,host,port) values('nginx','192.168.0.10',80); ERROR 1054 (42S22): Unknown column 'host' in 'field list' mysql>
四、primary key
从约束角度看 primary key字段的值不为空且唯一,那我们直接使用 not null + unique不就可以了吗,要它干什么?
主键 primary key是 innodb存储引擎组织数据的依据,innodb称之为索引组织表,一张表中必须有且只有一个主键,主键可以帮你组织表的数据,可以提高查询速度。
一个表中可以:
1,单列做主键:
============单列做主键=============== # 方法一:not null+unique create table department1( id int not null unique, # 主键 name varchar(20) not null unique, comment varchar(100) ); mysql> desc department1; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | NO | UNI | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec) # 方法二:在某一个字段后用 primary key create table department2( id int primary key, # 主键 name varchar(20), comment varchar(100) ); mysql> desc department2; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.00 sec) # 方法三:在所有字段后单独定义 primary key create table department3( id int, name varchar(20), comment varchar(100), constraint pk_name primary key(id); # 创建主键并为其命名pk_name mysql> desc department3; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec)
2,复合主键(多列做主键)
==================多列做主键================ create table service( ip varchar(15), port char(5), service_name varchar(10) not null, primary key(ip,port) ); mysql> desc service; +--------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------+-------------+------+-----+---------+-------+ | ip | varchar(15) | NO | PRI | NULL | | | port | char(5) | NO | PRI | NULL | | | service_name | varchar(10) | NO | | NULL | | +--------------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) mysql> insert into service values -> ('172.16.45.10','3306','mysqld'), -> ('172.16.45.11','3306','mariadb') -> ; Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> insert into service values ('172.16.45.10','3306','nginx'); ERROR 1062 (23000): Duplicate entry '172.16.45.10-3306' for key 'PRIMARY'
五、auto_increment
约束字段为自动增长,被约束的字段必须同时被 key约束。
# 不指定id,则自动增长 create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' ); mysql> desc student; +-------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | sex | enum('male','female') | YES | | male | | +-------+-----------------------+------+-----+---------+----------------+ mysql> insert into student(name) values -> ('zixi'), -> ('suos') -> ; mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 1 | zixi | male | | 2 | suos | male | +----+------+------+ # 也可以指定id mysql> insert into student values(4,'asb','female'); Query OK, 1 row affected (0.00 sec) mysql> insert into student values(7,'bsb','female'); Query OK, 1 row affected (0.00 sec) mysql> select * from student; +----+------+--------+ | id | name | sex | +----+------+--------+ | 1 | zixi | male | | 2 | suos | male | | 4 | asb | female | | 7 | bsb | female | +----+------+--------+ # 对于自增的字段,在用 delete删除后,再插入值,该字段仍按照删除前的位置继续增长,delete 经常与 where连用。 mysql> delete from student; Query OK, 4 rows affected (0.00 sec) mysql> select * from student; Empty set (0.00 sec) mysql> insert into student(name) values('ysb'); mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 8 | ysb | male | +----+------+------+ # 应该用 truncate清空表,比起 delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它 mysql> truncate student; Query OK, 0 rows affected (0.01 sec) mysql> insert into student(name) values('zixi'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 1 | zixi | male | +----+------+------+ 1 row in set (0.00 sec)
步长:auto_increment_increment,起始偏移量:auto_increment_offset (了解)
