不多说,直接上干货!
这篇我是从整体出发去写的。
牛客网Java刷题知识点之Java 集合框架的构成、集合框架中的迭代器Iterator、集合框架中的集合接口Collection(List和Set)、集合框架中的Map集合
接口java.util.Map,包括3个实现类:HashMap、Hashtable、TreeMap。当然还有LinkedHashMap、ConcurrentHashMap 、WeakHashMap。
Map是用来存储键值对的数据结构,键值对在数组中通过数组下标来对其内容索引的,而键值对在Map中,则是通过对象来进行索引,用来索引的对象叫做key,其对应的对象叫value。
Map与Collection在集合框架中属并列存在
Map是一次添加一对元素(存储的是夫妻,哈哈)。Collection是一次添加一个元素(存储的是光棍,哈哈)。
Map存储的是键值对。
Map存储元素使用put方法, Collection使用add方法。
Map集合没有直接取出元素的方法, 而是先转成Set集合, 再通过迭代获取元素。
Map集合中键要保证唯一性。
Map的两种取值方式keySet、entrySet
keySet
先获取所有键的集合, 再根据键获取对应的值。(即先找到丈夫,去找妻子)
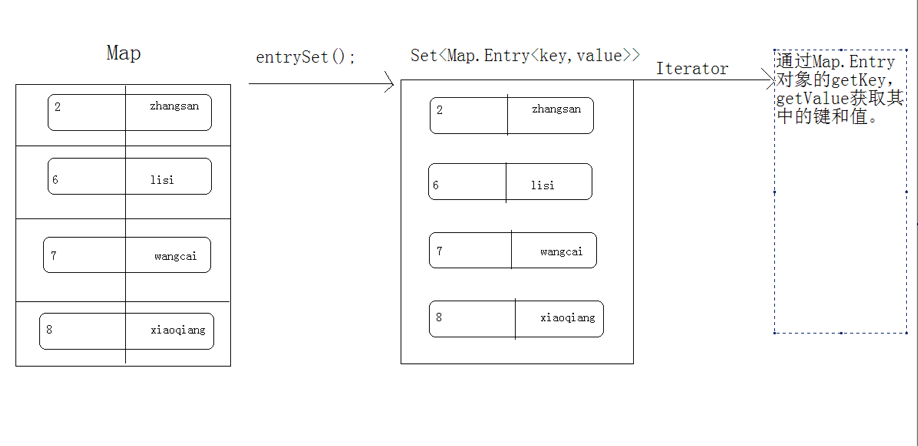
entrySet
先获取map中的键值关系封装成一个个的entry对象, 存储到一个Set集合中,再迭代这个Set集合, 根据entry获取对应的key和value。
向集合中存储自定义对象 (entry类似于是结婚证)
HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
keySet的演示图解:

entrySet的演示图解:
HashMap概述
HashMap是基于哈希表的Map接口的非同步实现,此实现提供所有可选的映射操作,并允许使用null值和null键
它不保证映射的顺序,HashMap是Hashtable的轻量级实现(非线程安全的实现),它们都完成了Map接口。
HashMap的数据结构
哈希表是由数组+链表组成的,(注意,这是jdk1.8之前的)数组的默认长度为16。
为什么是数组+链表?
数组对于数据的访问如查找和读取非常方便,链表对于数据插入非常方便。
链表可以解决hash值冲突(即对于不同的key值可能会得到相同的hash值)
数组里每个元素存储的是一个链表的头结点。而组成链表的结点其实就是hashmap内部定义的一个类:Entity
Entity包含三个元素:key,value和指向下一个Entity的next。

若是,jdk1.8,则
牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
HashMap的存取
HashMap的存储--put : null key总是存放在Entry[]数组的第一个元素
元素需要存储在数组中的位置。先判断该位置上有没有存有Entity,没有的话就创建一个Entity<k,v>对象,新的Entity插入(put)的位置永远是在链表的最前面。
HashMap的读取--get : 先定位到数组元素,再遍历该元素处的链表.
