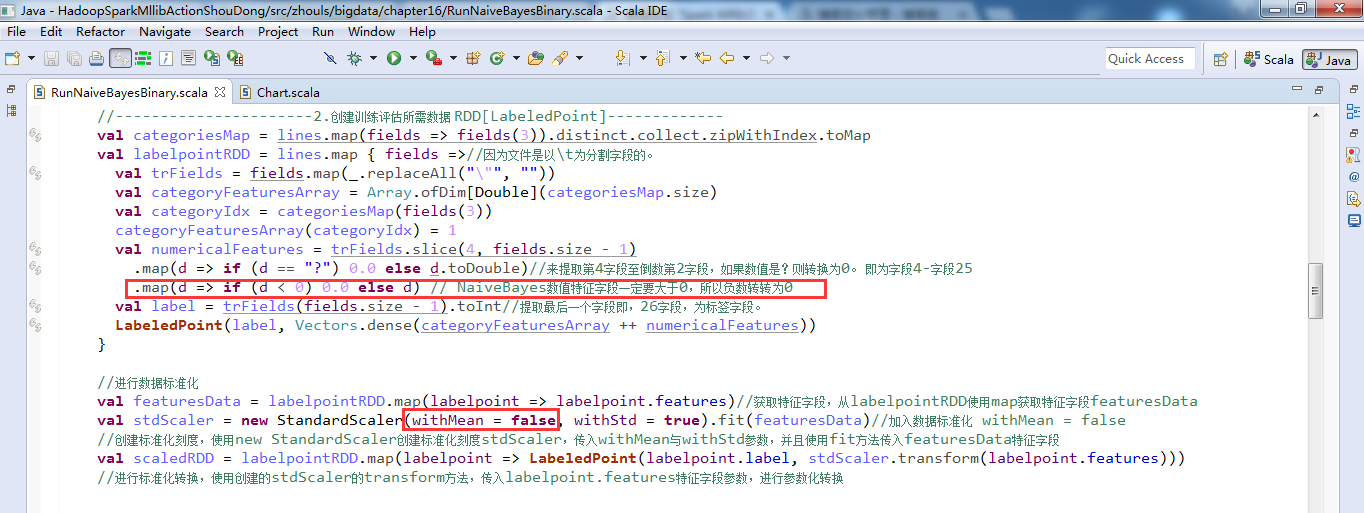
Spark Mllib里使用贝氏二元分类时如何将数值特征字段用StandardScaler进行标准化(图文详解) 不多说,直接上干货! NaiveBayes数值特征字段一定要大于0,所以加入下述命令将负数转换为0。 朴素贝叶斯分类算法在进行数据标准化时,参数withMean必须设置为false。 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第16章 朴素贝叶斯二元分类算法来预测分类StumbleUpon数据集