数据类型
整形
小数类型
浮点型
Float
Double
定点数
Decimal
时间日期类型
数据库连接
数据库使用
数据库操作
字符集
校对集
创建数据库
设置数据库权限
查看数据库
更新数据库
设置数据库编码
切换数据库
删除数据库
表操作
约束:
自增auto_increment
外键约束(一对多,多对多)
创建表
查看表
删除表
修改表
清空表 ★truncate
数据操作(行操作)
插入记录(行)
修改记录
删除记录
查询操作
单表查询
多表查询
内连接查询
外连接查询
子查询
分页查询
where 条件
排序查询order by
聚合(纵向查询)(mysql方法)
分组查询 group by
MySQL基础
(1)Mysql数据库是一种c/s结构的软件:客户端/服务器,若想访问服务器必须通过客户端(一般数据库会创建服务,并开机自启,使用时直接连接服务即可)
(2)交互方式
- 客户端连接认证:连接服务器,认证身份:mysql.exe -hPup
- 发送SQL指令
- 服务器接收SQL指令,处理SQL指令,返回操作结果。
- 客户端接收结果:显示结果
- 断开连接(释放资源:服务器并发限制)
(3)将mysql服务器内部对象分成四层:系统(DBMS)->数据库(DB)->数据表(Table)->字段(field)
数据类型
默认数据是有符号的(有负数),若想为无符号数(纯正数),在类型后加unsigned

| 分类 | 类型名称 | 说明 |
|---|---|---|
| 整数类型 | tinyInt |
很小的整数,系统采用一个字节来保存的整形:一个字节 = 8位,最大能表示的数值是0-255:2^8-1,实际为(-128,127) |
smallint |
小的整数,系统采用两个字节来保存的整形:能表示0-65535之间,2^16-1 | |
mediumint |
中等大小的整数,采用三个字节来保存数据:2^24-1 | |
int(integer) |
普通大小的整数,采用四个字节来保存数据 | |
Bigint |
采用八个字节来保存数据 | |
| 小数类型 | float |
单精度浮点数 |
double |
双精度浮点数 | |
decimal(m,d) |
压缩严格的定点数(m是总位数,d是小数点后位数) | |
| 日期类型 | year |
YYYY 1个字节 1901~2155,year有两种数据插入方式:0~99和四位数的具体年 |
time |
HH:MM:SS 3个字节 -838:59:59~838:59:59 |
|
date |
YYYY-MM-DD 3个字节,能表示的范围是从1000-01-01 到9999-12-31,初始值为0000-00-00 |
|
datetime |
YYYY-MM-DD HH:MM:SS 8个字节,1000-01-01 00:00:00~ 9999-12-31 23:59:59 |
|
timestamp |
YYYY-MM-DD HH:MM:SS 8个字节, 1970~01~01 00:00:01 UTC~2038-01-19 03:14:07UTC,表示从格林威治时间开始 |
|
| 文本、二进制类型 | CHAR(M) |
M为0~255之间的整数(字符长度不可变) |
VARCHAR(M) |