# 在创建完表后,修改自增字段的起始值 mysql> create table student( -> id int primary key auto_increment, -> name varchar(20), -> sex enum('male','female') default 'male' -> ); mysql> alter table student auto_increment=3; mysql> show create table student; ....... ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 mysql> insert into student(name) values('egon'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 3 | egon | male | +----+------+------+ row in set (0.00 sec) mysql> show create table student; ....... ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 # 也可以创建表时指定auto_increment的初始值,注意初始值的设置为表选项,应该放到括号外 create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' )auto_increment=3; # 设置步长 sqlserver自增步长: # 基于表级别 create table t1( id int。。。 )engine=innodb,auto_increment=2 步长=2 default charset=utf8 mysql自增的步长: show session variables like 'auto_inc%'; # 基于会话级别 set session auth_increment_increment=2 # 修改会话级别的步长 # 基于全局级别的 set global auth_increment_increment=2 # 修改全局级别的步长(所有会话都生效) # !!!注意了注意了注意了!!! If the value of auto_increment_offset is greater than that of auto_increment_increment, the value of auto_increment_offset is ignored. 翻译:如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值会被忽略 ,这相当于第一步步子就迈大了,扯着了蛋 比如:设置auto_increment_offset=3,auto_increment_increment=2 mysql> set session auto_increment_increment=5; # session 本次会话 Query OK, 0 rows affected (0.00 sec) mysql> set global auto_increment_offset=3; # global 全局,需要 exit退出,重新加载一边,才好用 Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'auto_in%'; # 查变量, % 是任意字符的所有变量 +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' ); mysql> insert into student(name) values('zixi1'),('zixi2'),('zixi3'); mysql> select * from student; +----+-------+------+ | id | name | sex | +----+-------+------+ | 3 | zixi1 | male | | 8 | zixi2 | male | | 13 | zixi3 | male | +----+-------+------+
六、foreign key(外键)
1,快速理解 foreign key:
建立表之间的关系
员工信息表有三个字段:工号 姓名 部门
公司有3个部门,但是有 1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费
解决方法:
我们完全可以定义一个部门表
然后让员工信息表关联该表,如何关联,即 foreign key
最好是从逻辑意义上实现两张表之间的关系,从应用程序中控制,不要在数据库中把表建上硬性关系,把两张表耦合到一起了,写项目的时候,首先是设计表和结构,把表之间的关联关系做好,一旦用 外键做这种硬性的关系,意味着所有的表被你强耦合到一起了,一旦以后涉及到扩展,会非常麻烦。
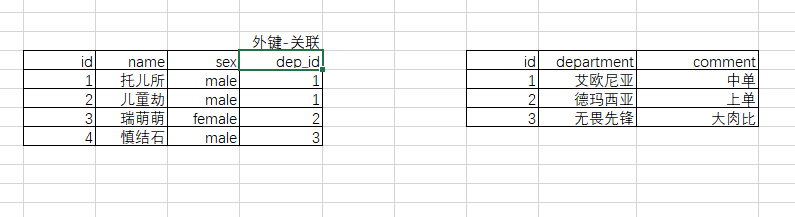
示范:
# 1,建立表关系
# 表类型必须是 innodb存储引擎,且被关联的字段,即 references指定的另外一个表的字段,必须保证唯一 create table department( id int primary key, name varchar(20) not null )engine=innodb; # dpt_id外键,关联父表(department主键id),同步更新,同步删除 create table employee( id int primary key, name varchar(20) not null, dpt_id int, constraint fk_name foreign key(dpt_id) references department(id) on delete cascade # 删除同步 on update cascade # 更新同步 )engine=innodb;
# 2,往表中插入数据 # 先往父表 department中插入记录 insert into department values (1,'艾欧尼亚'), (2,'德玛西亚'), (3,'无畏先锋'); # 再往子表 employee中插入记录 insert