1.前言
本章节重点剖析Xtrabackup的工作原理(包括它的备份原理以及恢复原理)
2.开始
在下载完percona-xtrabackup(我这里下载的是二进制包),版本是:xtrabackup version 2.4.21 会发现其bin目录是如下结构:
[root@node01 bin]# tree /usr/local/xtrabackup/bin /usr/local/xtrabackup/bin ├── innobackupex -> xtrabackup ├── xbcloud ├── xbcloud_osenv ├── xbcrypt ├── xbstream └── xtrabackup
这里的innobackupex是xtrabackup的软连接,但是在之前版本,这两个是相互独立的命令。
在之前版本中xtrabackup 是用来备份 InnoDB 表的,不能备份非 InnoDB 表,和 mysqld server 没有交互;innobackupex 脚本用来备份非 InnoDB 表,同时会调用 xtrabackup 命令来备份 InnoDB 表,还会和 mysqld server 发送命令进行交互,如加读锁(FTWRL)、获取位点(SHOW SLAVE STATUS)等。简单来说,innobackupex 在 xtrabackup 之上做了一层封装。但是在2.4版本中已经把innobackupex作为xtrabackup的软连接,说明xtrabackup已经整合了innobackupex所有功能。
- innobackupex:innobackupex是xtrabackup的符号链接。innobackupex仍然像2.2版本一样支持所有功能和语法,但现在已弃用,并将在下一个主要版本中删除。
- xtrabackup:一个已编译的C二进制文件,它提供了使用MyISAM、InnoDB和XtraDB表备份整个MySQL数据库实例的功能。
- xbcrypt:用于加密和解密备份文件的实用程序
- xbstream:允许从 xbstream 格式流式传输和提取文件的实用程序
- xbcloud:用于从云下载或从云上传全部或部分 xbstream 存档的实用程序
3.完全备份流程解析原理
Percona XtraBackup基于innodb的崩溃恢复功能。复制innodb数据文件,这会导致数据在内部不一致;但随后它对文件执行崩溃恢复,是它们再次成为一致、可用的数据库。
