在Kubernetes中,容器化一个应用比较麻烦的地方莫过于对其"状态"的管理,而最常见的"状态",莫过于存储状态.
在[Kubernetes]深入理解StatefulSet这篇文章中,稍微提了一下PV(Persistent Volume)和PVC(Persistent Volume Claim),这篇文章详细说一说.
| 大概了解 |
我先大体说一下整个过程,有一个小小的认识,然后我再详细展开说.
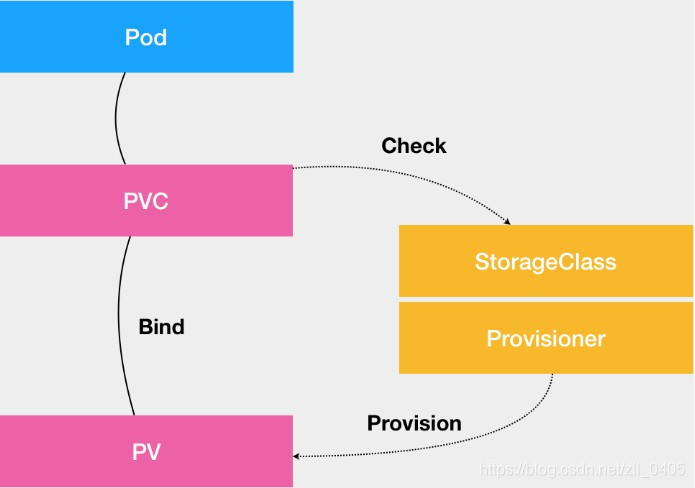
用户提交请求创建Pod时,Kubernetes发现这个Pod声明使用了PVC,这时就需要PersistentVolumeController帮它找一个PV来进行配对.如果有的话呢,就直接进行绑定.但是如果没有呢?就去找对应的StorageClass,帮它新创建一个PV,然后再和PVC进行绑定.但是请注意,此时新创建的PV,只是一个API对象,还需要经过"两阶段"处理变成宿主机上的"持久化Volume"才算是真正有用.这个时候,Pod就可以正常启动,并将相关文档挂载到容器内指定的路径.
我知道你对上面的过程肯定有些懵了,别急,咱们慢慢把这个过程剖析一下.
| 持久化Volume |
比较难理解的应该就是需要经过"两阶段"处理变成宿主机上的"持久化Volume"这部分内容了.
所谓"持久化Volume",指的就是这个宿主机上的目录,具备"持久性",也就是说:这个目录里面的内容,既不会因为容器的删除而被清理掉,也不会和当前的宿主机进行绑定.这样,当容器被重启或者在其他节点上重建出来之后,仍然能够通过挂载这个Volume来访问到目录里面的内容.
这里面主要有两个关键点:一,不会因为容器的删除而清理掉里面的内容,二,不会和当前的宿主机进行绑定.Kubernetes需要做的工作就是达到这两个目的,从而使得目录具备"持久性".
Kubernetes在这个准备"持久化"宿主机目录的过程中,我们可以形象的称为"两阶段处理":
第一阶段:为虚拟机挂载磁盘,把这个阶段称为"Attach".
第二阶段:挂载磁盘之后,如果想要使用,还需要将挂载的磁盘进行格式化处理,并挂载到Volume宿主机目录上,这个阶段称为"Mount",而这个挂载点,正是Volume的宿主机目录.所以,Mount阶段的操作,可以这样来表示:
# 通过 lsblk 命令获取磁盘设备 ID
$ sudo lsblk
# 格式化成 ext4 格式
$ sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/< 磁盘设备 ID>
# 挂载到挂载点
$ sudo mkdir -p /var/lib/kubelet/pods/<Pod 的 ID>/volumes/kubernetes.io~<Volume 类型 >/<Volume 名字 >
#如果kubelet需要作为client,将远端NFS服务器的目录挂载到Volume的宿主机目录上,则需要执行以下命令:
$ mount -t nfs <NFS 服务器地址 >:/ /var/lib/kubelet/pods/<Pod 的 ID>/volumes/kubernetes.io~<Volume 类型 >/<Volume 名字 >
以上两个阶段完成之后,我们在这个目录里写入的所有文件,就都会被保存起来,从而实现了对这个Volume宿主机目录的"持久化".(如果给虚拟机扩充过磁盘的话,对这一部分内容应该是比较容易理解的)
但是对于Kubernetes来说,它是如何定义和区分这两个阶段的呢?
其实很简单,在具体的Volume插件的实现接口上,Kubernetes分别给这两个阶段提供了两种不同的参数列表:
| StorageClass |
PV这个对象的创建,是由运维人员来完成的,但是在大规模的生产环境中,这其实是一个非常麻烦的操作.因为在一个大规模的Kubernetes集群里,可能有成千上万个PVC,这就意味着运维人员必须实现创建出这个多个PV,此外,随着项目的需要,会有新的PVC不断被提交,那么运维人员就需要不断的添加新的,满足要求的PV,否则新的Pod就会因为PVC绑定不到PV而导致创建失败.这在自动化中,肯定是不能被允许的.
所以,Kubernetes提供了一套可以自动创建PV的机制,即:Dynamic Provisioning.而这个机制的核心在于:StorageClass这个API对象.
- 1,PV的属性.比如,存储类型,Volume的大小等.
- 2,创建这种PV需要用到的存储插件
有了这两个信息之后,Kubernetes就能够根据用户提交的PVC,找到一个对应的StorageClass,之后Kubernetes就会调用该StorageClass声明的存储插件,进而创建出需要的PV.
但是其实使用起来是一件很简单的事情,你只需要根据自己的需求,编写YAML文件即可,然后使用kubectl create命令执行即可.
| 最后小结 |
到这里,讲的就差不多了.
综上所述呢,PVC描述的是Pod想要使用的持久化存储的属性,比如存储的大小,读写权限等.而PV则是一个具体的Volume属性,比如Volume的类型,挂载目录等.而StorageClass的作用,则是充当PV的模板,从而可以动态创建需要的PV.
最后,放一张图片,描述一下概念之间的关系:
| 些许的碎碎念 |
最后的最后,写点儿碎碎念.如果看的进去的话,就看看,看不进去,就算了.
今天早上打开手机,收到了一条消息:

在上面介绍StorageClass的时候,我说了,如果想要使用的话,其实是一件很简单的事情,只需要写一下YAML文件即可.但是背后的原理如果不去深究,不去学习的话,遇到问题的时候,还是无从下手的.
还记得当时倒腾k8s,一个月的时间就倒腾的差不多了,项目上线的时候,也是有惊无险的撑了下来.所以呢,如果只是达到会用的层次的话,一个月的时间就差不多了.
但是如果想要有所提高,想要在遇到问题时,能够准确定位,还是需要再回来补充理论.
做技术,前期的实践固然是不可少,但是后期的理论也要做.绝对不能仅仅停留在会用的层次上面,如果有时间,有精力,最好还是能够再深入理解一下背后的原理知识.
这也是我一直坚持的学习方法:基于实践,补充理论.
以上内容来自我学习<深入剖析Kubernetes>专栏文章之后的一些见解,有偏颇之处,还望指出.
感谢您的阅读~