into employee values (1,'suos',1), (2,'zixi1',2), (3,'zixi2',2), (4,'zixi3',2), (5,'李坦克',3), (6,'刘飞机',3), (7,'张火箭',3), (8,'林子弹',3), (9,'加特林',3) ; # 删父表 department,子表 employee中对应的记录跟着删 mysql> delete from department where id=3; mysql> select * from employee; +----+-------+--------+ | id | name | dpt_id | +----+-------+--------+ | 1 | suos | 1 | | 2 | zixi1 | 2 | | 3 | zixi2 | 2 | | 4 | zixi3 | 2 | +----+-------+--------+ # 更新父表 department,子表 employee中对应的记录跟着改 mysql> update department set id=22222 where id=2; mysql> select * from employee; +----+-------+--------+ | id | name | dpt_id | +----+-------+--------+ | 1 | suos | 1 | | 3 | zixi2 | 22222 | | 4 | zixi3 | 22222 | | 5 | zixi1 | 22222 | +----+-------+--------+
2,如何找出两张表之间的关系
分析步骤: # 1、先站在左表的角度去找 是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
# 多个员工对应一个部门,而多个部门不能对应一个员工(大公司) # 2、再站在右表的角度去找 是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id) # 3、总结: # 多对一: 如果只有步骤1成立,则是左表多对一右表 如果只有步骤2成立,则是右表多对一左表 # 多对多 如果步骤1和2同时成立,则证明这两张表是一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系 # 一对一: 如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
3,建立表之间的关系
1)多对一
# 一对多或称为多对一 三张表:出版社,作者信息,书 一对多(或多对一):一个出版社可以出版多本书 关联方式:foreign key
===================== 多对一 =====================
# 出版社 create table press( id int primary key auto_increment, name varchar(20) );
# 书 create table book( id int primary key auto_increment, name varchar(20), press_id int not null, foreign key(press_id) references press(id) on delete cascade on update cascade ); insert into press(name) values ('北京工业地雷出版社'), ('人民音乐不好听出版社'), ('知识产权没有用出版社') ; insert into book(name,press_id) values ('九阳神功',1), ('九阴真经',2), ('九阴白骨爪',2), ('独孤九剑',3), ('降龙十巴掌',2), ('葵花宝典',3) ;
其他例子:
一夫多妻制 # 妻子表的丈夫id外键到丈夫表的id
2)多对多
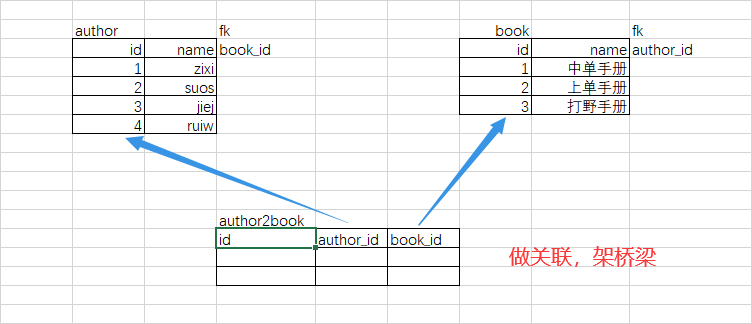
# 多对多 三张表:出版社,作者信息,书 多对多:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多 关联方式:foreign key+一张新的表
=====================多对多===================== create table author( id int primary key auto_increment, name varchar(20) ); # 这张表就存放作者表与书表的关系,即查询二者的关系查这表就可以了 create table author2book( id int not null unique auto_increment, author_id int not null, book_id int not null, constraint fk_author foreign key(author_id) references author(id) on delete cascade on update cascade, constraint fk_book foreign key(book_id) references book(id) on delete cascade on update cascade, primary key(author_id,book_id) ); # 插入四个作者,id依次排开 insert into author(name) values('zixi'),('suos'),('jiej'),('ruiw'); # 每个作者与自己的代表作如下 1 zixi: 1 九阳神功 2 九阴真经 3 九阴白骨爪 4 独孤九剑 5 降龙十巴掌 6 葵花宝典 2 suos: 1 九阳神功 6 葵花宝典 3 jiej: 4 独孤九剑 5 降龙十巴掌 6 葵花宝典 4 ruiw: 1 九阳神功 insert into author2book(author_id,book_id) values (1,1), (1,2), (1,3), (1,4), (1,5), (1,6), (2,1), (2,6), (3,4), (3,5), (3,6), (4,1) ;
其他例子:
# 单张表:用户表+相亲关系表,相当于:用户表+相亲关系表+用户表 # 多张表:用户表+用户与主机关系表+主机表 # 中间那一张存放关系的表,对外关联的字段可以联合唯一
3)一对一
