最近在学习大数据的一些知识,了解到了MapReduce的用处,下面我先讲解一下MapReduce的作用。
MapReduce其实是分为两种:一是map,而是reduce,MapReduce是Hadoop的重要组件,是分布式计算的框架,是一种编程模型,下面我从wordcount这个算法来解析一下到底什么是MapReduce,map和reduce的作用分别是什么。
现在我们有一个文本文件,我们要计算统计出每一个单词在这个文本中出现的次数,下面来看看文本的内容。

MapReduce的第一步就是先进行map操作,所谓map操作就是统计出文本中每行字符串中每个字符串出现的次数,而在map中的文本读取方式就像一个hashMap,有个key,还有一个value,什么是key,就是关键字,这里我们的关键字当然就是每个单词了,而value,就是值,这里我们的value当然就是每个单词出现的次数了,
例如第一行,经过map操作后统计出来的值就是下图所示,将每个单词作为key,由于读取的时候是一个单词一个单词的分割的,所以每个单词的value都只有1,统计完成之后,将这样一种格式的文件传给reduce,然后reduce进行计算,
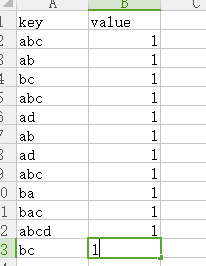
而reduce接收到的文件并非是上面这种形式的文件,而是讲过分类的,就是将相同的key作为一个模块放到一起,接收到的是下面这种形式的文件。相同的key作为一个模块


收到文件后,reduce所需要做的就是计算,在这里我们写算法俩完成我们需要做的操作,我们所需要做的就是将相同的key数量统计,输出上面橘色部分格式的文件。
总体来说,map就是进行数据的提取,然后进行相同的数据进行分块,而reduce就是进行计算的。下面来看看源代码:
Map的代码:
package com.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /* * 下面有四个参数LongWritable, Text, Text, IntWritable * 第一个参数LongWritable就是读取的文件的偏移量,就是每行第一个字符的偏移量 * 第二个参数Text就是读取每行数据的类型,hdfs中用Text来封装字符串 * 第三个参数Text,就是写入到reduce中key的类型,这里我们是字符型就是Text * 第四个参数IntWritable,就是写入到reduce中value的类型,这里我们的整型,hdfs封装整型的是IntWritable */ public class Mymap extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO 自动生成的方法存根 //将获取的文本字符串value装换为Java的String类型,每行的数据 String line = value.toString(); //将每行的数据去空格,得到的是一个String类型的数组 String[] words = line.split(" "); //将每一行的数组写进reduce里面,reduce是map的下文,在上下文里面写 for (String word : words) { context.write(new Text(word.trim()), new IntWritable(1)); } } }
Reduce:的代码
package com.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /* * 下面有四个参数LongWritable, Text, Text, IntWritable * 第一个参数Text就是从map中获取的key的类型,这里是字符型Text * 第二个参数IntWritable就是从map中获取的value的类型,这里是整型 * 第三个参数Text,就是输出文件的key的类型,这里是字符型 * 第四个参数IntWritable,就是输出文件的value的类型,这里是整型 */ public class Myreduce extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO 自动生成的方法存根 //values就是每块的数据的value值,是个数组 int sum=0; //统计每一个字符串出现的次数 for (IntWritable intWritable : values) { sum+=intWritable.get(); } //写进输出文件,在下文中写 context.write(key, new IntWritable(sum)); } }
Myjob,这个类主要就是提交作业到hadoop上,在Hadoop上进行计算
package com.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class Myjob extends Configured implements Tool{ public static void main(String[] args) { // TODO 自动生成的方法存根 Myjob myjob=new Myjob(); try { ToolRunner.run(myjob, null); } catch (Exception e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } } @Override public int run(String[] arg0) throws Exception { // TODO 自动生成的方法存根 //先连接hdfs,获取文件 Configuration configuration=new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.153.11:9000"); //创建一个工作对象 Job job=Job.getInstance(configuration); //设置当前的工作对象 job.setJarByClass(Myjob.class); //设置map对象类 job.setMapperClass(Mymap.class); //设置reduce对象类 job.setReducerClass(Myreduce.class); //设置输出的key类型 job.setOutputKeyClass(Text.class); //设置输出的value类型 job.setOutputValueClass(IntWritable.class); //设置输入的文件位置 FileInputFormat.addInputPath(job, new Path("/hadoop/hadoop.txt")); //设置输出的文件位置 FileOutputFormat.setOutputPath(job, new Path("/hadoop/out")); job.waitForCompletion(true); return 0; } }