要进一步改进MNIST学习算法,需要对卷积神经网络进行学习和了解
学习材料参见https://www.cnblogs.com/skyfsm/p/6790245.html
卷积神经网络依旧是层级网络,只是层的功能和形式做了变化,可以说是传统网络的一个改进,多了许多神经网络没有的层次。
• 数据输入层/ Input layer
• 卷积计算层/ CONV layer
• ReLU激励层 / ReLU layer
• 池化层 / Pooling layer
• 全连接层 / FC layer
1.数据输入层
这层做的处理主要是对原始图像数据进行预处理,其中包括:
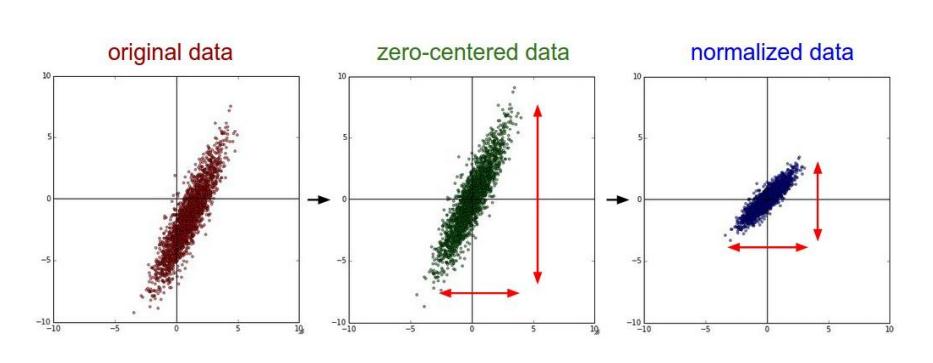
去均值:把输入数据各个维度都中心化为0,目的是把样本的中心拉回到坐标系原点上
归一化:幅度归一化到同样的范围,即减少各维度取值范围的差异而带来的干扰。
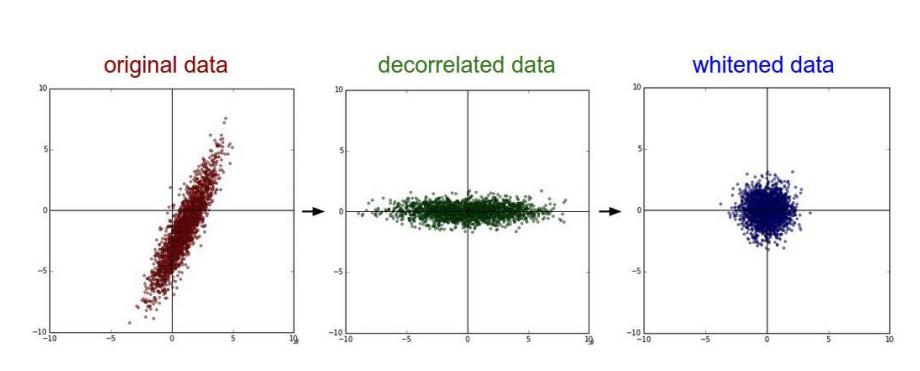
PCA/白化:用PCA降维,白化是对数据各个特征轴上的幅度归一化
去均值及归一化效果
去相关与白化效果
2.卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。它有两个关键操作
- 局部关联。每个神经元看做一个滤波器(filter)
- 窗口滑动,filter对局部数据进行计算
几个在卷积层常遇到的名词
- 深度depth
- 步长stride(窗口一次滑动的长度)
- 填充值zero-padding

什么是填充值?
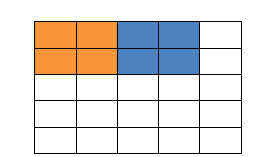 -----》
-----》
以该图为例,假如我们的滑动窗口取2*2,步长取2,那么发现还剩了一个像素没法识别进去,所以这时我们在原型的矩阵加了一层填充值,使得变成6*6的矩阵,那么窗口就可以刚好把所有像素遍历完。
卷积是怎么计算的?
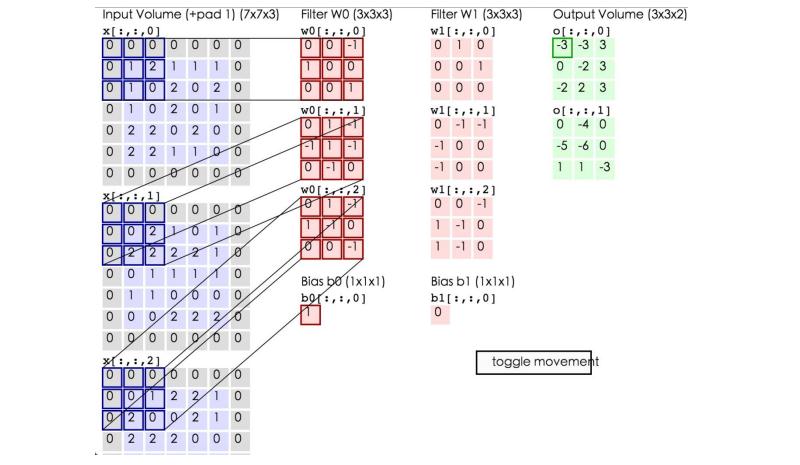
这里蓝色矩阵就是输入的图像(外面有一圈灰色的0,即填充值)。粉色矩阵就是卷积层的神经元,这里有两个神经元(w0,w1),注意最下面还有一个偏差值。绿色矩阵是经卷积运算后的输出矩阵,这里步长设置为2
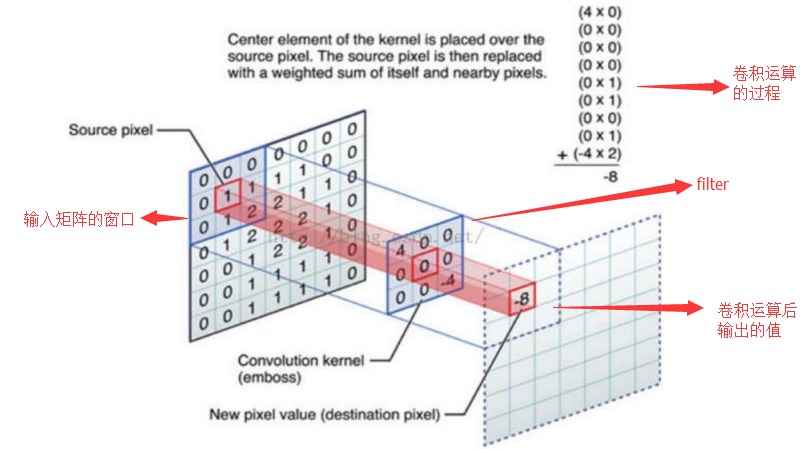
这张图显示了卷积计算的具体过程。蓝色矩阵对粉色矩阵进行内积运算,并把三个内积运算与偏差值b相加,计算后的值就是绿框矩阵的一个元素。
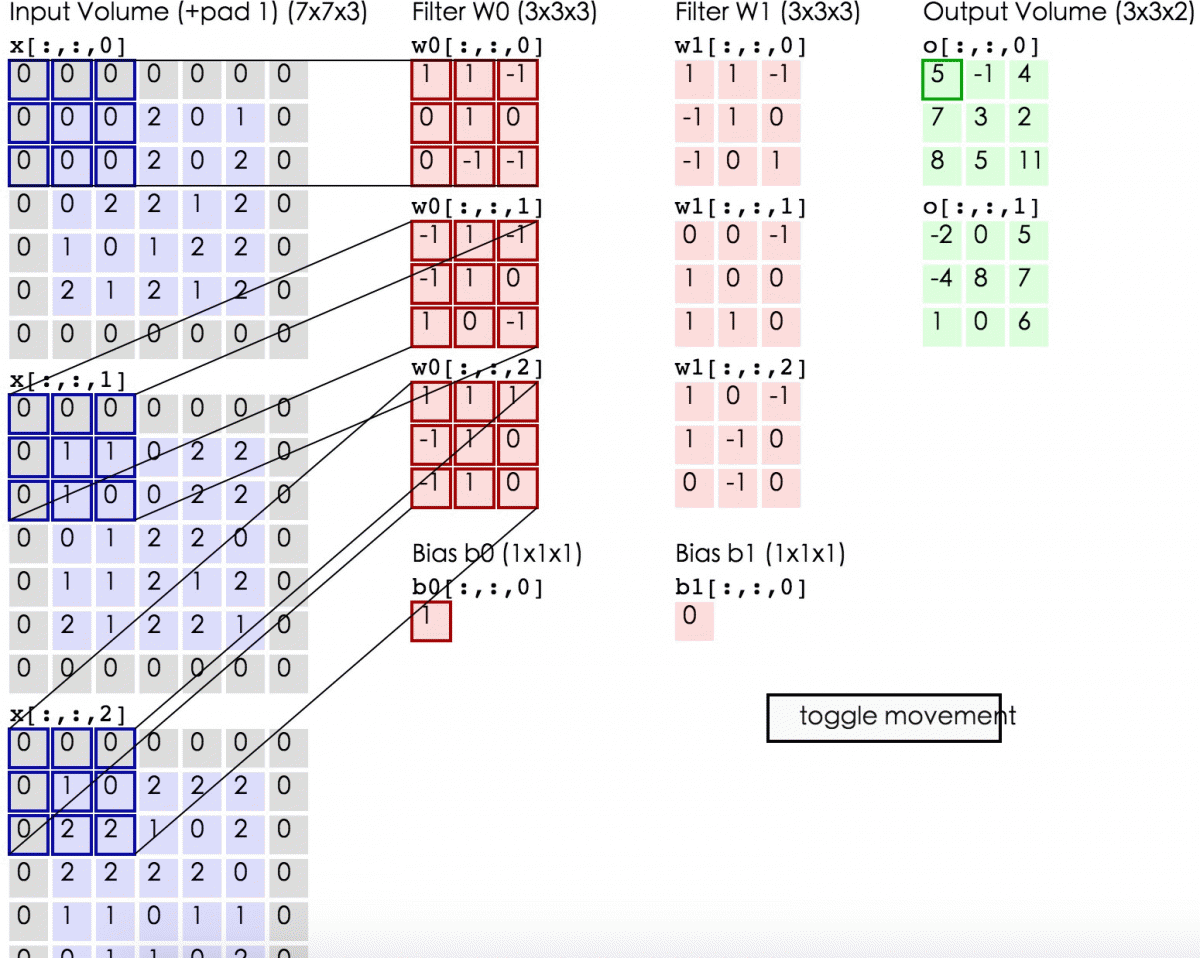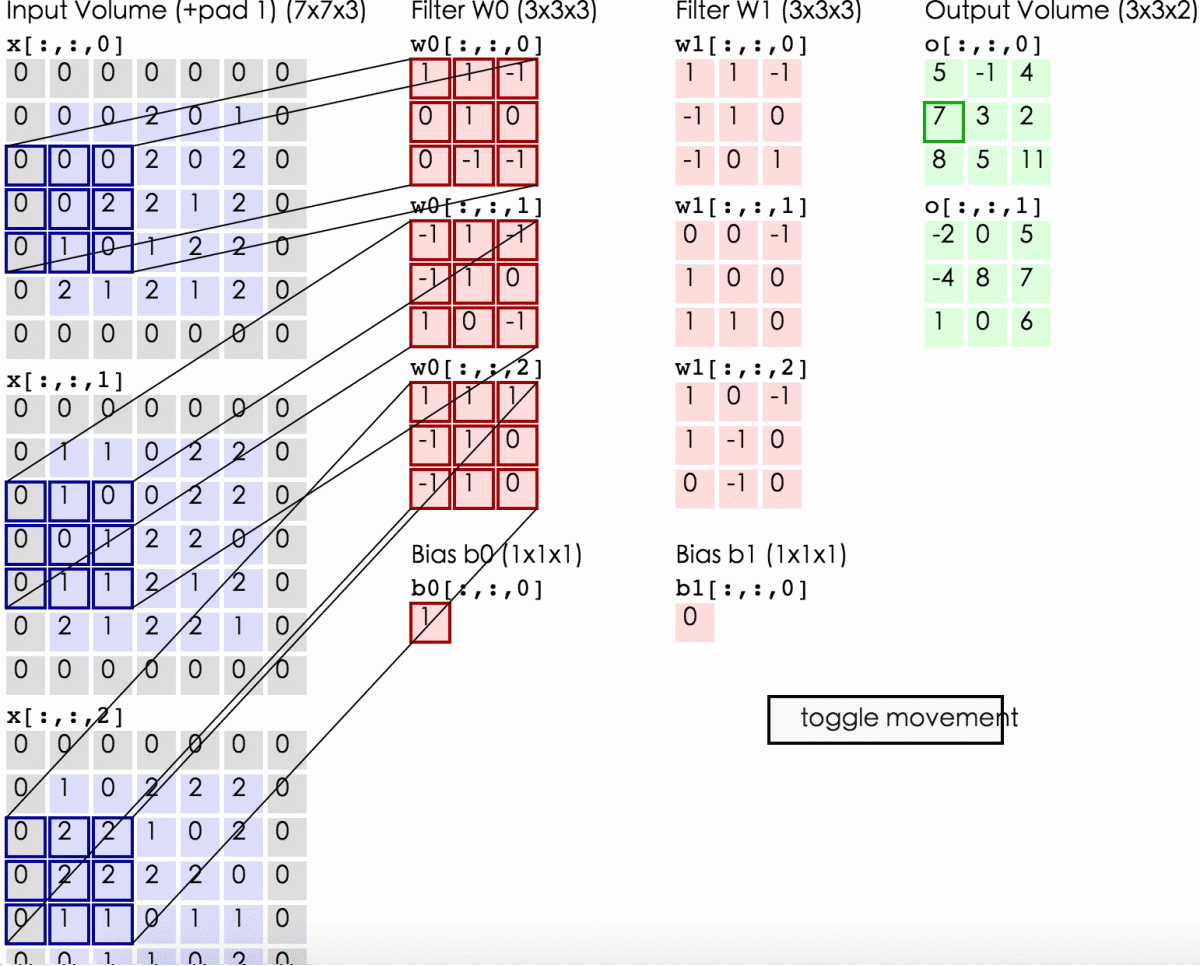