# 一对一 两张表:学生表和客户表 一对一:一个学生是一个客户,一个客户有可能变成一个学校,即一对一的关系 关联方式:foreign key + unique
# 一定是 student来 foreign key表 customer,这样就保证了: # 1 学生一定是一个客户, # 2 客户不一定是学生,但有可能成为一个学生 create table customer( id int primary key auto_increment, name varchar(20) not null, qq varchar(10) not null, phone char(16) not null ); create table student( id int primary key auto_increment, class_name varchar(20) not null, customer_id int unique, # 该字段一定要是唯一的 foreign key(customer_id) references customer(id) # 外键的字段一定要保证unique on delete cascade on update cascade ); # 增加客户 insert into customer(name,qq,phone) values ('李飞机','31811231',13811341220), ('王大炮','123123123',15213146809), ('守榴弹','283818181',1867141331), ('吴坦克','283818181',1851143312), ('赢火箭','888818181',1861243314), ('战地雷','112312312',18811431230) ; # 增加学生 insert into student(class_name,customer_id) values ('脱产3班',3), ('周末19期',4), ('周末19期',5) ;
其他例子:
例一:一个用户只有一个博客 用户表: id name 1 zixi 2 suos 3 jiej 博客表 fk+unique id url name_id 1 xxxx 1 2 yyyy 3 3 zzz 2 例二:一个管理员唯一对应一个用户 用户表: id user password 1 zixi xxxx 2 suos yyyy 管理员表: fk+unique id user_id password 1 1 xxxxx 2 2 yyyyy
七、作业
练习:账号信息表,用户组,主机表,主机组


#用户表 create table user( id int not null unique auto_increment, username varchar(20) not null, password varchar(50) not null, primary key(username,password) ); insert into user(username,password) values ('root','123'), ('egon','456'), ('alex','alex3714') ; #用户组表 create table usergroup( id int primary key auto_increment, groupname varchar(20) not null unique ); insert into usergroup(groupname) values ('IT'), ('Sale'), ('Finance'), ('boss') ; #主机表 create table host( id int primary key auto_increment, ip char(15) not null unique default '127.0.0.1' ); insert into host(ip) values ('172.16.45.2'), ('172.16.31.10'), ('172.16.45.3'), ('172.16.31.11'), ('172.10.45.3'), ('172.10.45.4'), ('172.10.45.5'), ('192.168.1.20'), ('192.168.1.21'), ('192.168.1.22'), ('192.168.2.23'), ('192.168.2.223'), ('192.168.2.24'), ('192.168.3.22'), ('192.168.3.23'), ('192.168.3.24') ; #业务线表 create table business( id int primary key auto_increment, business varchar(20) not null unique ); insert into business(business) values ('轻松贷'), ('随便花'), ('大富翁'), ('穷一生') ; #建关系:user与usergroup create table user2usergroup( id int not null unique auto_increment, user_id int not null, group_id int not null, primary key(user_id,group_id), foreign key(user_id) references user(id), foreign key(group_id) references usergroup(id) ); insert into user2usergroup(user_id,group_id) values (1,1), (1,2), (1,3), (1,4), (2,3), (2,4), (3,4) ; #建关系:host与business create table host2business( id int not null unique auto_increment, host_id int not null, business_id int not null, primary key(host_id,business_id), foreign key(host_id) references host(id), foreign key(business_id) references business(id) ); insert into host2business(host_id,business_id) values (1,1), (1,2), (1,3), (2,2), (2,3), (3,4) ; #建关系:user与host create table user2host( id int not null unique auto_increment, user_id int not null, host_id int not null, primary key(user_id,host_id), foreign key(user_id) references user(id), foreign key(host_id) references host(id) ); insert into user2host(user_id,host_id) values (1,1), (1,2), (1,3), (1,4), (1,5), (1,6), (1,7), (1,8), (1,9), (1,10), (1,11), (1,12), (1,13), (1,14), (1,15), (1,16), (2,2), (2,3), (2,4), (2,5), (3,10), (3,11), (3,12) ;
作业: