上课时所讲的 质量属性 性能战术 可以用下图进行展示:
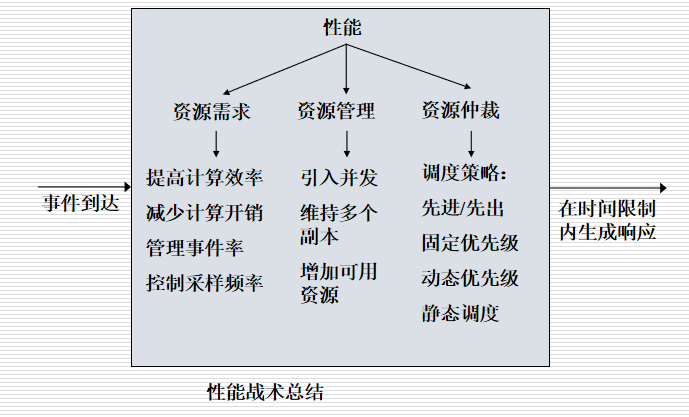
性能战术定义:
性能与时间有关。事件发生时,系统必须对其做出响应。事件到达和响应有很多特性,但性能基本上与事件发生时,将要耗费系统多长时间做出响应有关。
在使性能变得复杂的众多因素中,其中一个因素就是事件源的数量和到达模式。事件可以来自用户请求、其他系统或系统内部。到达模式可以分为周期性的、随机的或偶然性的。
可以用等待时间、处理期限、系统吞吐量、响应抖动(等待时间的变化)、缺失率(由于系统太忙因而无法做出响应所导致的未处理事件的数量)、数据丢失(因为系统太忙所丢失的数据)等指标来度量。
性能战术的目标就是对在一定的时间限制内到达系统的事件生成一个响应。到达系统的可以是单个事件,也可以是事件流的形式,它是请求执行计算的触发器。它可以是消息的到达、定时器到时、系统环境中重要的状态变化的检测,等等。系统对事件进行处理并生成一个响应。性能战术控制生成响应的时间。等待时间是事件到达和对该事件生成响应之间的时间。
总结为:
- 提高计算效率,如改进关键算法。 比如,在我们进行数据查找时,采用二分查找法可以大大减少查找时间。
- 减少计算开销。 比如保存上次计算的结果。
- 减少所处理事件的数量。
- 控制资源的使用:限制执行时间;比如,我们读取硬件数据,要求必须在指定的最长时间内返回。限制队列大小,控制处理事件数量; 比如,限制消息队列的大小,不接受过多的事件涌入。
- 引入并发(Introduce concurrency ):通过并行处理,减少闭锁时间;
- 维持数据或计算的多个副本(Maintain multiple copies ):维持副本可以减少相同的计算;
- 增加可用资源(Increase available resources ):比如增加CPU速度、增加内存等。
- 当存在资源争用时,必须对资源进行调度,以使资源协调一致的运行,以减少闭锁时间。
资源消耗:包括CPU、数据存储、网络通信带宽和内存,但它也可以包括由设计中的特定系统所定义的实体。例如必须对缓冲器进行管理,并且对关键部分的访问必须是按顺序进行的。事件可以是各种类型的,每种类型的事件都经过了一个处理序列。
对其他计算的依赖性:计算可能必须等待,因为它必须与一个计算的结果同步,或者是因为它在等待它所启动的一个计算的结果。例如,它可能会从两个不同的源读取信息,如果这两个源是按顺序读取的话,等待时间将会比并行读取高。
1、全文索引
索引教程:https://www.cnblogs.com/qianzf/p/7131741.html
我在信息领域热词分析系统里面寻找可以提高性能,以及因为计算导致系统反应慢的地方,首先我找到的搜索。

在我爬取的信息领域热词引用的文章txt有36M共36万条数据,在这个搜索过程中我想到了以前没有用过的全文索引,于是我系统的看了一下建立全文索引以及使用的教程。


1 在进行全文检索之前,必须先建立和填充数据库全文索引。为了支持全文索引操作,SQL Server 7.0新增了一些存储过程和Transact-SQL语句。使用这些存储过程创建全文索引的具体步骤如下(括号内为调用的存储过程名称): 2 1. 启动数据库的全文处理功能(sp_fulltext_ 3 database);; 4 2. 建立全文检索目录(sp_fulltext_catalog); 5 3.在全文检索目录中注册需要全文索引的表(sp_fulltext_table); 6 4. 指出表中需要全文检索的列名(sp_fulltext_ 7 column);; 8 5. 为表创建全文索引(sp_fulltext_table);; 9 6. 填充全文检索目录(sp_fulltext_catalog)。 10 下面举例说明如何创建全文索引,在本例中,对Test数据库Book表中Title列和Notes列建立全文索引 11 use test //打开数据库 12 //打开全文索引支持,启动SQL Server的全文搜索服务 13 execute sp_fulltext_database ‘enable’ 14 //建立全文检索目录ft_test 15 execute sp_fulltext_catalog ‘ft_test’, ‘create’ 16 为Title列建立全文索引数据元,pk_title为Book表中由主键所建立的唯一索引,这个参数是必需的。 17 execute sp_fulltext_table ‘book’,‘create’, ‘ft_test’,‘pk_title’ 18 //设置全文索引列名 19 execute sp_fulltext_column ‘book’, ‘title’, ‘add’ 20 execute sp_fulltext_column ‘book’,‘notes’, ‘add’ 21 //建立全文索引 22 execute sp_fulltext_table ‘book’, ‘activate’ 23 //填充全文索引目录 24 execute sp_fulltext_catalog ‘ft_test’, ‘start_full’ 25 至此,全文索引建立完毕。 26 进行全文检索 27 SQL Server 2000提供的全文检索语句主要有CONTAINS和FREETEXT。CONTAINS语句的功能是在表的所有列或指定列中搜索:一个字或短语;一个字或短语的前缀;与一个字相近的另一个字;一个字的派生字;一个重复出现的字。
