A数据库可以优化层面
1数据库结构的优化(硬件升级,读写分离,分表技术,,添加缓存数据库)
2表结构的优化(3范式设计,反三范式的设计,使用合适的存储引擎)
3语句的优化(使用存储过程和触发器,合理使用索引)
B优化的思路:
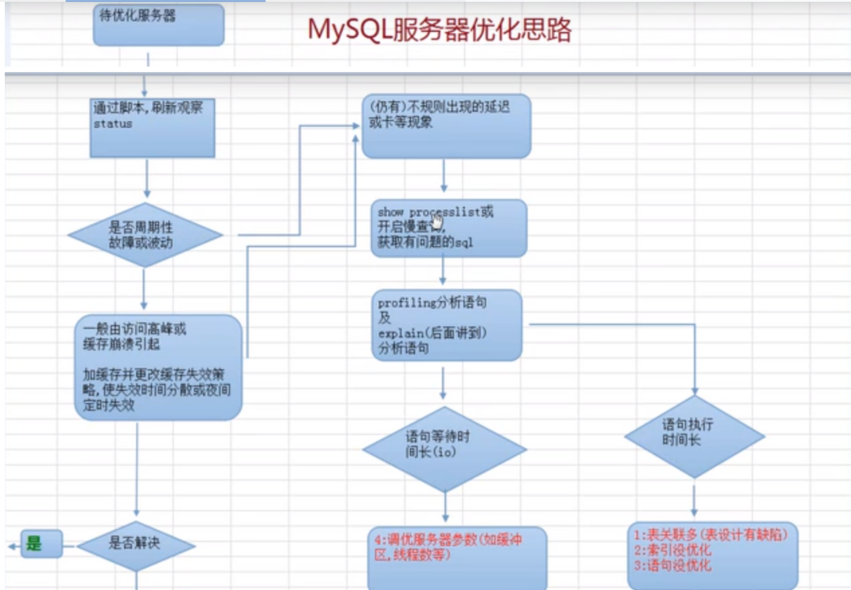

如果是周期性波动,则需要调整缓存的缓存清除策略,防止内存穿透,击穿和雪崩
如果不是周期性的问题,则需要通过processlist去分析是语句等待的时间问题还是语句的执行问题
语句的等待时间问题,则需调整数据库服务器的缓冲区和线程数
如果是语句问题,可以使用show profile for query,和explain去分析语句的具体执行细节。
数据库结构的优化:
。。。。。。。。。。。。。。。
2表结构的优化
表的设计,首先需要按照三范式去设计
- 确保每列的原子性(约束表的所有字段)(规范话所有字段,都不可再分如(中国广东,必须要分开))
- 非键字段必须依赖于键字段(一个表只描述一件事(如老师表,不存放学生表的信息))(主键时表的关键字段,非主键是具体描述这个表的信息)
- 消除传递依赖(非主键字段中,如果一个字段可以推导出另外一个字段,这叫传递依赖)
在次基础上,为了提高查询效率,可以适当增加表冗余,以减低表查询时,在关联表的时候,耗费的时间(具体需要结合业务场景)
存储引擎的选择:
innodb
mymisan
Myisam不支持事务,查询效率高,碎片化多
(使用了)
1字段类型的选择优先级:
整型>date,time>enum,char,varchar>blob
2.字段的空间够用即可,不要设置过大
3.尽量不用null,用其他值代替,因为null不利于索引,要用特殊字符标识,占更大的空间
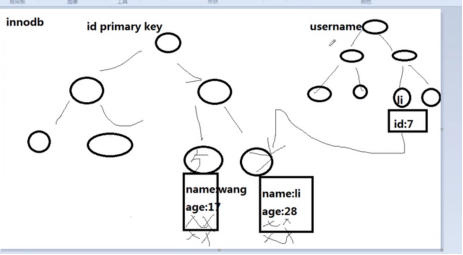
Myisam的次索引和主索引 都指向物理行(根据数的节点信息,使用指针到物理地址找出信息)

Innodb.支持视物,数据的修改优
innodb的次索引指向对主键的引用(主索引的叶子节点已存在具体的行信息)
3语句的优化
存储过程和触发器。是已经在数据库服务器编译好的语句,直接执行返回结果即可,节省了传输语句和编译语句耗费的时间
建立索引。
主键索引与唯一索引的区别
主键:只能有一个,不能重复,不能为空
唯一:可以有多个,不能重复,可以为空
独立索引只能使用一个,为了提高效率,可以使用联合索引

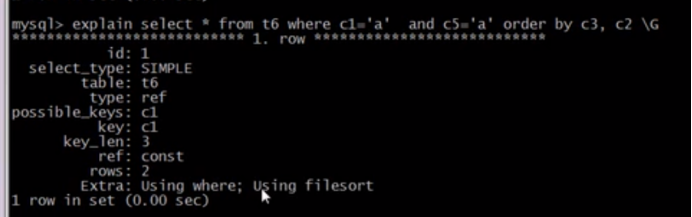
因为排了c3再排c2,c2需要sql服务器去重新排序,所以extra出现;了filesort
extra的参数含义:

建索引需要注意的内容:
理想的索引:
1.查询频繁
2.区分度高(可以通过这条语句去去确定)

索引只截取的字段的前几个字符

看扫描的行数可以判断查询效率
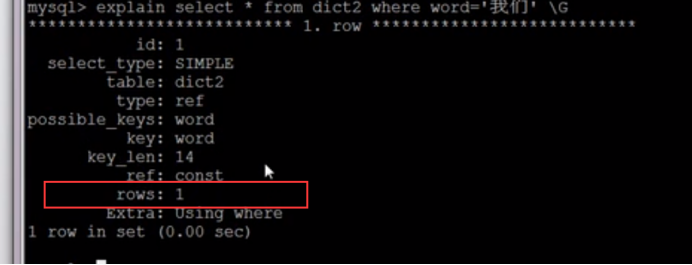
值越接近1,区分度越高,一般到达0.9已经是可接收的程度了
用crc函数,将字符转为hash列,降低索引长度,提高查询效率

延迟关联:

先使用id查询,实现索引覆盖,再使用关联擦查询,查询limit后的内容
延迟查询是先再节点中找到位置,再到物理地址获取


Explian的字段解释select——type(simple不含子查询)
Table 表名

Type列:




Ref,索引迅速定位到某一个范围


In子查询,先查主表再查次表,
Exit和关联查询的主次表查询顺序
要用分析器explian去分析 (尽量让少的表去全盘扫面,不要生产临时表)
数据库的优化,需要从服务器,表的设计,索引去优化,到语句的优化层,可优化的空间已经很小了
3.长度小
4.尽量能覆盖常用的查询字段
如果是innodb,
- 有多个比较长的列
- 是聚族索引,导致沿id排序时,要跨好多小文件
- 有比较长的列,导入块比较多
-
如果使用复合索引的时候,只会去主键索引中查找,不存在主键索引的跨快问题(符合索引类似于指针)