不多说,直接上干货!
Labeled point: 向量标签
向量标签用于对Spark Mllib中机器学习算法的不同值做标记。
例如分类问题中,可以将不同的数据集分成若干份,以整数0、1、2,....进行标记,即我们程序开发者可以根据自己业务需要对数据进行标记。
向量标签和向量是一起的,简单来说,可以理解为一个向量对应的一个特殊值,这个值的具体内容可以由用户指定,比如你开发了一个算法A,这个算法对每个向量处理之后会得出一个特殊的标记值p,你就可以把p作为向量标签。同样的,更为直观的话,你可以把向量标签作为行索引,从而用多个本地向量构成一个矩阵(当然,MLlib中已经实现了多种矩阵)。
LabeledPoint是建立向量标签的静态类。
features用于显示打印标记点所代表的数据内容。
label用于显示标记数。
testLabeledPoint.scala

package zhouls.bigdata.chapter4
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.regression.LabeledPoint
object testLabeledPoint {
def main(args: Array[String]) {
val vd: Vector = Vectors.dense(2, 0, 6) //建立密集向量
val pos = LabeledPoint(1, vd) //对密集向量建立标记点
println(pos.features) //打印标记点内容数据
println(pos.label) //打印既定标记
val vs: Vector = Vectors.sparse(4, Array(0,1,2,3), Array(9,5,2,7)) //建立稀疏向量
val neg = LabeledPoint(2, vs) //对密集向量建立标记点
println(neg.features) //打印标记点内容数据
println(neg.label) //打印既定标记
}
}

注意:
val pos = LabeledPoint(1, vd)
val neg = LabeledPoint(2, vs)
除了这两种建立向量标签。还可以从数据库中获取固定格式的数据集方法。
数据格式如下:
label index1:value1 index2:value2
label是此数据集中每一行给定的标签,而后的index是标签所标注的这一行的不同的索引值,而紧跟在各自index后的value是不同索引所形成的数据值。
testLabeledPoint2.scala
package zhouls.bigdata.chapter4
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark._
import org.apache.spark.mllib.util.MLUtils
object testLabeledPoint2 {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("testLabeledPoint2")//建立本地环境变量
val sc = new SparkContext(conf) //建立Spark处理
val mu = MLUtils.loadLibSVMFile(sc, "data/input/chapter4/loadLibSVMFile.txt") //读取文件
mu.foreach(println) //打印内容
}
}
以下是数据
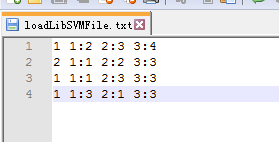
输出结果是
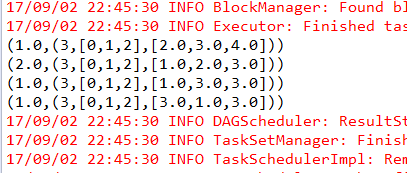
(1.0,(3,[0,1,2],[2.0,3.0,4.0])) (2.0,(3,[0,1,2],[1.0,2.0,3.0])) (1.0,(3,[0,1,2],[1.0,3.0,3.0])) (1.0,(3,[0,1,2],[3.0,1.0,3.0]))

具体,见