1、模块循环导入问题:
模块循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码
在我们的项目中应该尽量避免出现循环/嵌套导入,如果出现多个模块都需要共享的数据,可以将共享的数据集中存放到某一个地方
在程序出现了循环/嵌套导入后的异常分析、解决方法如下:
#错误示范文件内容如下
#m1.py
print('正在导入m1')
from m2 import y
x='m1'
#m2.py
print('正在导入m2')
from m1 import x
y='m2'
#run.py
import m1
方法一:导入语句放到最后
#m1.py
print('正在导入m1')
x='m1'
from m2 import y
#m2.py
print('正在导入m2')
y='m2'
from m1 import x
方法二:导入语句放到函数中
#m1.py
print('正在导入m1')
def f1():
from m2 import y
print(x,y)
x = 'm1'
#m2.py
print('正在导入m2')
def f2():
from m1 import x
print(x,y)
y = 'm2'
#run.py
import m1
m1.f1()
方法一中的名称空间关系图:
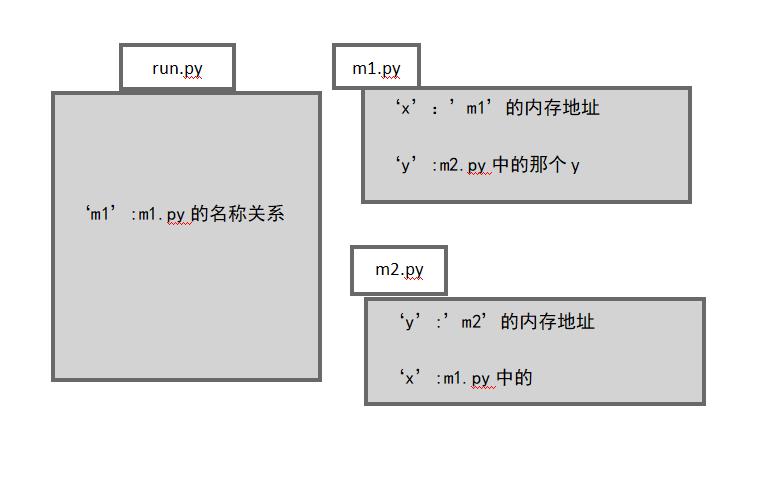
方法二中的名称空间关系图:

2、模块的搜索路径
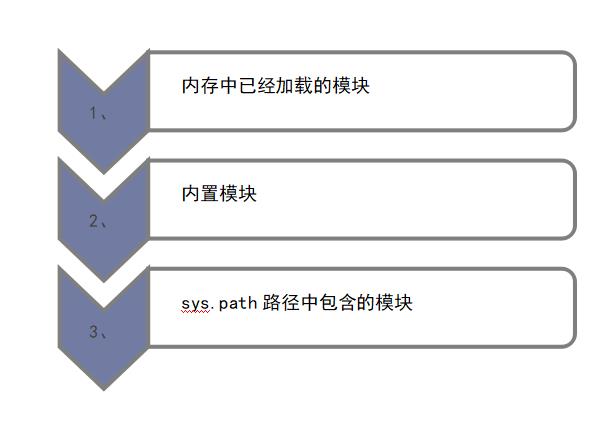
2.1、模块的查找顺序是:
2.2、导入模块的路径:
绝对导入: 以执行文件的sys.path为起始点开始导入,称之为绝对导入
优点: 执行文件与被导入的模块中都可以使用
缺点: 所有导入都是以sys.path为起始点,导入麻烦
相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入
符号: .代表当前所在文件的文件加;
..代表上一级文件夹;
...代上一级的上一级文件夹
优点: 导入更加简单
缺点: 只能在导入包中的模块时才能使用,不能在执行文件中用
3、区分python文件的两种用途:
- 编写好的一个python文件可以有两种用途:
u 一:脚本,一个文件就是整个程序,用来被执行
u 二:模块,文件中存放着一堆功能,用来被导入使用
- python为我们内置了全局变量__name__,
u 当文件被当做脚本执行时:__name__ 等于'__main__'
u 当文件被当做模块导入时:__name__等于模块名
- 作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
u if __name__ == '__main__'
4、软件开发目录
- confàsettings.py
- core(主要逻辑)àsrc.py
- dbàdb.txt
- lib(库)àcommon.py
- bin(入口,启动)àstart.py
- logàaccess.log
- readme(说明书)