覆盖了equals方法之后一定要覆盖hashCode方法,原因很简单,比如,String a = new String(“abc”); String b = new String(“abc”); 如果不覆盖hashCode的话,那么a和b的hashCode就会不同。
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。
解决哈希(HASH)冲突的主要方法
开放地址法
再hash法
链地址法
哈希表及处理冲突的方法 http://blog.sina.com.cn/s/blog_6fd335bb0100v1ks.html
见
同步方法:ConcurrentHashMap
Hashtable的put和get方法均为synchronized的是线程安全的。
将HashMap默认划分为了16个Segment,减少了锁的争用。
写时加锁读时不加锁减少了锁的持有时间。
volatile特性约束变量的值在本地线程副本中修改后会立即同步到主线程中,保证了其他线程的可见性。
value外,其他的属性都是final的,value是volatile类型的,都修饰为final表明不允许在此链表结构的中间或者尾部做添加删除操作,每次只允许操作链表的头部。
见
牛客网Java刷题知识点之为什么HashMap不支持线程的同步,不是线程安全的?如何实现HashMap的同步?
HashMap 的 hashcode 的作用?什么时候需要重写?如何解决哈希冲突?查找的时候流程是如何?
为什么这么说呢?考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)
也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值。实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了。
HashMap有一个叫做Entry的内部类,它用来存储key-value对。上面的Entry对象是存储在一个叫做table的Entry数组中。table的索引在逻辑上叫做“桶”(bucket),它存储了链表的第一个元素。key的hashcode()方法用来找到Entry对象所在的桶。如果两个key有相同的hash值(即冲突),他们会被放在table数组的同一个桶里面(以链表方式存储)。key的equals()方法用来确保key的唯一性。key的value对象的equals()和hashcode()方法根本一点用也没有。
Hashtable 概述
也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
Hashtable中的映射不是有序的。
Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽象类。
hashtable与hashmap区别(笔试面试必考)
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
我们先看HashMap和Hashtable这两个类的定义
public class Hashtable
extends Dictionary
implements Map, Cloneable, <a href="http://lib.csdn.net/base/javase" class='replace_word' title="Java SE知识库" target='_blank' style='color:#df3434; font-weight:bold;'>Java</a>.io.Serializable
public class HashMap
extends AbstractMap
implements Map, Cloneable, Serializable
可见Hashtable 继承自 Dictiionary, 而 HashMap继承自AbstractMap。
1) HashMap允许null键值的key,注意最多只允许一条记录的键为null,不允许多条记录的值为null。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
2) HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
3) Hashtable的方法是线程安全的,而HashMap不支持线程的同步。
4) Hashtable使用Enumeration,HashMap使用Iterator。
4)hash值的使用不同,Hashtable直接使用对象的hashCode,而HashMap是
(1)继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
(2)线程安全性不同
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。
(3)是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
(4)key和value是否允许null值
其中key和value都是对象,并且不能包含重复key,但可以包含重复的value。
Hashtable中,key和value都不允许出现null值。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
(5)两个遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
(6)hash值不同
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
(7)内部实现使用的数组初始化和扩容方式不同
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
HashMap中hash数组的默认大小是16,而且一定是2的指数。
hashmap与currenthashmap区别
Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;
而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个段,诸如get,put,remove等常用操作只锁当前需要用到的桶。
Hashtable是线程安全的,它的方法是同步了的,可以直接用在多线程环境中。
而HashMap则不是线程安全的。在多线程环境中,需要手动实现同步机制。
Hashmap与Linkedhashmap区别
Linkedhashmap是hashmap子类多了after和behind方法。
LinkedHashMap比HashMap多维护了一个链表。
TreeMap
TreeMap的底层使用了红黑树来实现,像TreeMap对象中放入一个key-value 键值对时,就会生成一个Entry对象,这个对象就是红黑树的一个节点,其实这个和HashMap是一样的,一个Entry对象作为一个节点,只是这些节点存放的方式不同。
存放每一个Entry对象时都会按照key键的大小按照二叉树的规范进行存放,所以TreeMap中的数据是按照key从小到大排序的。
Arraylist 和 HashMap 如何扩容?负载因子有什么作用?如何保证读写进程安全?
