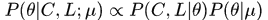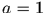gibbs采样
参数估计与预测
机器学习的一般思路为:
1.从问题的本质中构建模型,定义样本的产生,有联合概率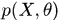 (图模型)。
(图模型)。
2.进行模型参数的估计:MLE、MAP、Bayes。
3.使用模型对新样本进行估计。
MLE:极大似然估计
估计:解优化函数
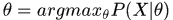
预测:
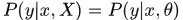
MAP:极大后验估计
估计:解优化函数
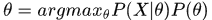
预测:
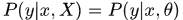
对比极大似然估计,引入了关于
 的先验知识。
的先验知识。
Bayes估计
估计:后验概率

预测:
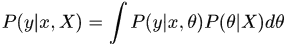
对于MLE和MAP算法,对模型参数进行点估计,没有考虑未知样本导致的模型参数的不确定性;对于Bayes估计,参数的后验概率有时很难求解,特别是在多参数联合分布的情况下,因此引入了近似求解的方法,引入gibbs采样,直接采样得到
gibbs采样的Naive Bayes模型
输入信息
1.有一组文本集合,利用BagOfWords模型,可以将每个文本表示成单词数量向量(经典的Naive Bayes模型将向量只有0,1两种状态)。
2.每个文本可以有标签,也可以没有标签。
3.模型的本质含义是将词向量分布相近的文档归为一类。
构建图模型

上述图模型描述了整个文档集合的构建过程。
对于每一个文档
1.首先选定类别标签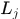 ,这个抽样过程服从参数为
,这个抽样过程服从参数为 的0-1分布。
的0-1分布。
2.接着根据类别标签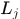 生成文档的词向量
生成文档的词向量 ,其中
,其中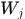 服从参数为
服从参数为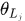 的多项式分布。
的多项式分布。
如果以MLE的观点,将参数 、
、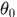 、
、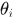 作为固定值,似然概率为
作为固定值,似然概率为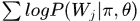 ,当然,这里存在隐变量
,当然,这里存在隐变量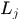 ,需要用EM算法进行求解。
,需要用EM算法进行求解。
但是,以Bayes的观点,不能对模型参数进行点估计,而是认为参数也是一个随机变量,因此引入超参数来描述参数的分布。
具体的,0-1分布的随机参数 服从参数为
服从参数为 的Beta分布。多项分布的参数
的Beta分布。多项分布的参数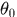 和
和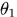 服从参数为
服从参数为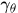 的Dirichlet分布。
的Dirichlet分布。
Beta分布
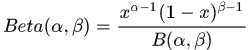
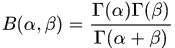
Dirichlet分布
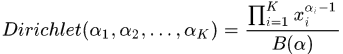
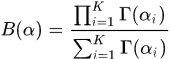
可以看出,Dirichlet分布是Beta分布的多维拓展。
由于我们通过引入图模型,只是知道了文档的生成方式,但对于
 的分布以及
的分布以及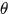 的分布并不了解,因此引入无信息的先验,也即
的分布并不了解,因此引入无信息的先验,也即 ,同理
,同理 各个元素都是1
各个元素都是1
写出联合概率

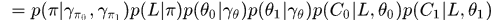
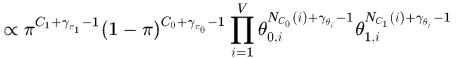
继续化解,将
 积分掉,有:
积分掉,有: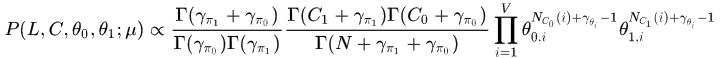
其中
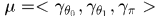
构建gibbs采样
构建gibbs采样的函数,主要是计算各个随机变量的单独的条件分布。
首先对文档的标签采样:

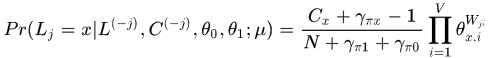
抽样过程:
1.令
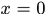 ,计算value0
,计算value02.令
 ,计算value1
,计算value13.对分布律
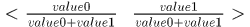 进行抽样,得到
进行抽样,得到
接着对参数
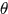 进行采样
进行采样