推送工具:webservice
假设接口数:30个
需要做到数据实时推送设置时间为每1分钟轮训一次是否有更新数据,如果有,每个接口开启一个线程,线程保持连接的时间是1.5钟,
(白天)
对于频繁更新的数据,长连接
次之的线程,30分钟的存活时间
少的,只有在访问的时候开启,持续的时间是2次轮训
(夜晚)
次之的线程,30分钟的存活时间
次之的线程,30分钟的存活时间
少的,只有在访问的时候开启,持续的时间是2次轮训
技术实现:
每一类的不同连接时长的线程都使用一个group,每个连接都有自己的线程名称,工具所属的group限制她的存活时间,如果线程在工作,存活时间重新计数
数据更新到临时表,是在数据的更新修改删除时,使用aop的方法,同时将数据插入到临时表
为什么要使用临时表,隔离原本的业务数据,防止对业务数据的误操作
如何做到数据的一致性 :
在临时表中,还增加了每一个
使用READ COMMITTED事务,webservice服务和业务的服务在一个系统,保证可以做到在同一个事务内进行推送(为什么要做临时表:若果返回无法传输的数据,将该数据删掉,防止重复提交,同时间该数据保存在日志表)
为了将webservice和业务系统分离开,需要使用到分布式事务,一下是分布式事务的解决方案
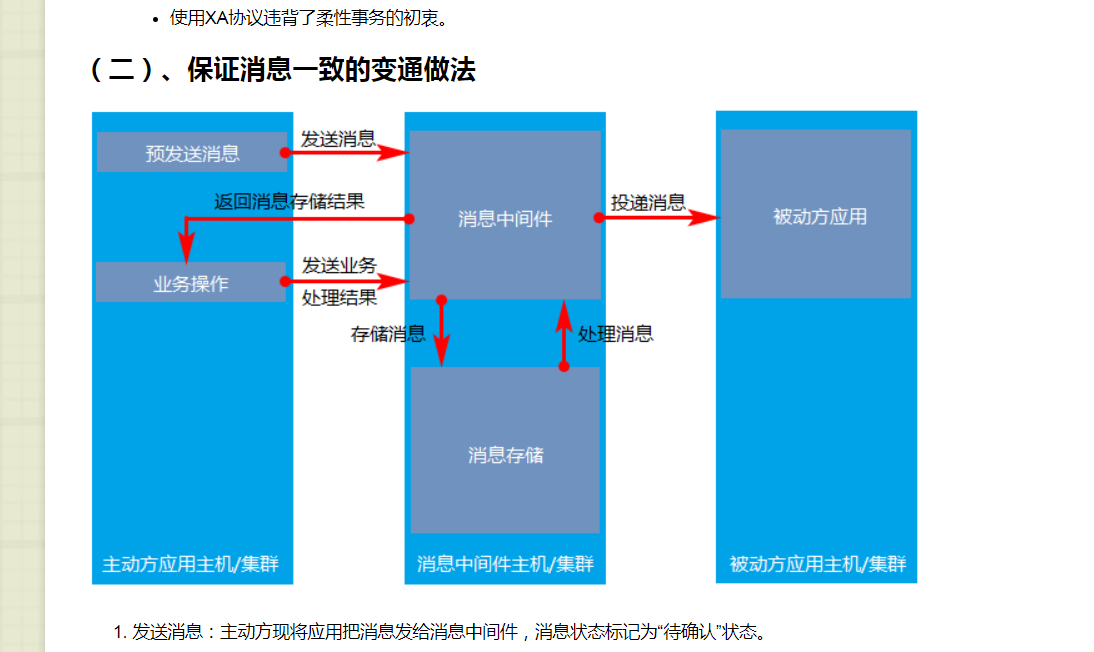
问:如何保证中间件宕机后,数据的恢复:中间件的库有一个时间戳的表,恢复的时间,会根据数据的创建时间去抽取数据
https://www.cnblogs.com/bluemiaomiao/p/11216380.html
业务:抽取的数据是通过不同的数据源,不同的表,进行一个数据的统计,
要做的工作:1、确保数据的抽取的完整性 2、要对数据进行清洗3、对数据进行统计,并记录结果
对数据的校验,可以使用并发编程,使用并发包countdowmlatch,进行不同表的检查
包括:recordCOunt,column schema,size,checksum的检查医院加服务站点有两百多个,一个点有20张表200*20=4000个表需要取数据,校验要8000次