然后进行热词相关性搜索的比较,利用CONTAINS使搜索时间缩短到原来的1/5。
在百度后发现别人的回答:对于数据量小的数据建立索引,性能提高不明显;

2、处理超时
java超时操作教程地址:https://blog.csdn.net/u011494923/article/details/86570565
一些批处理程序的多线程操作会由于并发太多导致长时间没有返回响应,影响性能。而设置一段代码的超时时间,如果处理超时就忽略该错误继续向下执行。可以优化性能。
对于如下两种问题,可以用超时处理进行解决:
- 闭锁时间:可能会由于资源争用、资源不可用或者计算依赖于另外一个还不能得到的计算结果而导致计算不能使用某个资源,从而阻止了计算的进行。资源争用。这些事件可能是单个流,也可能是多个流。争用同一个资源的多个流或相同流中争用同一个资源的不同事件会增加等待时间。
- 资源的可用性:即使没有争用,如果资源不可用,计算也无法进行下去。资源离线、组件故障、或其他原因都会导致资源不可用。在任何情况下,设计师都必须确定资源不可用可能会导致急剧增加等待时间的位置。
对于我们项目中的一些计算、以及查询数据库等等操作,如果对服务器负担太大,需限制程序运行的时间,以免占用资源时间过长争用资源。
代码:
1 public List<BlogBean> BlogHrefChaoshi(String KEY_WORD,int page) { 2 // TODO Auto-generated method stub 3 List<BlogBean> bgs =new ArrayList<BlogBean>(); 4 final ExecutorService exec = Executors.newFixedThreadPool(1); 5 Callable<String> call = new Callable<String>() { 6 public String call() throws Exception { 7 //开始执行耗时操作 8 // TODO Auto-generated method stub 9 int count=0; 10 Connection conn = DBUtil.getConn(); 11 PreparedStatement ps = null; 12 ResultSet rs = null; 13 //构建查询语句 14 int max=page*20; 15 int min=(page-1)*20; 16 //String sql = "select * from Blog where blog like '%"+KEY_WORD+"%'"; 17 String sql = "select * from blog1 where contains(blog,'"+KEY_WORD+"')"; 18 try { 19 ps= conn.prepareStatement(sql); 20 //从数据库返回一个结果集,使用ResultSet进行接收 21 rs = ps.executeQuery(); 22 while(rs.next()){ 23 if(count<max&count>=min) { 24 BlogBean bg =new BlogBean(); 25 bg.setBlog(rs.getString("blog")); 26 bg.setHref(rs.getString("href")); 27 bgs.add(bg); 28 } 29 count++; 30 } 31 if(ps!=null)ps.close(); 32 if(conn!=null)conn.close(); 33 } catch ( SQLException e) { 34 // TODO Auto-generated catch block 35 e.printStackTrace(); 36 } 37 return "线程执行完成."; 38 } 39 }; 40 try { 41 Future<String> future = exec.submit(call); 42 String obj = future.get(10, TimeUnit.MILLISECONDS); //任务处理超时时间设为 1 秒 43 System.out.println("任务成功返回:" + obj); 44 45 } catch (TimeoutException ex) { 46 System.out.println("处理超时啦...."); 47 48 ex.printStackTrace(); 49 } catch (Exception e) { 50 System.out.println("处理失败."); 51 e.printStackTrace(); 52 } 53 // 关闭线程池 54 exec.shutdown(); 55 return bgs; 56 }