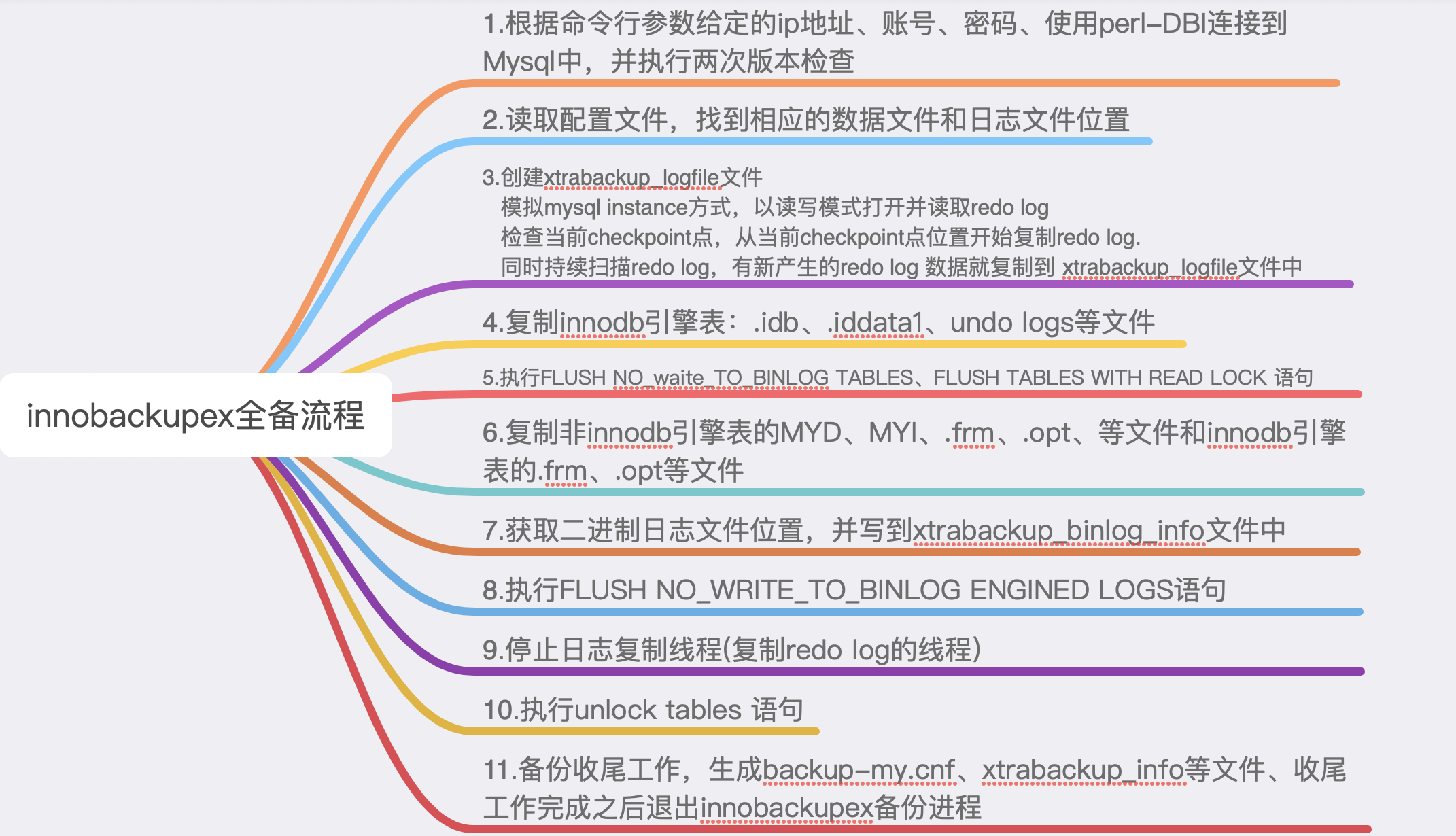
具体步骤:
- 在开始备份时,首先使用指定的账号和密码连接Mysql,该数据库连接用于备份过程中执行如加锁、解锁、刷新redo日志等与数据库进行交互操作
- 读取--defaults-file选项指定的配置文件,解析innodb_data_home_dir和innodb_log_group_home_dir等系统参数,找到数据表空间和redo日志文件的位置。创建xtrabackup_logfile文件,模拟Mysql实例方式,以读写模式打开并读取redo日志,检查当前的检查点,从当前检查点位置复制redo日志,同时持续扫描redo日志,有新产生的redo日志数据都复制到xtrabackup_logfile文件中(整个备份过程中一直复制redo日志,通过查看备份目录下的xtrabackup_log文件,可以看到这个文件在不断增长)
- 另外一个线程调用xtrabackup命令开始复制数据文件(主要是磁盘上的文件),包括共享表空间文件和独立表空间文件,相当于获得了redo日志,undo日志和数据文件,只是没有没存中脏页数据,不过后期在恢复是直接通过redo日志来恢复就可以了。
- 全局执行FLUSH TABLE WITH READ LOCK 语句加上一个S锁,此时数据库处于不可写状态(执行FTWRL的目的是为了防止读取数据是发生DDL操作,并且获取binlog文件位置)。redo日志暂时也会卡在这里。
- 开始复制表结构文件,复制非innodb引擎表的.MYD、.MYI、.frm等文件和innodb引擎表.fim、opt等文件,并获取binlog文件位置并写到xtrabackup_binlog_info文件中
- 执行flush no_waite_to_binlog engine logs语句将innodb层的redo日志持久化到磁盘后进行复制(因为xtrabackup不备份二进制日志,所以,如果这个过程如果出现问题,就会导致恢复之后丢失redo日志中数据,做主从复制可能会同步出错,但是在2.2.3版本之后修复),最后再停止读redo日志复制的线程。需要主要的是,innobackupex备份数据的时间点是停止redo日志复制时的数据对应的时间点
- 当redo日志的复制线程停止后,执行unlock tables 语句解锁表。