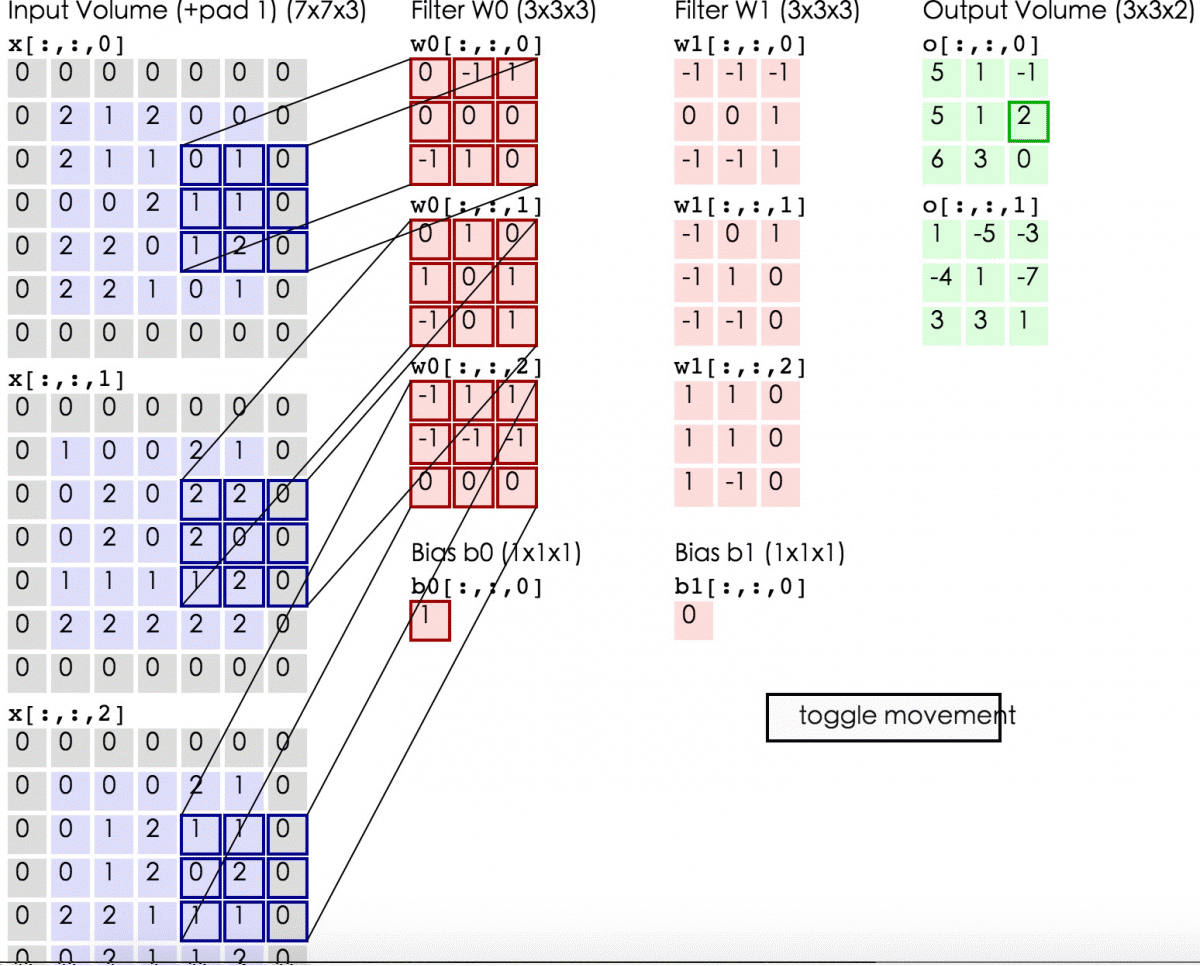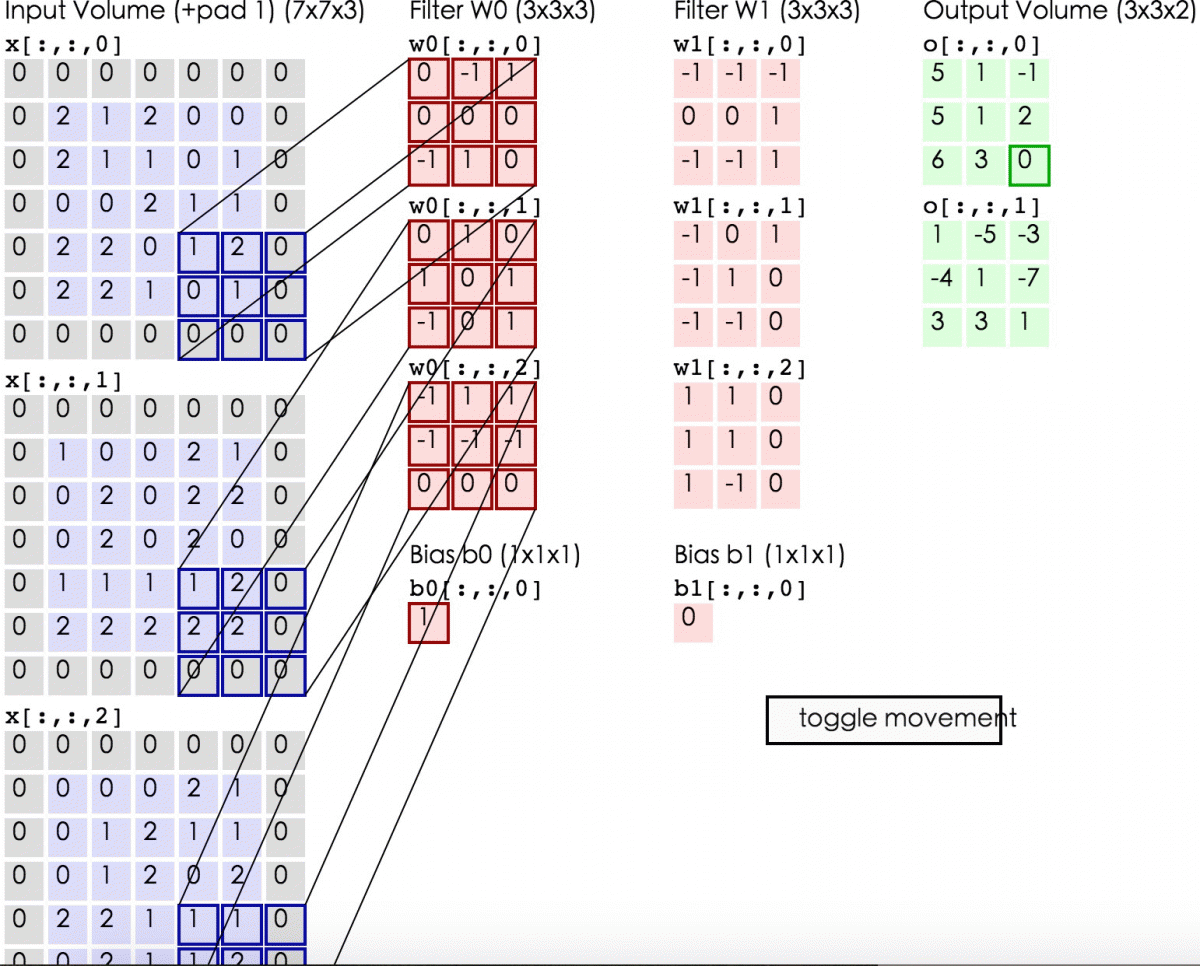
上面这张动图展示了卷积层的计算过程
参数共享机制
在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元值关注一个特性。神经元是图像处理中的滤波器,比如边缘检测专用的sobel滤波器,即卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等,所有这些神经元加起来就是一整张图像的特征提取器合集。
3.激励层
把卷积层输出结果做非线性映射,就是普通神经网络的内容