3、查询间隔
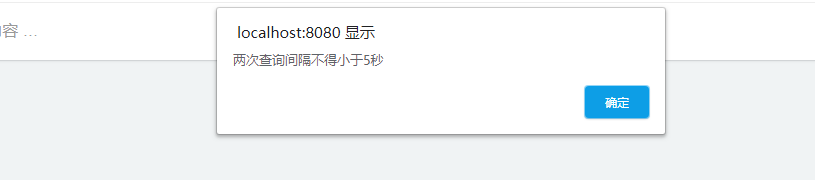
查看过的一些论坛的查询操作有时间间隔的限制,减小查询的负担。
两次查询间隔不得小于5秒。防止恶意程序以及控制查询量,如果连续查询会弹框。
代码:
1 long startTime=System.currentTimeMillis(); 2 try{ 3 if((long)session.getAttribute("endTime")-(long)session.getAttribute("startTime")> 0){ 4 if((long)session.getAttribute("endTime")-(long)session.getAttribute("startTime")<5000){ 5 out.print("<script>alert('两次查询间隔不得小于5秒'); window.location='blogSearch.jsp' </script>"); 6 } 7 session.setAttribute("startTime", startTime); 8 } 9 } 10 catch(Exception e){ 11 session.setAttribute("startTime", startTime); 12 }
4、减少计算开销。 比如保存上次计算的结果。
将计算结果存入session,可以让复杂的计算只执行一次,提高计算效率,提高性能。
比如网站的缓存。将视频内容存入本地,当再次播放时可以减少网络的负担,提高性能。

5、引入并发
多性能以及效率问题:https://blog.csdn.net/ll641058431/article/details/80641285
还在单核时代,多线程就有很广泛的应用,这时候多线程大多用于降低阻塞(意思是类似于这样的代码)
1 while(1) 2 3 { 4 5 if(flag==1) 6 7 break; 8 9 sleep(1); 10 11 }
带来的CPU资源闲置,注意这里没有浪费CPU资源,去掉sleep(1)就是纯浪费了。阻塞在什么时候发生呢?一般是等待IO操作(磁盘,数据库,网络等等)。如果读取需要20毫秒,那么CPU空转20毫秒,是一种资源的浪费。
这种耗时的IO操作就用一个线程Thread去代为执行,创建这个线程的函数部分不会被IO操作阻塞,继续干这个程序中其他的事情,而不是干等待(或者去执行其他程序)。
在我理解就是五个人排着队干活,没有五个人干五分活来的效率更高。
前者要等待的时间比猴子
如下有两种常用的战术:
- 单一的共享数据分布化:把一个数据复制很多份,让不同线程可以同时访问。
- 负载均衡,采用集群部署,就像话剧院有多个入口一样。这时候,就需要一个协调者,来均衡的分配这些用户的请求,可以让用户的可以均匀的分派到不同的服务器上。
例:多线程计算1-100的和
1 package thread; 2 3 public class ThreadAdd { 4 public static int sum = 0; 5 public static Object LOCK = new Object(); 6 7 8 public static void main(String[] args) throws InterruptedException { 9 ThreadAdd add = new ThreadAdd(); 10 ThreadTest thread1 = add.new ThreadTest(1, 25); 11 ThreadTest thread2 = add.new ThreadTest(26, 50); 12 ThreadTest thread3 = add.new ThreadTest(51, 75); 13 ThreadTest thread4 = add.new ThreadTest(76, 100); 14 thread1.start(); 15 thread2.start(); 16 thread3.start(); 17 thread4.start(); 18 19 