HashTable默认初始11个大小,默认每次扩容的因子为0.75,
HashMap默认初始16个大小(必须是2的次方),默认每次扩容的因子为0.75。
ArrayList,默认初始10个大小,每次扩容是原容量的一半。
Vector,默认初始10个大小,每次扩容是原容量的两倍,
StringBuffer、StringBuilder默认初始化是16个字符,默认增容为(原长度+1)*2。
负载因子有什么作用,必须在 "冲突的机会"与"空间利用率"之间寻找一种平衡与折衷。这种平衡与折衷本质上是数据结构中有名的"时-空"矛盾的平衡与折衷。
HashMap、LinkedHashMap、TreeMap、WeakHashMap
HashMap里面存入的键值对在取出时没有固定的顺序,是随机的。
一般而言,在Map中插入、删除和定位元素,HashMap是最好的选择。
由于TreeMap实现了SortMap接口,能够把它保存的记录根据键排序,因此,取出来的是排序后的键值对,如果需要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap是HashMap的一个子类,如果需要输出的顺序和输入相同,那么用LinkedHashMap可以实现、它还可以按读取顺序来排列。
WeakHashMap中key采用的是“弱引用”的方式,只要WeakHashMap中的key不再被外部引用,它就可以被垃圾回收器回收。
而HashMap中key采用的是“强引用的方式”,当HashMap中的key没有被外部引用时,只有在这个key从HashMap中删除后,才可以被垃圾回收器回收。
“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”
几乎每个人都会回答“是的”,然后回答HashMap的一些特性,譬如HashMap可以接受null键值和值,而Hashtable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对等等。这显示出你已经用过HashMap,而且对它相当的熟悉。但是面试官来个急转直下,从此刻开始问出一些刁钻的问题,关于HashMap的更多基础的细节。
面试官可能会问出下面的问题:
你知道HashMap的工作原理吗? 你知道HashMap的get()方法的工作原理吗?
你也许会回答“我没有详查标准的Java API,你可以看看Java源代码或者Open JDK。”“我可以用Google找到答案。”
但一些面试者可能可以给出答案,“HashMap是基于hashing的原理,我们使用put(key,value)存储对象到HashMap中,使用get(key)从HashMap中获取对象(其实就是得到value,在java里嘛,万物皆对象)。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。
如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理。但是这仅仅是故事的开始,当面试官加入一些Java程序员每天要碰到的实际场景的时候,错误的答案频现。
当两个对象的hashcode相同会发生什么?
从这里开始,真正的困惑开始了,一些面试者会回答因为hashcode相同,所以两个对象(即value)是相等的,HashMap将会抛出异常,或者不会存储它们。然后面试官可能会提醒他们有equals()和hashCode()两个方法,并告诉他们两个对象就算hashcode相同,但是它们可能并不相等。一些面试者可能就此放弃,而另外一些还能继续挺进,他们回答“因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。”这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。
如果两个key的hashcode相同,你如何获取值对象?
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。
注意:面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。
一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
hashmap的存储过程?
HashMap内部维护了一个存储数据的Entry数组,HashMap采用链表解决冲突,每一个Entry本质上是一个单向链表。当准备添加一个key-value对时,首先通过hash(key)方法计算hash值,然后通过indexFor(hash,length)求该key-value对的存储位置,计算方法是先用hash&0x7FFFFFFF后,再对length取模,这就保证每一个key-value对都能存入HashMap中,当计算出的位置相同时,由于存入位置是一个链表,则把这个key-value对插入链表头。
HashMap中key和value都允许为null。key为null的键值对永远都放在以table[0]为头结点的链表中。
hashMap扩容问题?
扩容是是新建了一个HashMap的底层数组,而后调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(要重新计算元素在新的数组中的索引位置)。 很明显,扩容是一个相当耗时的操作,因为它需要重新计算这些元素在新的数组中的位置并进行复制处理。因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
HashMap共有四个构造方法。构造方法中提到了两个很重要的参数:初始容量和加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中槽的数量(即哈希数组的长度),初始容量是创建哈希表时的容量(从构造函数中可以看出,如果不指明,则默认为16),加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize 操作(即扩容)。
默认加载因子为0.75,如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。
HashMap的复杂度
HashMap整体上性能都非常不错,但是不稳定,为O(N/Buckets),N就是以数组中没有发生碰撞的元素。

同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