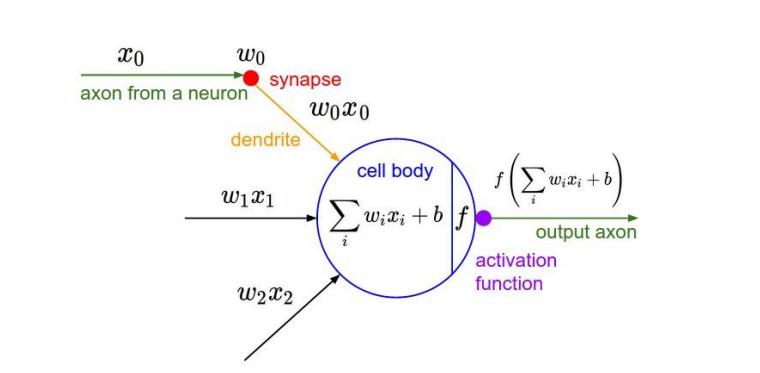
CNN一般采用的激励函数f()是ReLU(The Rectified Linear Unit线性修正单元),特点是收敛快,求梯度简单,但较脆弱,图像如下

原作者提供的一些经验:
1)不要使用sigmoid
2)首先试用ReLU,因为快,但需要注意
3)2不行,就采用Leaky ReLU 或者 Maxout
4)某些情况下tanh效果不错,但是情况很少
4.池化层
池化层夹在连续的卷积层中间,用于压缩数据和参数的量,减小过拟合。如果输入是图像,那么池化层的最主要作用就是压缩图像。(和opencv里的有个部分很像)
池化层具体作用有如下几点:
