人工免疫相关优化算法
- 负向选择算法
生物学机理:定义任何属于人体自身的组织称为自体,任何入侵的东西称为异体。产生的抗体与自身细胞结合,则取消该抗体;留下的正式抗体,如果某异体与之产生结合并达到一定的阈值,则该异体检测为抗原,予以清除。
- 克隆选择算法
算法思想:淘汰与抗原结合能力差的抗体,对优质抗体变异,增加抗体的多样性。
算法流程:
1)产生出事候选集P:其由记忆细胞子集和保留子集组成。
2)选取n个亲和度最大的子集作为抗体样本Pn。
3 ) 对Pn进行克隆操作,其中亲和越大,克隆的个数越多。生成临时抗体集C.
4 ) 对C进行变异操作,其中亲和度越大,变异率越小。生成抗体集C*.
5 ) 重新选择C*中亲和度最大的子集,补充到记忆细胞自己中;并用C*中其他改进型个体替换P中的一些个体。
6)随机产生d个新抗体,替换P中亲和度最低的抗体,增加抗体的多样性。
特点:
多样性:通过新旧抗体的替代,增加了种群的多样性。
最优化:高亲和度抗体被保留,使得对抗原的识别更加有效。
局部搜索能力:突变的存在使得抗体可以在局部范围内发生变化提高了识别能力。
淘汰性:低亲和度抗体被淘汰,使得对免疫系统识别能力不断增强。
学习记忆性:第一阶段结束后,原高亲和度抗体被保留,使得在第二阶段可以快速响应识别抗原。
- 粒子群算法
算法思想:通过群体间个体的相互协作和信息共享来寻找最优解。
基本步骤:
1) 初始化粒子群,包括粒子的数量,位置和速度。
2) 计算每个粒子的适应度,选择该粒子最好的位置和适应度。选择该种群最好适应度粒子的位置作为该种群最好的位置。
3) 根据粒子的速度和位置更新粒子的速度和位置。
4) 计算更新后粒子的适应度,如果这个适应度更好,则更改该粒子的位置为此时的新位置。
5) 将每个粒子的适应度与全局所有所有粒子的适应度进行比较,如果较好则更新种群最好位置。
6) 判断此时是否满足算法结束条件,如果否则继续迭代之前步骤。
- 免疫粒子群算法在神经网络上的应用
说明:免疫粒子群是指上面算法的结合体。
算法思想:通过克隆的方法实现个体的高亲和度和群体的多样性。通过粒子群算法提高算法的收敛速度。提高优化的性能和质量。
基本步骤:
步骤1:确定目标函数, 。
。
其中:yi表示建模数据实际输出。F(xi)表示模型预测输出。
步骤2:利用目标函数,通过设置不同的神经网路参数,包括隐含层节点数,权值等。从而产生不同的f(xi),得到多个Ji,此处Ji表示为抗体。另:这些初始情况下的抗体就是粒子群中的粒子。
粒子属性更新:
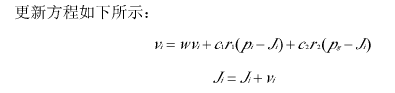 。
。
其中:w为惯性权值,它使粒子保持运动惯性。使其具有拓展搜索空间的趋势,加快收敛进程。Vi为粒子速度,vi属于[-Vmax,Vmax],较大的保证群体的全局搜索能力,较小则群体的局部搜索能力加强;c1,c2为正实数,称为加速度常数。r1,r2为[0,1]之间随意变化的随机数。Pi为目前粒子所处的最好位置,pg为粒子群目前的最好位置。
步骤3:更新后的粒子群,收敛速度快,但是易陷入局部最优。通过识别亲和力对粒子群进行增殖和淘汰。这里亲和力是指抗体与抗原的匹配程度。亲和力计算公式:
,其中t大于0,为常数。
步骤4:高变异克隆:对个体进行变异,复制高亲和力的抗体个体,同时淘汰亲和力低的个体,实现抗体库中的个体高度亲和力和群体多样性,防止局部收敛。再从新的抗体群中优选出亲和力高的个体,产生针对多目标优化的候选解。
变异公式:。
其中:其中δθξαβ为算法因子常数αδ用以控制变异程度β为正常数ξ为足够小的正数用以防止除数为;可以取适当的数;r为服从均值为、方差为的高斯分布的随机数;
步骤5:进行全局搜索,选出亲和力最高的抗体为最优个体。
步骤6:判断算法是否结束。