

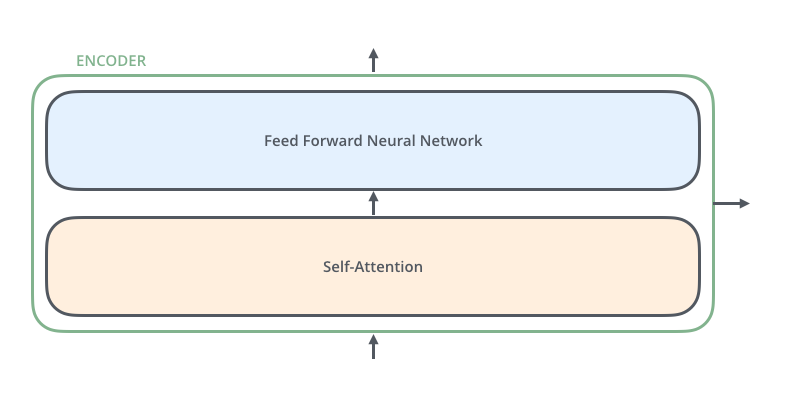
The encoders are all identical in structure (yet they do not share weights). Each one is broken down into two sub-layers:
https://kexue.fm/archives/4765
https://jalammar.github.io/illustrated-transformer/
http://nlp.seas.harvard.edu/2018/04/03/attention.html
https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb#scrollTo=r6GPPFy1fL2N