1.特征不变性,也就是我们在图像处理中常提到的特征的尺度不变性,池化操作就是图像的resize。一张狗的图像缩小了一倍我们还能认出这是一张狗的照片,说明这张图片中仍保留了狗的重要特征。图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则具有尺度不变性的特征,是最能表达图像的特征。
2.特征降维:我们知道衣服图像含有的信息量很大,特征很多,而其中有些信息对我们最终目的没什么用途或者重复,可以把这类冗余信息去除,把最重要的特征抽取出来。
3.在一定程度上可以防止过拟合,更方便优化
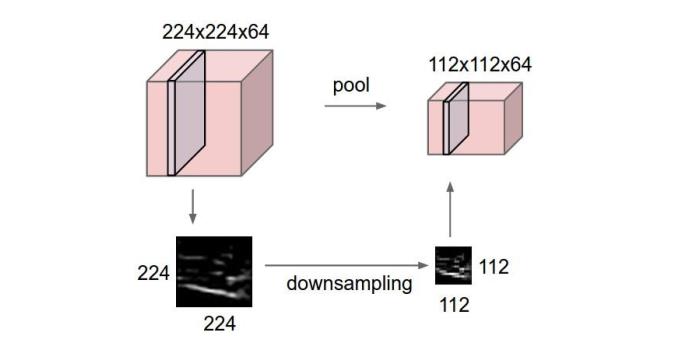
