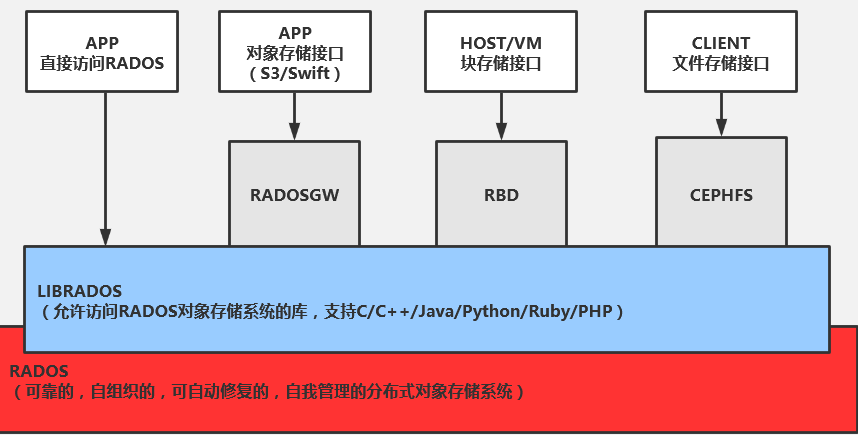
一、ceph的架构和术语
不管你是想为云平台提供Ceph 对象存储(RGW)和/或 Ceph 块设备(RBD),还是想部署一个 Ceph 文件系统(CephFS)或者把 Ceph 作为他用,所有 Ceph 存储集群的部署都始于部署一个个 Ceph 节点、网络和 Ceph 存储集群。 Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。
- Ceph OSDs: Ceph OSD 守护进程( Ceph OSD ):存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数)。
- Monitors: Ceph Monitor:维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
- MDSs: Ceph 元数据服务器( MDS ):为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
Ceph 把客户端数据保存为存储池内的对象。通过使用 CRUSH 算法, Ceph 可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个 OSD 守护进程持有该归置组。 CRUSH 算法使得 Ceph 存储集群能够动态地伸缩、再均衡和修复。
http://docs.ceph.org.cn/architecture/ ceph的体系结构
1、PG (Placement Grouops):
PG是一个逻辑概念,它在数据寻址时类似于数据库中的索引:每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移,ceph不会直接操作对象。一个PG包含多个OSD,引入PG这一层其实是为了更好的分配数据和定位数据。
2、cephfs 文件系统 = 元数据 + 数据:
元数据(metadata):即目录和文件。元数据记录数据的属性,文件的存储位置、文件的大小和存储时间等,负责资源查找、文件记录、存储位置记录、访问授权等
数据(data):文件里的数据和内容。
Object:Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据。
一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。配置这些存储池时需考虑:
- 为元数据存储池设置较高的副本水平,因为此存储池丢失任何数据都会导致整个文件系统失效。
- 为元数据存储池分配低延时存储器(像 SSD ),因为它会直接影响到客户端的操作延时。
cephfs文件系统里的数据(文件内容)和元数据(目录,文件)最后都以对象(object)文件的形式保存在osd上。
3、pg、pool、osd三者的关系:
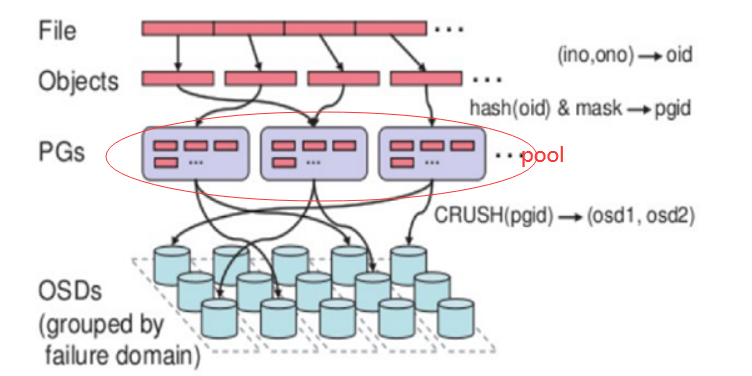
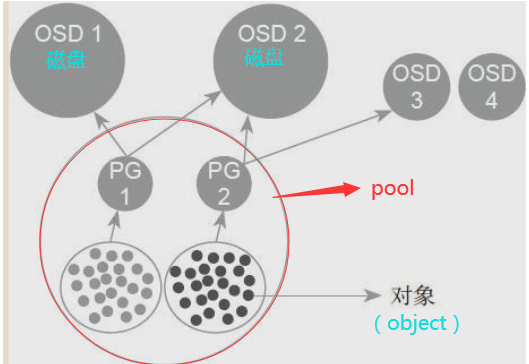
一个Pool里有很多PG, 一个PG里包含一堆对象;一个对象只能属于一个PG; PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型)
4、ceph的网络:
网络配置对构建高性能 Ceph 存储集群来说相当重要。 Ceph 存储集群不会代表 Ceph 客户端执行请求路由或调度,相反, Ceph 客户端(如块设备、 CephFS 、 REST 网关)直接向 OSD 请求,然后OSD为客户端执行数据复制,也就是说复制和其它因素会额外增加集群网的负载。
建议用两个网络运营 Ceph 存储集群:一个公共网(前端)和一个集群网(后端)。为此,各节点得配备多个网卡。
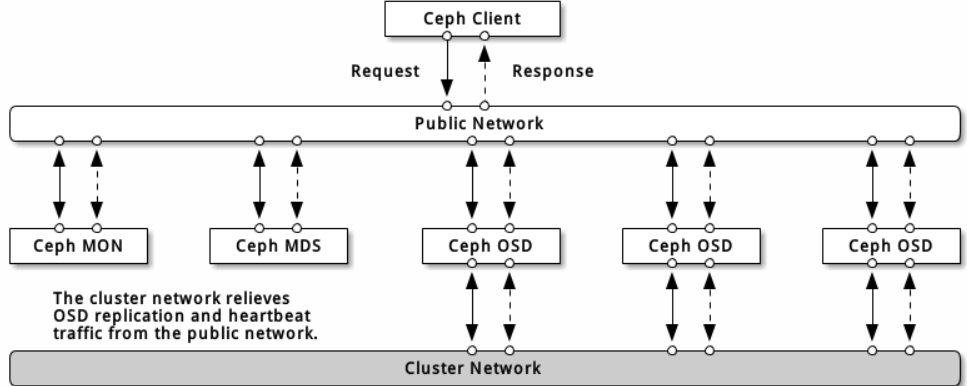
运营两个独立网络的考量主要有:
- 性能: OSD 为客户端处理数据复制,复制多份时 OSD 间的网络负载势必会影响到客户端和 Ceph 集群的通讯,包括延时增加、产生性能问题;恢复和重均衡也会显著增加公共网延时。
