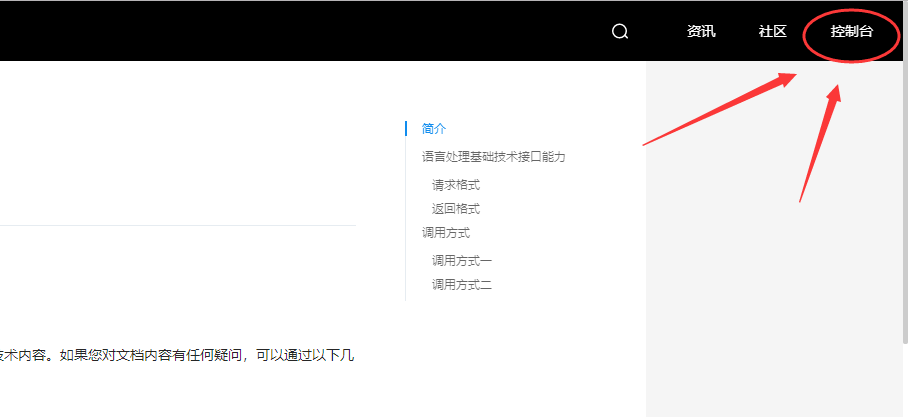
1、进入百度API自然语言处理文档
进入右上角的控制台,注册登录
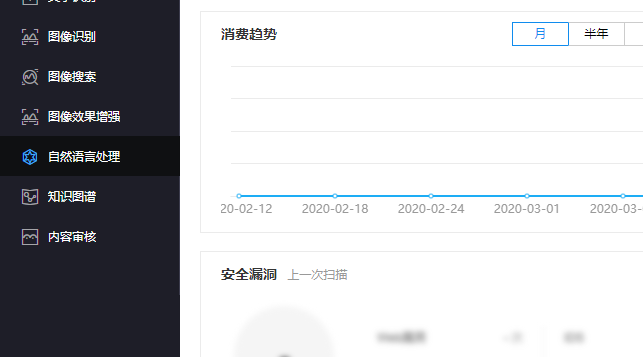
左侧导航栏选择自然语言处理
创建自己的应用
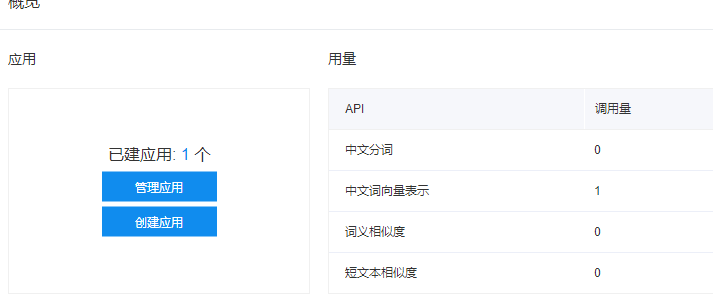
输入应用名称以及应用描述,其他默认即可。
在如下页面记住自己的API Key以及SecretKey

2.文章标签接口
2.1接口描述
文本标签服务对文章的标题和内容进行深度分析,输出能够反映文章关键信息的主题、话题、实体等多维度标签以及对应的置信度,该技术在个性化推荐、文章聚合、内容检索等场景具有广泛的应用价值。
2.2请求说明
请求示例
HTTP方法: POST
请求URL: https://aip.baidubce.com/rpc/2.0/nlp/v1/keyword
URL参数:
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例:
1 { 2 "title":"iphone手机出现“白苹果”原因及解决办法,用苹果手机的可以看下", 3 "content": "如果下面的方法还是没有解决你的问题建议来我们门店看下成都市锦江区红星路三段99号银石广场24层01室。在通电的情况下掉进清水,这种情况一不需要拆机处理。尽快断电。用力甩干,但别把机器甩掉,主意要把屏幕内的水甩出来。如果屏幕残留有水滴,干后会有痕迹。^H3 放在台灯,射灯等轻微热源下让水分慢慢散去。" 4 }
2.3请求格式
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
- GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
- UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如 https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数
| 参数 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
| title | string | 文章标题,最大80字节 | 必填 |
| content | string | 文章内容,最大65535字节 | 必填 |
返回格式
JSON格式
默认返回内容为GBK编码
若用户指定输入为UTF-8编码(通过指定charset参数),则返回内容为UTF-8编码
返回参数
| 参数 | 说明 | 描述 |
|---|---|---|
| items | array of objects | 分析结果数组 |
| +tag | string | 内容标签 |
| +score | float | 权重值,取值范围[0,1] |
返回示例
1 { 2 "log_id": 4457308639853058292, 3 "items": [ 4 { 5 "score": 0.997762, 6 "tag": "iphone" 7 }, 8 { 9 "score": 0.861775, 10 "tag": "手机" 11 }, 12 { 13 "score": 0.845657, 14 "tag": "苹果" 15 }, 16 { 17 "score": 0.83649, 18 "tag": "苹果公司" 19 }, 20 { 21 "score": 0.797243, 22 "tag": "数码" 23 } 24 ] 25 }
我的示例代码:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : 文章标签.py # @Author: 赵路仓 # @Date : 2020/3/12 # @Desc : # @Contact : 398333404@qq.com import requests import json from tornado.escape import json_decode def Tag(title,content): tag='' APIKey='你的APIKey' secret='你的Secret Key' host='https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+APIKey+'&client_secret='+secret response = requests.get(host) if response: print(response.json()['access_token']) kv={ 'accept-encoding': 'gzip, deflate', 'x-bce-date': '2015-03-24T13:02:00Z', 'connection': 'keep-alive', 'accept': '*/*', 'host': 'aip.baidubce.com', 'x-bce-request-id': '73c4e74c-3101-4a00-bf44-fe246959c05e', 'content-type': 'application/json', 'authorization': 'bce-auth-v1/46bd9968a6194b4bbdf0341f2286ccce/2015-03-24T13:02:00Z/1800/host;x-bce-date/994014d96b0eb26578e039fa053a4f9003425da4bfedf33f4790882fb4c54903' } params = { "title":title, "content": content } text=json.dumps(params) # print(type(text)) url='https://aip.baidubce.com/rpc/2.0/nlp/v1/keyword?charset=UTF-8&access_token='+response.json()['access_token'] response1=requests.post(url,headers=kv,timeout=5,data=text) if response1: result=json.dumps(response1.json(), sort_keys=True, indent=4, ensure_ascii=False) print(result) result1=json_decode(result) for i in result1['items']: tag+=i['tag']+' ' return tag if __name__=="__main__": print(Tag("iphone手机出现“白苹果”原因及解决办法,用苹果手机的可以看下","如果下面的方法还是没有解决你的问题建议来我们门店看下成都市锦江区红星路三段99号银石广场24层01室。在通电的情况下掉进清水,这种情况一不需要拆机处理。尽快断电。用力甩干,但别把机器甩掉,主意要把屏幕内的水甩出来。如果屏幕残留有水滴,干后会有痕迹。^H3 放在台灯,射灯等轻微热源下让水分慢慢散去。"))
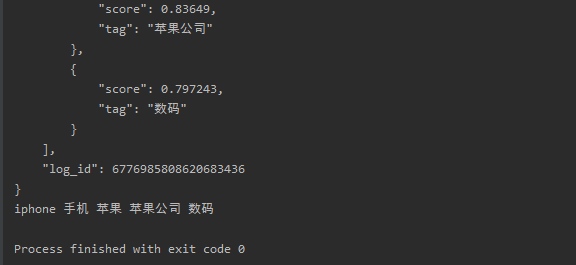
运行结果