池化层用的方法有Max pooling 和 average pooling,而实际用的较多的是maxpooling。这里就说一下Max pooling
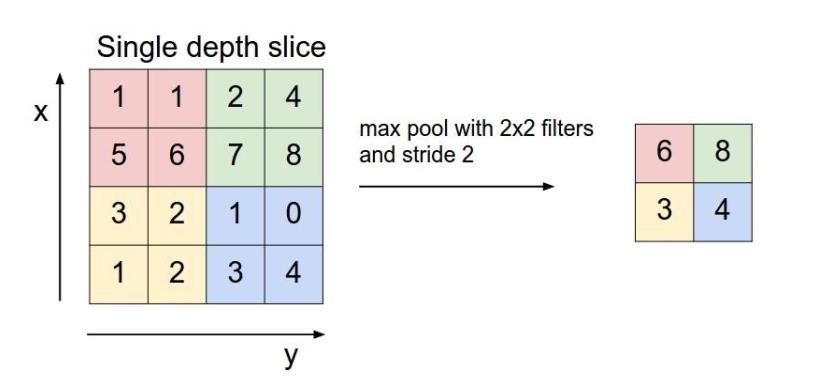
对于每个2*2 的窗口中选出最大的数作为输出矩阵的相应元素的值
5.全连接层
两层之间的所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:

一般CNN结构是:
1. INPUT
2. [[CONV -> RELU]*N -> POOL?]*M
3. [FC -> RELU]*K
4. FC
卷积神经网络的训练算法
1.同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距
2.找到最小化损失函数的W和b,CNN中用的是随机梯度下降
优劣:
- 共享卷积核,对高维数据处理没有压力
- 无需手动选取特征,训练好权重即得特征分类效果好
- 需要调参,需要大样本量
- 物理含义不明确
fine-tuninig
就是使用用于其他目标,预训练好模型的权重或部分权重,作为初始值开始训练
有点有二:一是自己从头随机选取几个数作为权重初始值训练卷积网络容易出现问题;二,fine-tuning能很快收敛到一个较为理想的状态,既省时又省心
具体操作方式是
1)复用相同层的权重,新定义的层采用随机权重初始值
2)调大新定义层的学习率,调小复用层的学习率