M为0~65535之间的整数(字符长度可变) | |
TINYBLOB |
允许长度0~255字节 | |
BLOB |
允许长度0~65535字节 | |
MEDIUMBLOB |
允许长度0~167772150字节 | |
LONGBLOB |
允许长度0~4294967295字节 | |
TINYTEXT |
允许长度0~255字节 | |
TEXT |
允许长度0~65535字节(存储超大型文本) | |
MEDIUMTEXT |
允许长度0~167772150字节 | |
LONGTEXT |
允许长度0~4294967295字节 | |
VARBINARY(M) |
允许长度0~M个字节的变长字节字符串 | |
BINARY(M) |
允许长度0~M个字节的定长字节字符串 |
整形
创建表格之后,类型会自动设置一个<数据>--显示宽度;
显示宽度不会影响类型允许的数据的范围,
例如int(2):表示int少于2位,可以填充0,但是int允许的范围依然是4个字节;
显示宽度意义:显示长度只是代表了数据是否可以达到指定的长度,但是不会自动满足到指定长度:如果想要数据显示的时候,保持最高位(显示长度),那么还需要给字段增加一个zerofill属性才可以。
Zerofill:从左侧开始填充0(左侧不会改变数值大小),所以负数的时候就不能使用zerofill,一旦使用zerofill就相当于确定该字段为unsigned
-- 显示宽度为2,0填充alter table my_int add int_7 tinyint(2) zerofill;

数据显示的时候,zerofill会在左侧填充0到指定位:如果不足2位,那么填充到2位,如果本身已经够了或者超出,那么就不在填充。

注意:Navicat显示的时候左侧的0无法显示;
小数类型
在Mysql中将小数类型又分为两类:浮点型和定点型
浮点型:小数点浮动,精度有限,而且会丢失精度
定点型:小数点固定,精度固定,不会丢失精度
浮点型
浮点型又称之为精度类型:是一种有可能丢失精度的数据类型,数据有可能不那么准确(由其是在超出范围的时候)
浮点型之所以能够存储较大的数值(不精确),原因就是利用存储数据的位来存储指数
精度:
- Float:单精度,占用4个字节存储数据,精度范围大概为7位左右
- Double:双精度,占用8个字节存储数据,精度范围大概为15位左右
Float
Float又称之为单精度类型:系统提供4个字节用来存储数据,但是能表示的数据范围比整型大的多,大概是10^38;只能保证大概7个左右的精度(如果数据在7位数以内,那么基本是准确的,但是如果超过7位数,那么就是不准确的)
基本语法:
Float:表示不指定小数位的浮点数(理论上小数位随便几位)
Float(M,D):表示一共存储M个有效数字,其中小数部分占D位
Float(10,2):整数部分为8位,小数部分为2位
整数部分长度不能超出限定条件,但是小数部分可以无限长,超出部分会四舍五入
注意:如果数据精度丢失,那么浮点型是按照四舍五入的方式进行计算
存入:13246578.90,保存会丢失经度:12345679.00 --精度丢失,四舍五入存入123456789.00,长度超长,提出异常存入99999999.99,超过7位,精度丢失,四舍五入,会变为100000000.00 -- 系统自动进位,可以超长
