
原文链接:https://arxiv.org/pdf/1911.06258
Motivation

任务为TextVQA(详情见上一篇推送)。现有模型大多是基于两个模态的结合机制(如问题与图片特征的attention、问题与OCR提取文本的attention等),将TextVQA当做分类任务,并且单步产生答案(从OCR赋值或者直接生成。作者提出了M4C模型,基于多模态(问题、图片、文本)的transformer架构和对于图片中文本的丰富表征,将所有模态中的实体投射到一个共同的语义embedding空间,并进行self-attention,可以进行分步预测产生答案。
Model

模型将问题中的单词、图片中识别到的物体、OCR识别文本作为向量投射到一个共同的embedding空间中,然后在所有的特征上使用多层transformer,丰富单个模态内以及模态相互之间的表征。解码时输入前一步的预测结果来进行下一步预测,每一步从OCR文本中复制或者从固定词汇表中选取。

共同embedding空间
问题单词embedding:用预训练的BERT对单词进行embedding,并进行微调。
识别物体embedding:用Faster R-CNN识别物体,对每个物体提取外观特征x^fr_m,再引入四维向量x^br_m表示位置特征,其中x^br_m=
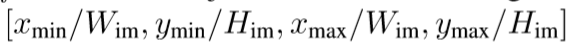
W和H是图片的宽度和高度。随后用线性变换将两个特征投射到d维空间并求和。

LN是layer normalization。最终的embedding为d维。
OCR文本embedding:表示了文本的字符、外观(字体颜色等)、空间位置信息。首先用OCR提取出文本,然后
①对每个OCR token用FastText得到向量x^ft_n(word embedding并含有subword信息);
②对bounding box使用Faster R-CNN提取特征;
③用PHOC提取token中的字符特征;
④获得bounding box的位置特征,与物体的位置类似。

最终OCR embedding为:

模态融合以及分步预测
对K个问题embedding、M个物体embedding、N个OCR embedding组成的d维空间,使用L层Transformers,使得每个实体可以自由地和与其他实体结合,即便不是来自同一个模态。Transformers的输出是一系列d维向量。
通过迭代解码来预测答案,解码器与transformer层相同。一共进行T步,每一步的单词来自OCR或者固定词汇表。解码时会将前一步的预测单词输入,用动态指针网络预测下一个单词。设

是OCR token经过transformers的输出,第t步transformer对应x^dec_t输出z^dec_t,据此预测V维词汇表第i个单词的分数y^voc_t,i,以及N维OCR分数第n个token的分数y^ocr_t,n。

拼接后对y^all_t取argmax,选择得分最高的元素作为本步预测结果。
如果t步的预测单词是OCR单词,就在t+1步将其表征x^ocr_n当做transformer的输入x^dec_t+1;如果t步预测的是固定词汇表中的单词,就将其对应的权重向量w^voc_i当做x^dec_t+1。
额外加入了位置embedding以及type embedding(用来说明上一步预测来自OCR还是词汇表)。加入了<begin>和<end>token作为预测的起始和终止。
训练时对于OCR单词和词汇表单词,使用多标签sigmoid loss。其他参数细节见论文4.1节及附表。
Experiments

首先是TextVQA数据集上的实验。图中LoRRA为TextVQA数据集的baseline模型,w/o dec代表去除迭代预测步骤。DCD_ZJD是2019年TextVQA challenge的冠军模型,MSFT_VTI是今年M4C出现前的第一名。最后一行的模型使用了ST-VQA数据集参与预训练。

上图中分别删去了M4C答案空间中的固定词汇表、OCR文本,准确率均有很大下滑,体现出同时使用固定词汇表、动态OCR单词的重要性。
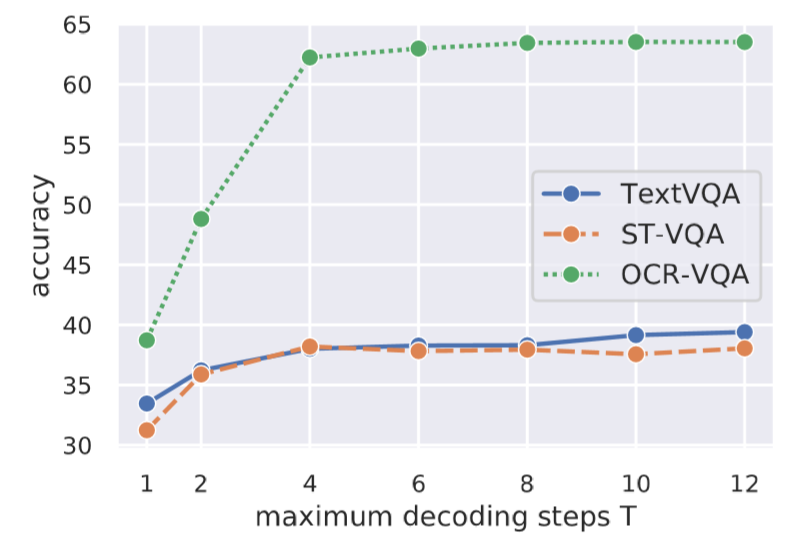
本图分析了最大解码步数对正确率的影响。从一步到两步经历了一个很大的性能提升。

上图为在ST-VQA数据集上的实验,ST-VQA与TextVQA类似,不同之处在于采取了ANLS作为评价指标。M4C比冠军模型VTA的ANLS提高了0.18。

上图为在OCR-VQA数据集上的实验。OCR-VQA的数据主要为书籍封面,询问的问题包括作者、题目、版本、年代等等,问题较为固定且数据较多,因而准确率较高。

上图为ST-VQA上一些预测结果的示例,蓝色表示来自固定词汇表,黄色表示来自OCR。f和h说明模型对于大量文本或者文本和物体关系密切的问题存在缺陷。

上图为TextVQA上一些错误示例,结果说明错误的主要来源是OCR错误,因而可以通过改善OCR模型来提升性能。