thread1.join(); 20 thread2.join(); 21 thread3.join(); 22 thread4.join(); 23 System.out.println("total result: "+sum); 24 } 25 26 class ThreadTest extends Thread { 27 private int begin; 28 private int end; 29 30 @Override 31 public void run() { 32 synchronized (LOCK) { 33 for (int i = begin; i <= end; i++) { 34 sum += i; 35 } 36 System.out.println("from "+Thread.currentThread().getName()+" sum="+sum); 37 } 38 } 39 40 public ThreadTest(int begin, int end) { 41 this.begin = begin; 42 this.end = end; 43 } 44 } 45 }
6、轮转调度算法和动态优先级算法
由于系统简单,没有用到该种战术,所以对这两种战术只进行了了解。
轮转调度算法中,应在何时进行进程的切换,可分成两种情况:
1.若一个时间片尚未用完,正在运行的进程便已经完成,就立即激活调度程序,将它从就绪队列中删除,在调度就绪队列中队首的进程运行,并启动一个新的时间片。同时优先级+1
2.在一个时间片用完时,计时器中断处理程序被激活。如果进程尚未运行完毕,调度程序将把它送往就绪队列的末尾。同时优先级-1
时间片大小优缺点:时间片小,意味着会频繁地执行进程调度和进程上下文的切换,这无疑会增加系统的开销。反之,若事件片选择的太长,且为使每个进程都能在一个时间片内完成
简单实例代码:
1 mport java.util.ArrayList; 2 import java.util.List; 3 4 /** 5 * Created by 32706 on 2016/12/8. 6 * 用于生成随机的进程列表,并测试三种不同的调度算法 7 */ 8 public class Process { 9 10 public static List<double []> task_info=new ArrayList<>();//进程列表 11 public static int task_num=8;//进程数 12 13 14 public static void init_task()//初始化进程列表 15 { 16 for(int i=0;i<task_num;i++) 17 { 18 double[] t=new double[4]; 19 t[0]=i;//进程号 20 t[1]=0;//到达时间 21 t[2]=0;//响应比 22 t[3]=(int)(Math.random()*100)%20+1;//需要运行时间 23 task_info.add(t); 24 } 25 } 26 27 public static void main(String arg[]) 28 { 29 Process.init_task();//初始化进程列表 30 31 32 System.out.println("最短作业优先================================================"); 33 SJF.init_task(task_info,task_num); 34 SJF.SJF();//最短作业优先 35 36 37 System.out.println(" 最高相应比================================================"); 38 HRRN.init_task(task_info,task_num); 39 HRRN.HRRN();//高相应比 40 41 42 System.out.println(" 时间片轮转================================================"); 43 RR.init_task(task_info,task_num); 44 RR.CircleTime();//时间片轮转 45 46 47 } 48 }
动态优先级调度算法是指在创建进程之初,先赋予其一个优先级,然后其值随着进程的推进或等待时间的增加而改变,以便获得更好的调度性能。
例如,可以规定在就绪队列中的进程随其等待的时间的正常,使其优先级相应提高。若所有的进程都具有相同的优先级初值,则最先进入就绪队列的进程会因为其优先级变得最高,而优先获得处理机。若所有的就绪进程具有各不相同的优先级初值,那么对于优先级初值低的进程,在等待了足够的时间后,也可以获得处理机。