1.前言
上一小节,主要介绍了MGR的由来以及为什么要使用MGR和使用MGR的过程中要注意什么,那么这小节主要讲解MGR的原理浅谈
2.MGR的复制模式
MySQL的组复制可以配置为单主模型和多主模型两种工作模式,它们都能保证MySQL的高可用。以下是两种工作模式的特性简介
- 单主模型:从复制组中众多个MySQL节点中自动选举一个master节点,只有master节点可以写,其他节点自动设置为read only。当master节点故障时,会自动选举一个新的master节点,选举成功后,它将设置为可写,其他slave将指向这个新的master。
- 多主模型:复制组中的任何一个节点都可以写,因此没有master和slave的概念,只要突然故障的节点数量不太多,这个多主模型就能继续可用。
虽然多主模型的特性很诱人,但缺点是要配置和维护这种模式,必须要深入理解组复制的理论,更重要的是,多主模型限制较多,其一致性、安全性还需要多做测试。
而使用单主模型的组复制就简单的太多了,唯一需要知道的就是它会自动选举master节点这个特性,因为它的维护一切都是自动进行的,甚至对于管理人员来说,完全可以不用去了解组复制的理论。
虽然单主模型比多主模型的性能要差,但它没有数据不一致的危险,加上限制少,配置简单,基本上没有额外的学习成本,所以多数情况下都是配置单主模型的组复制,即使是PXC和MariaDB也如此。
3.单主模型组复制的理论基础
虽说组复制的单主模型很简单,但有必要了解一点和单主模型有关的理论,尽管不了解也没什么问题,毕竟一切都是自动的
如下图,master节点为s1,其余为slave节点。
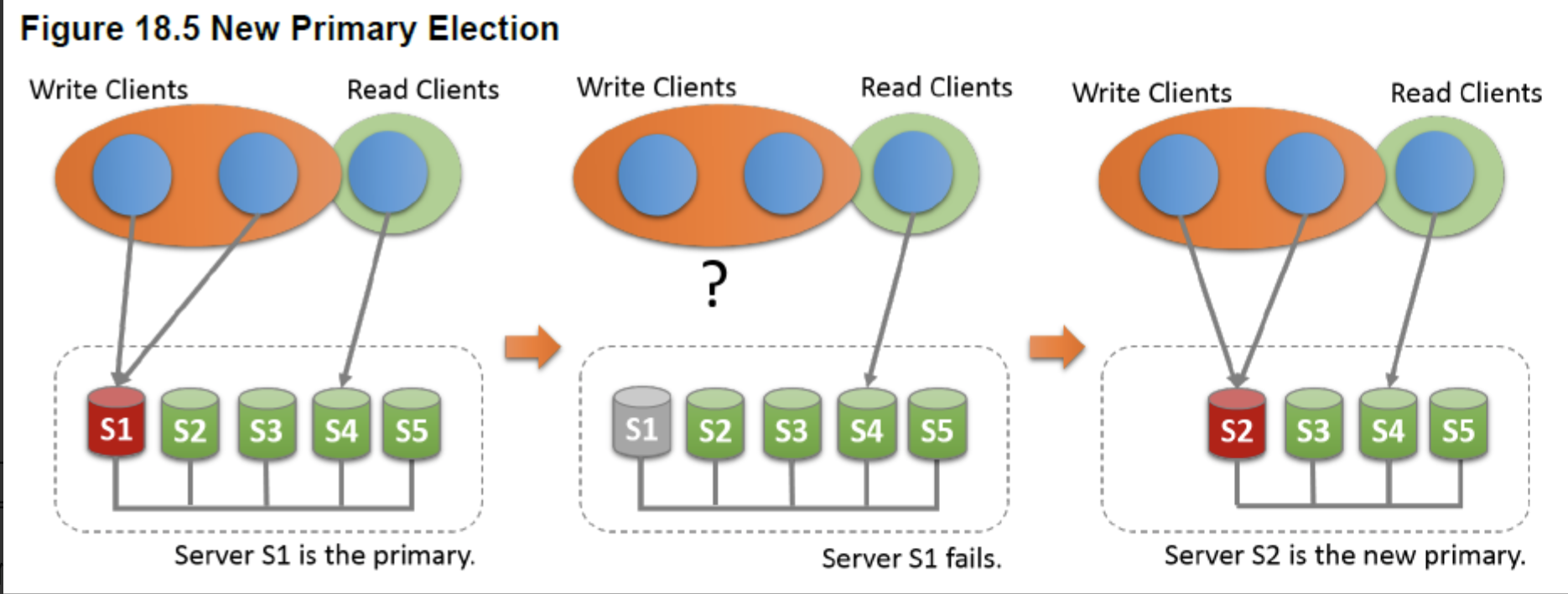
组复制一切正常时,所有的写操作都路由到s1节点上,所有的读操作都路由到s2、s3、s4或s5上。当s1节点故障后,组复制自动选举新的master节点。假如选举s2为新master成功后,s3、s4和s5将指向s2,写操作将路由到s2节点上。
至于如何改变客户端的路由目标,这不是组复制应该考虑的事情,而是客户端应用程序应该考虑的事情。实际上,更好的方式是使用中间件来做数据库的路由,比如MySQL Router、ProxySQL、amoeba、cobar、mycat。
3.1 如何加入新节点
上面一直说,单主模型是自动选举主节点的,那么如何选举?