- 安全: 大多数人都是良民,很少的一撮人喜欢折腾拒绝服务攻击( DoS )。当 OSD 间的流量失控时,归置组再也不能达到 active + clean 状态,这样用户就不能读写数据了。挫败此类攻击的一种好方法是维护一个完全独立的集群网,使之不能直连互联网;另外,请考虑用消息签名防止欺骗攻击。
公共网络(public network):
[global]
...
public network = {public-network/netmask}
集群网络(cluster network):
如果你声明了集群网, OSD 将把心跳、对象复制和恢复流量路由到集群网,与单个网络相比这会提升性能。要配置集群网,把下列选项加进配置文件的 [global] 段。
[global]
...
cluster network = {cluster-network/netmask}
为安全起见,从公共网或互联网到集群网应该是不可达的。
公共网或集群网配置了多个 IP 地址及子网掩码,在各自的网络内子网必须能互通。
5、ceph-mgr(Ceph Manager Daemon)
ceph 官方开发了 ceph-mgr,该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,用于 收集ceph集群状态、运行指标,比如存储利用率、当前性能指标和系统负载。 对外提供 ceph dashboard(ceph ui)和 resetful api。Manager组件开启高可用时,至少2个实现高可用性。
ceph-mgr是由C/C++、python以及Cpython等共同编写完成的,mgr的实现使用了大量的Extending Python with C or C++的语法。 将ceph的部分C/C++实现的接口python化(即以前只能通过调用c/c++接口发送msg获取比如osdmap、monmap等集群状态,现通过mgr可以很方便地拿到。同时,ceph-mgr支持用户自定义的plugin(插件纯python开发,特别方便),用以实现特殊功能。
eph-mgr的官方plugins包括:
Dashboard(WEB界面的管理)、 Restful API(API方式获取ceph信息,应该与之前的ceph-rest-api功能一致)、 Zabbix、Prometheus、Influx(这三个实现了ceph的数据收集、监控等功能)
6、基础存储系统RADOS(Reliable Autonomic Object Store,可靠、自动、分布式对象存储):
RADOS是ceph存储集群的基础,这一层本身就是一个完整的对象存储系统。Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也都是由这一层所提供的,在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象,确保了数据一致性和可靠性。RADOS系统主要由两部分组成,分别是OSD和Monitor。
7、基础库LIBRADOS:
LIBRADOS基于RADOS之上,它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言,比如C、C++、Python等。
8、对象
RGW中的对象存储和Ceph 的后端存储的对象(object)区分:
第一个对象面向用户,是用户接口能访问到的对象;第二个对象是ceph 服务端操作的对象
eg:使用RGW接口,存放一个1G的文件,在用户接口看到的就是存放了一个对象(1);而后通过RGW 分片成多个对象(2)后最终存储到磁盘上;
二、ceph块设备(RBD)
三、cephfs文件系统
有待补充
https://www.pianshen.com/article/99391037623/ cephfs 的数据与元数据组织形式
http://docs.ceph.org.cn/cephfs/createfs/
http://docs.ceph.org.cn/man/8/ceph-deploy/ CEPH-DEPLOY – CEPH 部署工具
http://docs.ceph.org.cn/rados/operations/operating/
http://docs.ceph.org.cn/cephfs/createfs/ 创建 Ceph 文件系统并挂载