- 最后innobackupex完成收尾工作,如释放资源,记录与备份相关的元数据信息等(例如backup-my.cnf和xtrabackup_info文件),最后退出innobackupex备份进程
在上面描述的文件拷贝,都是备份进程直接通过操作系统读取数据文件的,只在执行 SQL 命令时和数据库有交互,基本不影响数据库的运行,在备份非 InnoDB 时会有一段时间只读(如果没有MyISAM表的话,只读时间在几秒左右),在备份 InnoDB 数据文件时,对数据库完全没有影响,是真正的热备。
4.完全备份恢复解析流程
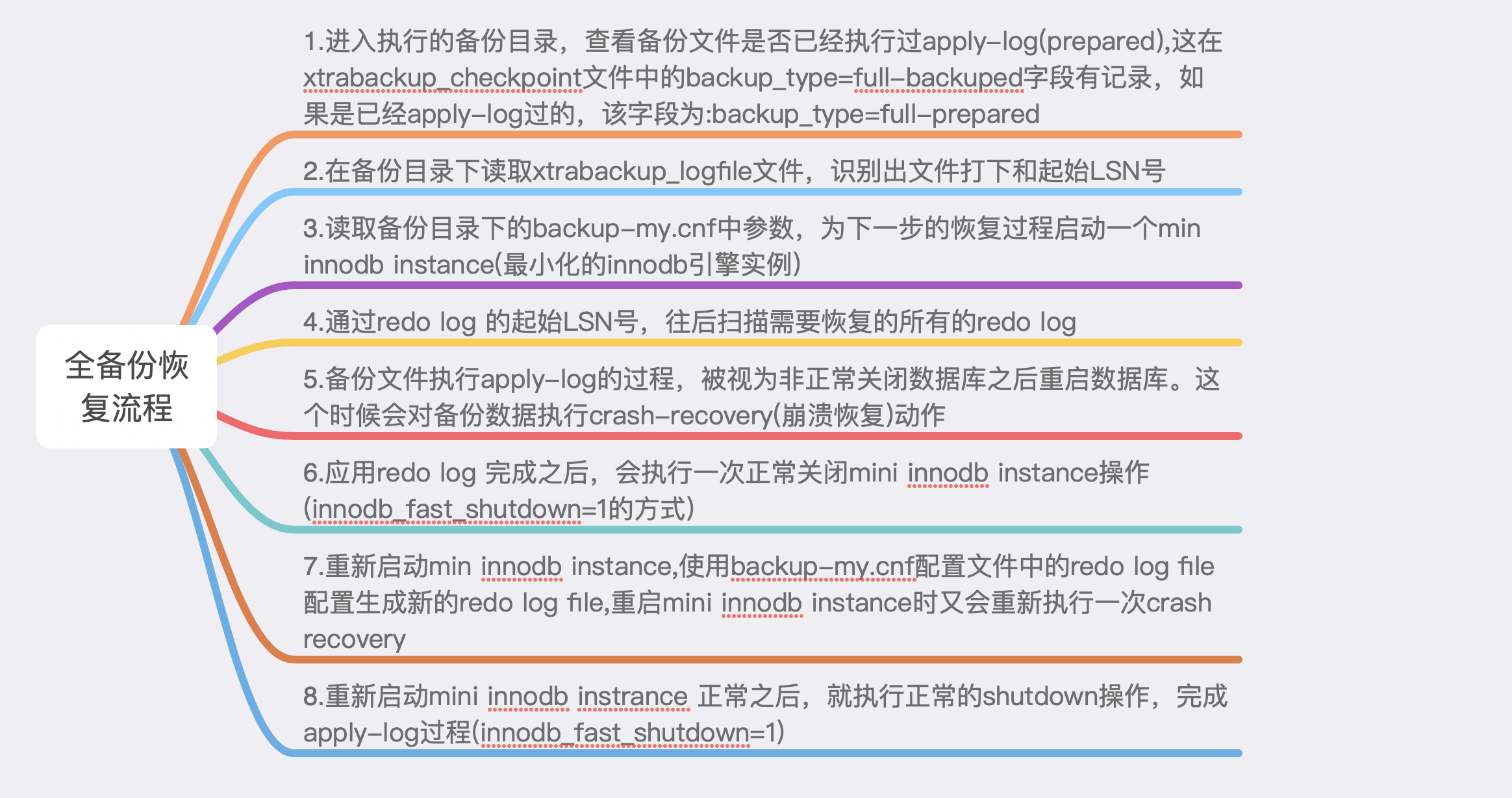
具体步骤:
- 在备份恢复时,启动一个minni instance(最小化数据库实例),把数据文件复制到内存中,然后再读取xtrabackup_log中的redo日志进行应用,最后对没有提交的事务使用undo日志进行回滚
- 如果查看备份恢复时的打印日志,就会发现使用innobackupex命令执行备份恢复的过程和mysqld进行启动过程非常相似,使用innobakupex命令执行备份恢复的过程中会做一次crash recovery(崩溃恢复)操作,恢复的目的是把备份数据恢复到一个一致性位点(undo、redo日志和表空间中的数据相对应)
- 备份时执行FTWRL后,数据库处于只读状态,非innodb表是在持有全局读锁的情况下复制的,所以其本身就对应于FTWRL的时间点。innodb的.ibd文件复制是在FTWRT前做的,复制出出来的不同.ibd文件的最后更新时间点是不一样的,这种状态的.ibd文件是不能直接用的,但是redo日志是从备份开始就一直持续复制的,最后redo日志时间点是在执行FTWRL后取得的,所以最终通过redo日志应用字后的.ibd文件数据的时间和FTWRLd的时间点是一致的,因此,恢复过程只涉及innodb文件的恢复,非innodb表示不需要恢复的,当备份恢复完成后,就可以把数据文件复制到对应的目录下,通过mysqld来启动了。
5.增量备份
原理后补。。。
参考文献:
http://mysql.taobao.org/monthly/2016/03/07/
https://www.percona.com/doc/percona-xtrabackup/2.4/how_xtrabackup_works.html