- 浮点数可以采用科学计数法来存储数据
存入 10e5,会保存为100000.00
- 浮点数的应用:通常是用来保存一些数量特别大,大到可以不用那么精确的数据。
Double
Double又称之为双精度:系统用8个字节来存储数据,表示的范围更大,10^308次方,但是精度也只有15位左右。
定点数
定点数:能够保证数据精确,整数部分一定精确(不会四舍五入),小数(小数部分可能不精确,超出长度会四舍五入);
Decimal
Decimal定点数:系统自动根据存储的数据来分配存储空间,每大概9个数就会分配四个字节来进行存储,同时小数和整数部分是分开的。
Decimal(M,D):M表示总长度,最大值不能超过65,D代表小数部分长度,最长不能超过30。
-- 创建表money decimal(10,2)
- 插入数据
-- 插入超过7位的数据不会失精12345678.9---12345678.9-- 插入最大数不会失精99999999.99---99999999.99-- 进位导致超出长度会爆错99999999.999---报错
- 定点数的应用:如果涉及到钱的时候有可能使用定点数
时间日期类型

插入数据:
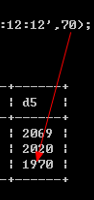
- year进行两位数插入的时候,有一个区间划分,零界点为69和70:当输入69以下,那么系统时间为20+数字,如果是70以上,那配系统时间为19+数字
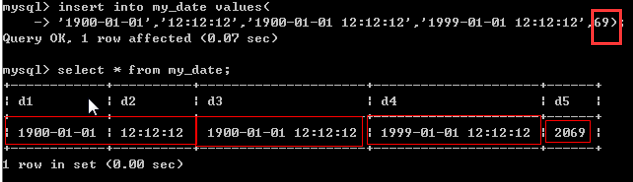
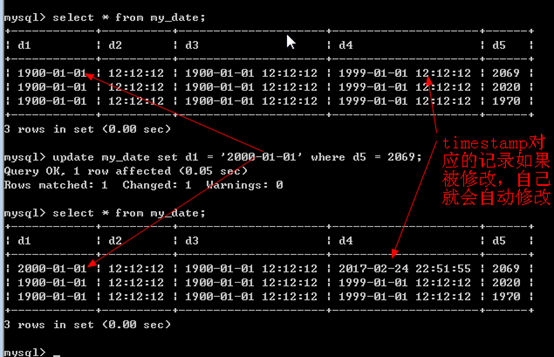
- timestamp当对应的数据被修改的时候,会自动更新(这个被修改的数据不是自己)
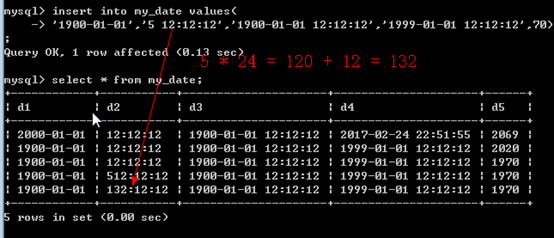
- time类型特殊性:本质是用来表示时间区间(当前时间之后的多少个小时),能表示的范围比较大

- 在进行时间类型录入的时候(time)还可以使用一个简单的日期代替时间,在时间格式之前加一个空格,然后指定一个数字(可以是负数):系统会自动将该数字转换成天数 * 24小时,再加上后面的时间。
数据库连接
数据库使用
数据库操作
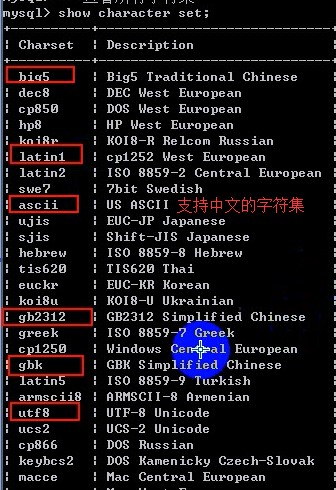
字符集
- 查看所有字符集
show character set;
- 服务器默认的对外处理的字符集
show variables like 'character_set%'
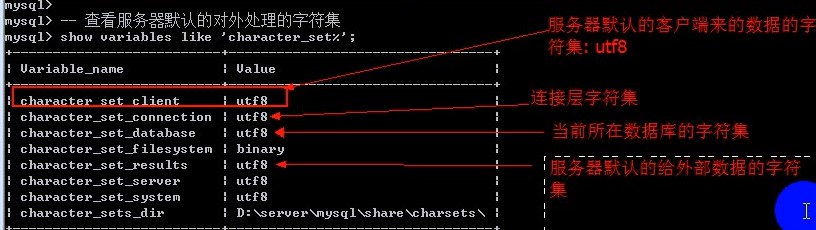
- 改服务器认为的客户端数据的字符集为GBK
set character_set_client =gbk;
- 快捷设置字符集
set names gbk;
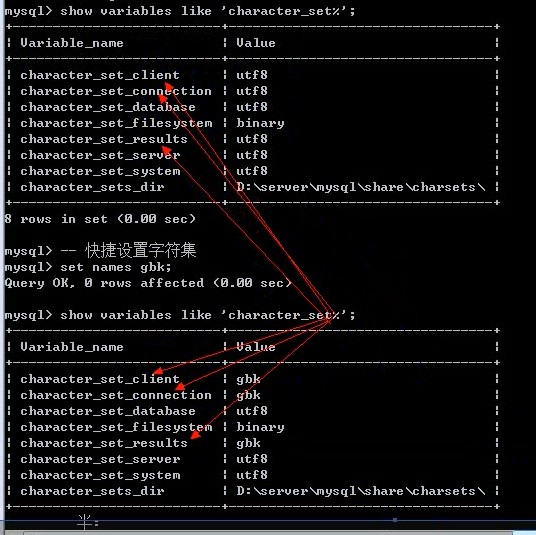
校对集
校对集:数据比较的方式
校对集有三种格式:
_bin:binary,二进制比较,取出二进制位,一位一位的比较,区分大小写_cs:case sensitive,大小写敏感,区分大小写_ci:case insensitice,大小写不敏感,不区分大小写
校对集应用:只有当数据产生比较的时候,校对集才会生效.