首先,在第一个MySQL节点s1启动时,一般会将其设置为组的引导节点,所谓引导就是在启动组复制功能时去创建一个复制组。当然,这并非强制要求,也可以设置第二个启动节点作为组的引导节点。因为组内没有其他节点,所以这第一个节点会直接选为master节点。
然后,如果有第二个节点要加入组时,新节点需要征得组的同意,因为目前只有一个节点,所以只需s1节点同意即可。新节点在加入组时,首先会联系s1,与s1建立异步复制的通道,并从s1节点处获取s2上目前缺失的数据,等到s1和s2节点上的数据同步后,s2节点就会真正成为组中的新成员。当然,实际过程要比这里复杂一些,本文不会过多讨论。
如果还有新节点(比如s3节点)继续加入组,s3将从s1或s2中选一个,并与之建立异步复制的通道,然后获取缺失的数据,同步结束后,如果s1和s2都同意s3加入,那么s3将会组中的新成员。其余节点加入组也依次类推。
有两点需要注意:
1.新节点加入组时,如何选择联系对象?
上面说加入第二个节点s2时会联系s1,加入s3时会联系s1、s2中的任意一个。实际上,新节点加入组时联系的对象,称为donor,意为数据供应者。新节点会和选中的donor建立异步复制通 道,并从donor处获取缺失的数据。
在配置组复制时,需要指定种子节点列表。当新节点加入组时,只会联系种子节点,也即是说,只有种子节点列表中的节点才有机会成为donor,没有在种子节点列表中的节点不会被新节点选中。但建议,将组中所有节点都加入到种子列表中
当联系第一个donor失败后,会向后联系第二个donor,再失败将联系第三个donor,如果所有种子节点都联系失败,在等待一段时间后再次从头开始联系第一个donor。依此类推,直到加组失败报错
2.新节点加入组时,需要征得哪些节点的同意?
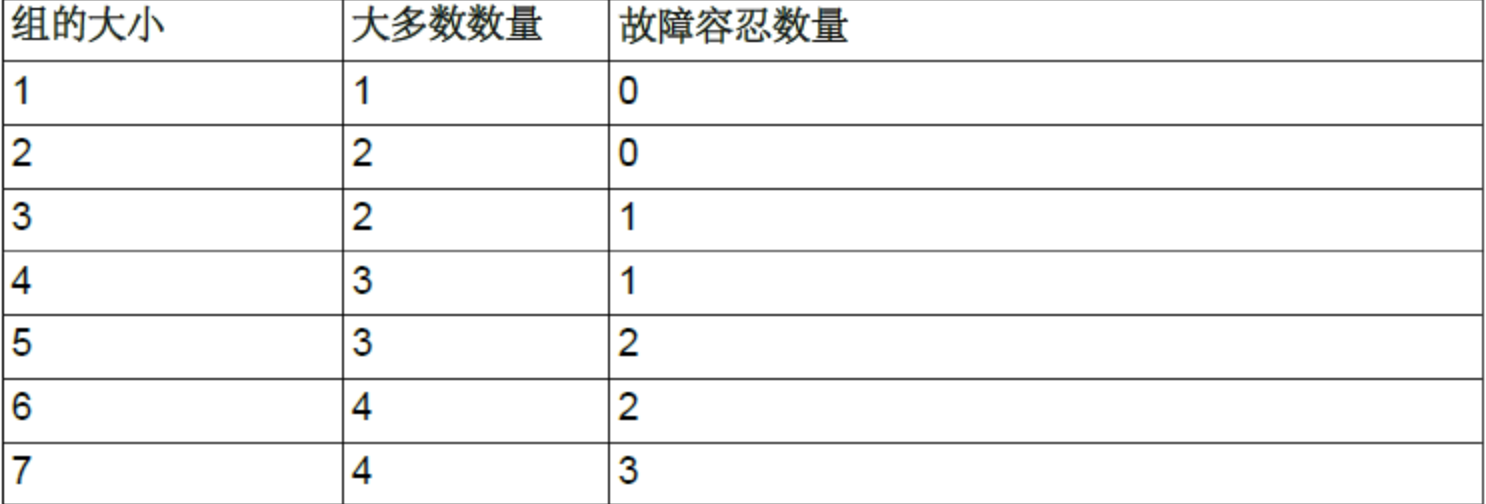
实际上,新节点加组涉及到组的决策:是否允许它加组。在组复制中,所有的决策都需要组中大多数节点达成一致,也即是达到法定票数。所谓大多数节点,指的是N/2+1(N是组中目前节点总数),例如目前组中有5个节点,则需要3个节点才能达到大多数的要求。
3.3 如何选取新的master?
当主节点s1故障后,组复制的故障探测机制就能发现这个问题并报告给组中其他成员,组中各成员根据收集到的其他成员信息,会比较各成员的权重值(由变量group_replication_member_weigth控制),权重值最高的优先成为新的Master。如果有多个节点具有相同的最高权重值,会按字典顺序比较它们的server_uuid值,最小的(升序排序,最小值在最前面)优先成为新的master。
但需要注意,变量group_replication_member_weigth是从MySQL 5.7.20开始提供的,在MySQL 5.7.17到5.7.19之间没有该变量。此时将根据它们的server_uuid值进行排序选举。具体的规则可自行测试。
3.4 最多能允许多少个节点故障?
MySQL组复制使用Paxos分布式算法来提供节点间的分布式协调。正因如此,它要求组中大多数节点在线才能达到法定票数,从而对一个决策做出一致的决定。
大多数指的是N/2+1(N是组中目前节点总数),例如目前组中有5个节点,则需要3个节点才能达到大多数的要求。所以,允许出现故障的节点数量如下图: