Http
HTTP是hypertext transfer protocol(超文本传输协议)的简写,它是TCP/IP协议的一个应用层协议,用于定义WEB浏览器与WEB服务器之间交换数据的过程。
HTTP协议是学习JavaWEB开发的基石,不深入了解HTTP协议,就不能说掌握了WEB开发,更无法管理和维护一些复杂的WEB站点。
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
TCP/IP 协议族
为了了解HTTP,必须的了解TCP/IP协议族。
通常使用的网络实在TCP/IP协议族的基础上运作的。而HTTP就属于他的一个子集。
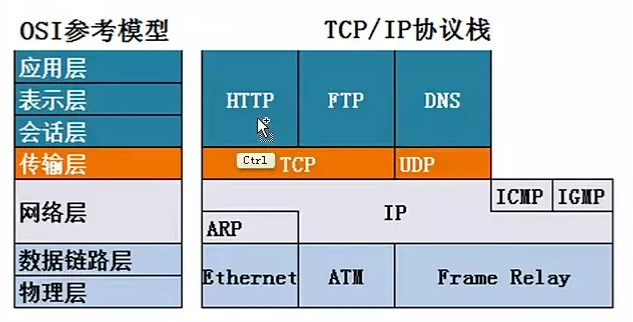
像这样把与互联网关联的协议集合起来总称TCP/IP,TCP/IP实在IP协议通信过程中,使用到的协议族的统称
- 应用层
应用层决定了向用户提供应用服务时通信的活动。比如:ftp,dns服务就是其中的两类。HTTP协议也处于该层。 - 传输层
传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。在传输层有两个性质不同的协议:TCP和UDP。 - 网络层
网络层用来处理网络上流动的数据包。数据包是网络传输的最小单位。该层规定了通过怎样的路径到达对方计算机,并把数据包发送给对方。 - 链路层
用来处理链接网络的硬件部分。包括操作系统、硬件的设备驱动、网卡及光纤等物理可见部分。
TCP/IP通信传输流
比如说我想看百度网页,流程如下:
- 客户端在应用层发出一个想看某个WEB页面的HTTP请求的时候;
- 接着为了传输方便,在传输层把应用层收到的数据进行分割,并在各个报文上打上标记序号及端口号后转发给网络层;
- 在网络层增加作为通信目的的MAC地址后转发给链路层,这样一来发送网络的通信请求就准备齐全了;
- 接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层;
- 当传输到应用层,才能算真正接收到由客户端发送过来的HTTP请求了。
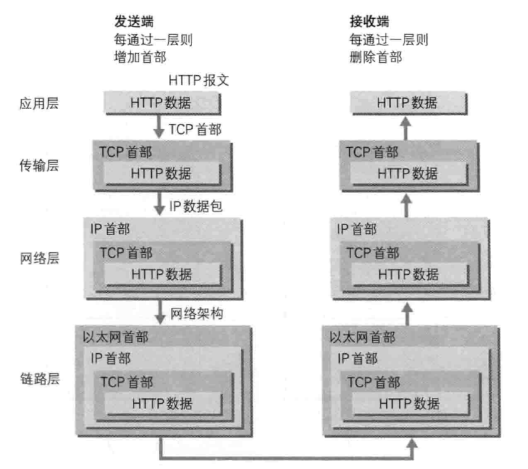
发送端在层与层之间传输数据时,每经过一层时必定会打上一个该层的首部信息。接收端没经过一层,会把消去。
URI和URL
URI用字符串标示某一互联网资源,而URL表示资源的地点。可见URL是URI的子集。
URI要使用涵盖全部必要信息的URI、绝对URL以及相对URL。相对URL是指从浏览器中基本URI处理的URL。
URI的格式如下:

HTTP 请求/响应的步骤
- 域名解析
- 检查浏览器自身DNS缓存 -> 操作系统DNS缓存 -> hosts文件 -> DNS解析
- 客户端连接到Web服务器
- 一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)发起tcp链接请求,经过3次握手后建立tcp连接
- 发送HTTP请求
- 通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
- 服务器接受请求并返回HTTP响应
- Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
- 释放连接TCP连接
- 若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
- 客户端浏览器解析HTML内容
- 客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接,如果设置了Connection:keep-alive则TCP连接不关闭;
- 浏览器(应用层)在得到HTML文件之后, 会按照规定的格式进行解析, 如果碰到链接的静态文件资源时, 浏览器便会另开多个线程去请求下载, 这是便会使用到HTTP协议的keep-alive特性了, 建立了一次HTTP连接,但是能够请求多个静态资源。
- 浏览器生成DOM并渲染, 边解析边渲染
服务器端响应完毕后,两者断开连接,也不保存连接状态,一刀两断!恩断义绝!从此路人!下一次客户端向同样的服务器发送请求时,由于他们之前已经遗忘了彼此,所以需要重新建立连接。
这就是Http的无状态特性。
这是为了处理大量事务,确保协议的可伸缩性,而特意吧HTTP协议设计成如此简单的。但是也存在弊端,当业务处理变得棘手的情况多了,比如用户登录一家网站,即使他跳转到别的页面后,也需要保持登录状态,然而cookie就诞生了。cookie可以标识区分到上次连接到服务器的客户端,有了cookie再用http协议通信,就可以管理状态了。
常见响应状态码
- 1**:指示信息–表示请求已接收,继续处理。
- 2**:成功–表示请求已被成功接收、理解、接受。
- 3**:重定向–要完成请求必须进行更进一步的操作。
- 4**:客户端错误–请求有语法错误或请求无法实现。
- 5**:服务器端错误–服务器未能实现合法的请求。
Http请求方法
HTTP/1.1协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
- GET
向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
- HEAD
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
- POST
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
- PUT
向指定资源位置上传其最新内容。
- DELETE
请求服务器删除Request-URI所标识的资源。
- TRACE
回显服务器收到的请求,主要用于测试或诊断。
- OPTIONS
这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
- CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
注意事项:
- 方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
- HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的。当然,所有的方法支持的实现都应当匹配下述的方法各自的语义定义。此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法。例如PATCH(由 RFC 5789 指定的方法)用于将局部修改应用到资源。
常见get和post的区别
| — | Get | Post |
|---|---|---|
| 语义规范 | 获取服务器上的资源的请求(查) | 可能修改服务器上的资源的请求(改) |
| url可见性 | 请求的数据放在url上,即HTTP协议头对所有人可见 | 请求的数据放在HTTP包体内,称请求头数据不会显示在url中 |
| 数据大小 [注1] | 提交的数据长度有限制 | 没有大小限制 |
| 可见安全性 | 相对Post不安全数据在url上,并保存在浏览器历史中 | 相对Get安全不会被保存在浏览器历史或服务器日志中 |
| 操作安全性 | 相对Post安全因为是等幂的,多次请求效果一样 | 相对Get不安全因为不是等幂的,多次请求都会改变结果 |
| 后退&刷新 | 无害 | 数据会重新提交,重复修改了资源(浏览器应当告知用户) |
| 缓存&书签 | 能被缓存与收藏为书签 | 不能缓存与不能收藏为书签 |
| 编码类型 | application/x-www-form-urlencoded(只能进行url编码) | application/x-www-form-urlencoded或 multipart/form-data(支持多种编码) |
| 数据类型 | 只允许ASCII字符 | 无限制(包括二进制) |
| 请求过程 [注2] | 产生一个TCP数据包 | 产生两个TCP数据包 |
[注1]:实际上,URL 不存在参数上限的问题,HTTP 协议规范没有对 URL 长度进行限制
这个限制是特定的浏览器和服务器对它设定的限制
不同浏览器
- IE: 长度限制是(2048+35),超过将自动截断,表单则提交按钮无效
- firefox: 长度限制是65,536字符,但实际上有效url长度不少于100,000字符
- chrome: 长度限制是8,182字符,超过将返回开头时列出错误
- Safari: 长度限制是80,000字符
- Opera: 长度限制是190,000字符
不同服务器
- Apache: 长度限制是8,192字符
- IIS: 长度限制是16,384字符,可以修改
- ngnix: 默认1K/4K,可以修改
- Perl HTTP::Daemon: 长度限制是8,000字符
但是Post还是没有大小限制
[注2]:
- 对于get请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据)
- 对于post请求,浏览器会发送header,服务器响应100(continue),浏览器再发送data,服务器响应200(返回数据)
Http1.0和Http1.1的区别
- HTTP1.1支持长连接(PersistentConnection)
- HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
- HTTP 1.1则支持持久连接(长连接), 并且默认使用。在同一个tcp的连接中可以传送多个HTTP请求和响应. 多个请求和响应可以重叠,多个请求和响应可以同时进行. 更加多的请求头和响应头(比如HTTP1.0没有host的字段)。
HTTP 1.1的持续连接,也需要增加新的请求头来帮助实现,例如:
Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;
Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接;
HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
-
请求的流水线(Pipelining)处理
- 请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。例如:一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。
- HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容。
-
HTTP 1.1增加host字段
- 在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
- HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。此外,服务器应该接受以绝对路径标记的资源请求。
-
新增100(Continue)Status
HTTP/1.1加入了一个新的状态码100(Continue)。客户端事先发送一个只带头域的请求,如果服务器因为权限拒绝了请求,就回送响应码401(Unauthorized);如果服务器接收此请求就回送响应码100,客户端就可以继续发送带实体的完整请求了。100 (Continue) 状态代码的使用,允许客户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。 -
Chunked transfer-coding
HTTP/1.1中引入了Chunked transfer-coding来解决上面这个问题,发送方将消息分割成若干个任意大小的数据块,每个数据块在发送时都会附上块的长度,最后用一个零长度的块作为消息结束的标志。这种方法允许发送方只缓冲消息的一个片段,避免缓冲整个消息带来的过载。 -
Cache缓存
HTTP/1.1在1.0的基础上加入了一些cache的新特性,当缓存对象的Age超过Expire时变为stale对象,cache不需要直接抛弃stale对象,而是与源服务器进行重新激活(revalidation)。