校对集必须在没有数据之前声明好,如果有了数据,那么再进行校对集修改:那么修改无效.
- 查看所有校对集(197种)
show collation;
创建数据库
- 其中:数据库名字不能用关罐字(已经被使用的字符)或者保留字(将来可能会用到的)
- 如果非要使用关键字或者保留字,那么必须使用反引号(sc键下面的罐在类文状态下的输出`;
- 中文数据库是可以的但是有前提条件:保证服务器能够识别(建议不用)(需设定定当前cmd的字符集)
- 当创建数据库的SQL语句执行之后,发生了什么?
1.在数据库系统中,增加了对应的数据库信息
2.会在保存数据的文件夹下:Da加目录,创建一个对应数据库名字的文件夹
create database 数据库名 [库选项];库选项:1.字符集设定:charset/character set 具体字符集--一般使用CBK和UTF82.校对集设定:collate 具体校对集(数据比较的规则)
例如:
//数据库名是英文名:Create database mydatabase charset utf8;// 数据库名是中文名:(不推荐)Set names gbk;Create database 中国 charset utf8;
设置数据库权限
GRANT 权限 ON 数据库.* TO 用户@localhost(IP,也可写127.0.0.1) IDENTIFIED BY 密码;权限可设置部分:所有权限: ALL PRIVILEGES部分权限:(select,insert,update,delete,create,drop)
查看数据库
- 查看所有数据库
show databases;
- 查看指定部分数据库:模糊查询
%:表示匹配多个字符_: 表示单个字符
show databases like 'pattern' -- pattern是匹配模式
例如:查看以"aa_"开头的所有数据库
show databases like 'aa\_%';//其中的_需要转义,否则相当于 aa%
- 查看数据库的创建语句
show create database 数据库名
- 查看正在使用的数据库
select database();
更新数据库
(1)数据库名字不可以修改
(2)数据库修改仅限库选项:字符集和校对集(校对集依赖字符集)
Alter database 数据库名字 [库选项];库选项:Charset/characterset [=]字符集Collate 校对集

设置数据库编码
1.查看所有mysql的编码
show variables like 'character%';
2.将客户端编码修改为gbk
set character_set_results=gbk; / set names gbk;
此操作只针对当前窗口有效果,如果关闭了服务器便失效
切换数据库
use 数据库名;
删除数据库
在对应的数据库存储的文件夹内:数据库名字对应的文件夹也被删除(级联删除:里面的数据表全部被删除)
删除不可逆,最好先备份
Drop database 数据库名字
表操作
约束:
单表约束:
- 主键约束:primary key
注意:一张表只能有一个主键,这个主键可以包含多个字段- 方式1:建表的同时添加约束 格式:
字段名称 字段类型 primary key - 方式2:建表的同时在约束区域添加约束(所有的字段声明完成之后,就是约束区域了)
- 方式1:建表的同时添加约束 格式:
create table pk01(id int,username varchar(20),primary key (id) //约束区域);insert into pk01 values(1,'tom');-- 成功insert into pk01 values(1,'tom');-- 失败 ,不能重复insert into pk01 values(null,'tom');-- 失败 不能是null
- 方式3:建表之后,通过修改表结构添加约束
create table pk02(id int,username varchar(20));alter table pk02 add primary key(字段名1,字段名2..);多个字段,只有多个字段都相同,才算同一个alter table pk02 add primary key(id,username);insert into pk02 values(1,'tom');-- 成功insert into pk02 values(1,'tomcat');-- 成功insert into pk02 values(1,'tomcat');-- 失败
- 唯一约束:unique
被修饰过的字段唯一,对null不起作用(可以多个约束)
- 方式1:建表的同时添加约束 格式: 字段名称 字段类型 unique
//create table un(id int unique,username varchar(20) unique);insert into un value(10,'tom');-- 成功insert into un value(10,'tom');-- 错误 ,10重复insert into un value(null,'tom');-- 成功insert into un value(null,'rose');-- 成功
- 方式2:建表的同时在约束区域添加约束
所有的字段声明完成之后,就是约束区域了unique(字段1,字段值2...)
