通过对MNIST的学习,对TensorFlow和机器学习快速上手。
MNIST:手写数字识别数据集
MNIST数据集
60000行的训练数据集 和 10000行测试集
每张图片是一个28*28的像素图。用一个数字数组来表示这张图片。这里把这个数组展开成一个向量,长度为28*28=784。(其实展平图片丢失了许多关键的二维结构信息,但这里他这么做了)
训练集包括两部分:索引图片集[60000,784],标签集[60000,10]
标签机使用的是 one-hot vectors。一个one-hot向量除了某一位数字是1以外其他都是0.所以在此教程中,数字n将表示成一个只有在第n维度数字是1的10维变量。例如标签0标位[1,0,0,0,0,0,0,0,0,0]
Softmax回归
softmax模型可以用来给不同的对象分配概率。
一般分为两步。
第一步:
寻找证据(evidense):需要找到数据中证明该图片是某标签的证据,或者不是某标签的证据。以本图为例,如果某个像素具有很强的证据说明这张图片不属于该类,则相应的权值为负数;反之如果这个像素拥有有力的证据支持这张图片属于这个类,则权值为正数。最后再对这些像素值进行加权求和。持外,我们也需要加入一个额外的偏置量(bias),因为输入往往带有一些无关的干扰量。因此对于给定的输入图片x它代表的是数字i的证据可以表示为
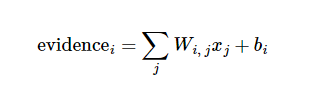
其中Wi表示权重,bi表示数字i的偏置量,j表示给定图片x的像素索引用于像素求和。然后用softmax函数可以把这些evidence转化为概率
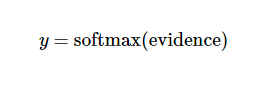
这里softmax可以看做一个激励函数(activation)或者link函数,将我们定义的线性函数的输出转换为我们想要的概率形式。因此,给定一个图片,他对于每个数字的吻合度可以被softmax转化为一个概率值。一个典型的softmax函数为:
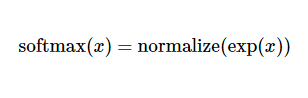
展开右边的式子,有:
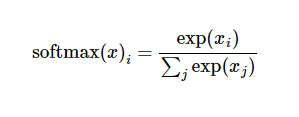
但更多时候把softmax模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型里面的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0值或者负值。Softmax然后会正则化这些权重值,使他们的总和等于1,以此构造一个有效的概率分布。
实现回归模型
为了用python实现高效的数值计算,一般会使用Numpy这样的函数库,会把类似于矩阵乘法这样的复杂运算使用其他的外部语言实现。然而频繁于python和外部语言切换是一笔很大的开销。
TensorFlow也吧复杂运算放在python外部完成,但是为了避免这些开销,它做了进一步完善。这里就是我们说的先构造图在运算,而不是进行单一的复杂运算。
#!/usr/bin/env python
import os
os.environ['TF_CPP_MIN_LOG+LEVEL'] = '2'
import tensorflow as tf
x = tf.placeholder(tf.float32,[None,784])
#这里x是一个占位符,我们不希望直接全部读入所有的图,而是在运行计算时动态的读入这些图
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
#Variable 表示一个可以修改的张量。它们可以用于计算输入值,也可以在计算中被修改。
y = tf.nn.softmax(tf.matmul(x,W) + b)
#tf.matmul(x,W)表示x乘以W(注意是矩阵相乘)
训练模型
为了训练我们的模型,我们首先需要定义一个损失函数,然后尽量最小化这个指标。一个比较经典的成本函数是交叉熵
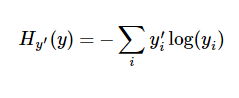
y是我们预测的概率分布,y‘是实际的分布(我们输入的 one-hot vector)。比较粗糙的理解是,交叉熵し用来衡量我们预测用于描述用于描述真相的低效性。
y_ = tf.placeholder('float',[None,10])
#用来存储正确的值
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
#这里交叉熵不仅仅用来衡量单一的一对预测和真实值,而是所有100幅图片的交叉熵的总和。对于100个数据点的预测表现び对单一数据点的表现能更好地描述我们的模型的性能
#TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法来有效的确定你的变量是如和影响你要最小化的那个成本值的。然后,TensorFlow会用你选择的优化算法来不断的修改变量降低成本
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
#这里要求TensorFlow使用梯度下降算法以0.01的学习速率最小化交叉熵。当然TensorFlow还集成了许多其他优化算法。
#TensorFlow在这里实际上做的是,在后台给描述你的计算的那张图里加上一系列新的计算操作单元用于实现反向传播算法和梯度下降算法。然后它返回给你的只是一个单一的操作,当运行这个操作时,タ用梯度下降算法训练你的模型,微调你的变量,不断减少成本
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
for i in range(1000):#让模型循环训练1000次
batch_xs,batch_ys = mnist.train.next_batch(100)#随机抓取训练数据中的100个批处理数据点
sess.run(train_step,feed_dict = {x:batch_xs,y: batch_ys})
评估模型
如何评估我们的模型?
首先找出那些预测正确的标签。tf.argmax是一个非常有用的函数。它能给出某个tensor对象在某一位上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置急速类别标签,比如tf.argmax(y,1)返回的是模型对于任意输入x预测到的标签值,而tf.argmin(y_,1),我们可以用tf.equal来检测我们的预测值是否正确。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))这行代码会给我们一组布尔值。为了求出预测准确率,我们将布尔值转化为1和0,在将其相加求平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))最后,我们计算所学习到的模型在测试数据集上的正确率
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})