- 方式3:建表之后,通过修改表结构添加约束
alter table 表名 add unique(字段1,字段2);-- 添加的联合唯一alter table 表名 add unique(字段1);-- 给一个添加唯一alter table 表名 add unique(字段2);-- 给另一个添加唯一
例:create table un01(id int,username varchar(20));alter table un01 add unique(id,username);insert into un01 values(1,'tom');-- 成功insert into un01 values(1,'jack');-- 成功insert into un01 values(1,'tom');-- 失败 重复
- 非空约束:not null
特点:被修饰过的字段非空,not null
方式:create table nn(id int not null,username varchar(20) not null);insert into nn values(null,'tom');-- 错误的,不能为null
自增auto_increment
要求:
1.被修饰的字段类型支持自增. 一般int
2.被修饰的字段必须是一个key 一般是primary key(主键)
外键约束(一对多,多对多)
添加了外键约束之后有如下特点:
- 主表中不能删除从表中已引用的数据
- 从表中不能添加主表中不存在的数据
- 一对多关系
一对多建表原则:在多的一方创建一个字段,字段作为外键指向一的一方的主键.
为了保证数据的有效性和完整性,在多表的一方添加约束(外键约束). (不是必须的,也可以通过java程序来控制)
alter table 多表名称 add foreign key(外键名称) references 一表名称(主键);
- 多对多关系:
多对多关系建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键. - 一对一关系:
在实际的开发中应用不多.因为一对一可以创建成一张表.
两种建表原则: - 唯一外键对应:假设一对一是一个一对多的关系,在多的一方创建一个外键指向一的一方的主键,将外键设置为unique(唯一).
- 主键对应:让一对一的双方的主键进行建立关系.
创建表
create table [if not exists] 表名( -- 也可以数据库名.表名字段名 类型(长度) 约束,字段名 类型(长度) 约束)[表选项];//----例如:---create table user(id int primary key auto_increment,username varchar(20));
(1)If not exists:如果表名不存在,那么就创建,否则不执行创建代码(检查功能)
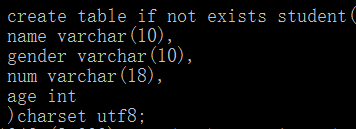
(2)表选项:控制表的表现
字符集:charset/character set具体字符集(保证表中数据储存的字符集)
校对集:collate具体校对集;
储存引擎: engine具体的存储引擎(innodb和myisam)
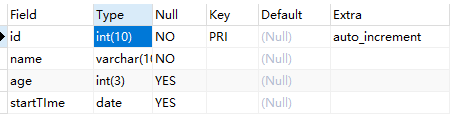
查看表
- 查看数据库中的所有表:
show tables;show tables like '';
- 查看表结构:
desc 表名;describe 表名;show columns from 表名;
- 查看建表语句:
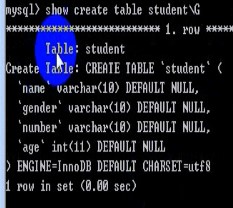
show create table 表名;show create table 表名g -- g ===;show create table 表名G -- G ===纵向查询(类似表格)

删除表
drop table 表名1,表名2...;
修改表
alter table 表名 ....
表本身可以修改:表名和表选项
- 修改表名:
alter table 旧表名 rename to 新表名;或:rename table 旧表名 to 新表名;例如:alter table user1 rename to user10;
- 修改表编码/字符集
alter table 表名 CHARACTER SET gbk;或者alter table 表名 charset = gbk;
- 添加字段:
alter table 表名 add [column] 字段名 数据类型 [列属性] [位置];
- 位置: 字段名可以存放表中的任意位置
- First:第一个位置
- After:在哪个字段之后:after 字段名;默认的是在最后一个字段之后
例如:alter table user add password varchar(20);--给学生表增加ID放到第一个位置alter table my_student add column id int first;
- 修改字段名:
alter table 表名 change 旧字段名 新字段名 数据类型 [约束/属性] [位置];例如:alter table user change password pwd varchar(20);
- 修改字段描述/数据类型:
alter table 表名 modify 字段名称 字段类型 [约束] [位置];例如:alter table user modify pwd int;--将学生表中的number学号字段变成固定长度,且放到第二位(id之后)alter table my student modify number char(10) after id;
删除字段(不可逆):
alter table 表名 drop 字段名;例如:alter table user drop pwd;
清空表 ★truncate
主键重新从1开始计算
干掉表,重新创建一张空表格式:truncate 表名;
和delete from 区别:
- delete属于DML语句 truncate属于DDL语句
- delete逐条删除 truncate干掉表,重新创建一张空表
- (delete主键继续,truncate主键从1开始)
- 如果在一个事务中,delete数据,这些数据可以找回.truncate删除的数据找不回来.
数据操作(行操作)
插入记录(行)
- 格式1: 插入全部字段(列)
注意:
- 默认插入全部字段(列),
- 必须保证values后面的内容的类型和
顺序和表结构中的一致- 若字段类型为数字,可以省略引号,引号可以是""也可以是''
- 对于
自动增长的列在操作时,直接插入null值即可。
-- 可以批量查询insert into 表名 values(字段值1,字段值2...,字段值n),(字段值1,字段值2...,字段值n);
- 格式2: 插入指定的字段
注意:
- 插入指定的字段
- 必须保证values后面的内容的类型和顺序和表名后面的字段的类型和顺序保持一致.
插入一条:insert into 表名(字段名,字段名1...) values(字段值,字段值1...);插入多条:insert into 表名(字段名,字段名1...) values(字段值,字段值1...),(字段值,字段值1...),(字段值,字段值1...);
修改记录
注意:
- 1.列名的类型与修改的值要一致.
- 2.修改值得时候不能超过最大长度.
- 3.值如果是字符串或者日期需要加''.
update 表名 set 字段名=值,字段名=值,字段名=值 [where 条件];例如:update user set username='jerry' where username='jack';
删除记录
delete from 表名 [where 条件];
查询操作
- 去重:
distinct
select distinct 字段 from 表名;
- 别名
as
as可以忽略
select 字段 as 字段别名 from 表名 as 表别名;
- 计算
select 计算 as 别名 from 表名;
计算可以直接使用数学计算,可以使用MySQL的方法
单表查询
select ... from 表名 where 条件 group by 分组字段 having 条件 order by 排序字段 ase|desc(降序)
多表查询
select a.*,b.* from a,b;
内连接查询
使用的关键字 inner join -- inner可以省略
只显示多张表中的满足条件(on)的行,on是查询条件
- 显式内连接:
select a.*,b.* from a [inner] join b on ab的连接条件;//用on设置连接条件例如: select user.*,orders.* from user join orders on user.id=orders.user_id;
- 隐式内连接:
select a.*,b.* from a,b where ab的连接条件或者select * from a,b where ab的连接条件//用where设置连接条件例如:select user.*,orders.* from user ,orders where user.id=orders.user_id;
- 交叉连接查询
基本不会使用-得到的是两个表的乘积
select * from A,B;
外连接查询
on是用来关联多张表的;
使用的关键字 outer join -- outer可以省略
- 左外连接:
left outer join
先展示join左边的(a)表的所有数据,根据条件关联查询 join右边的表(b),符合条件则展示出来,不符合以null值展示,具体的过滤是用where
select * from A left [outer] join B on 条件;
- 右外连接:
right outer join
select * from A right [outer] join B on 条件;
先展示jion右边的表(B)表的所有数据,根据条件关联查询join左边的表(A),符合条件则展示出来,不符合以null值展示.
子查询
在sql语言中,当一个查询是另一个查询的条件时,称之为子查询
select * from orders where user_id = (select id from User where username = '张三');select user.*,tmp.* from user,(select * from orders where price>300) as tmp where user.id=tmp.user_id;
分页查询
分页查询每个数据库的语句是不通用的.
select * from product limit a,b; --a:从哪开始,b:查询多少条.
where 条件
| 操作 | 意义 |
|---|---|
| id=6 | 等于(没有==) |
| id<>6 | 不等于 |
| id<=6 | 小于等于 |
| and | 与 (不能用&&字符表示) |
| or | 或(不能用¦¦字符表示) |
| not | 非(不能用!字符表示) |
| 列名(字段值) in (…)UPDATE product SET price = 2000 WHERE id in(1,2,4); | 字段值为…的全部改 |
| Not in | 不包含 |
- 运算符
| 分类 | 符号 | 定义 |
|---|---|---|
| 比较运算符 | > <<= >= =<> |
大于、小于、大于(小于)等于、不等于 |
| BETWEEN ... AND ... | 显示在某一区间的值(含头含尾)[ ] BETWEEN 2000 AND 5000; money >=2000 AND money <=5000; |
|
| IN(set) | 显示在in列表中的值,例:in(100,200) money IN(10,50,35);查询money中是10或50或35的 |
|
| 通配符 | LIKE 通配符 | 模糊查询,Like语句中有两个通配符%用来匹配多个字符;例first_name like ‘a%’;_用来匹配一个字符。例first_name like 'a_'; |
| null判断 | IS NULL | 判断是否为空 |
| is not null | 判断不为空 | |
| 逻辑运算符 | and | 多个条件同时成立 |
| or | 多个条件任一成立 | |
| not | 不成立,例:where not(salary>100); |
- 案例:
- 查询出账务名称中是五个字的账务信息
SELECT * FROM gjp_ledger WHERE ldesc LIKE "_____"; -- 五个下划线_
- 查询出账务名称不为null账务信息
SELECT * FROM zhangwu WHERE name IS NOT NULL;SELECT * FROM zhangwu WHERE NOT (name IS NULL);
- 查询出账务名称中是五个字的账务信息
排序查询order by
对结果集进行排序,在最后
- 降序:
order by 列名desc - 升序(默认,可以不写asc):
order by 列名asc
聚合(纵向查询)(mysql方法)
对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
| 方法 | 定义 |
|---|---|
| count(列名) | 统计指定列中不为null的记录的列数 SELECT COUNT(*) AS 'count' FROM zhangwu |
| sum(列名) | 对一列中数据进行求和计算(若列不是数值类型,返回0,null算是0) SELECT SUM(zmoney) FROM zhangwu |
| max(列名) | 获取某列数据最大值---字符的话,中文是乱序 SELECT MAX(zmoney) FROM zhangwu |
| min(列名) | 获取某列数据最小值 |
| avg(列名) | 计算一个列所有数据的平均数(是不为0部分的平均数) SELECT AVG(zmoney)FROM zhangwu |
分组查询 group by
在where之后,order by 之前
group by 被分组的列名:分组查询Having 条件:分组后再次查询,和where一个用法
SELECT 字段1,字段2 FROM 表名 WHERE 条件1 GROUP BY 字段 HAVING 条件2;(1)按照条件1过滤、搜索字段1和2,(2)按照字段进行分组(3)按照条件2再次进行过滤注意:字段若是有重复的,会只输出最小的那个
注意:排序一定在最后
having和where的区别:
- having是在分组后对数据进行过滤;
where是在分组前对数据进行过滤 - having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数