首先作者介绍了在视觉领域中Attention也发挥着很大的作用,Attention不止能使得运算聚焦于特定区域,同时也可以使得该部分区域的特征得到增强,同时’very deep’的网络结构结合残差连接(Residual Network)在图像分类等任务中表现出了极好的性能。基于这两点考量,作者提出了残差注意力网络(Residual Attention Network),这种网络具有以下两点属性:
- 增加更多的注意力模块可以线性提升网络的分类性能,基于不同深度的特征图可以提取额外的注意力模型。
- 残差注意力模型可以结合到目前的大部分深层网络中,做到end-to-end训练结果,因为残差结构的存在,可以很容易将网络扩展到百数层。并且使用该种策略可以在达到其他大网络的分类准确率的同时显著降低计算量(计算量基本上为ResNet大网络的69%左右)

上图中左图显示了在残差注意力网络中主干网络和注意力模块之间的关系,注意力模块为主干网络以某一个特征图为节点的分叉子网络;右图中的结果显示网络模型中,不同层特征图响应的注意力不同,在浅层结构中,网络的注意力集中于背景等区域,而在深层结构中,网络的注意力特征图(Attention Feature Map)聚焦于待分类的物体。这与之前的很多工作结论类似,那就是深层次的特征图具有更高的抽象性和语义表达能力,对于物体分类较浅层特征有较大的作用
本文的主要贡献点为:
- 设计了一种可堆叠的网络结构,并且可堆叠的基本模块中引入了注意力特征图的机制,不同层次的特征图能够捕捉图像中的多种响应结果。
- 注意力残差学习,直接堆叠注意力模块会导致网络层次过深出现梯度消失的现象,本文使用了残差连接的方式,使得不同层的注意力模块可以得到充分学习。
- Bottom-up与top-down结构相结合,自底向上主要是为了图像的特征提取,自顶向下是为了生成Attention Map
Residual Attention Network
最终论文提出的残差注意力网络主要由多层注意力模块堆叠而成,每个注意力模块包含了两个分支:掩膜分支(mask branch)和主干分支(trunk branch)。其中主干分支可以是当前的任何一种SOTA卷积神经网络模型,掩膜分支通过对特征图的处理输出维度一致的注意力特征图(Attention Feature Map)),然后使用点乘操作将两个分支的特征图组合在一起,得到最终的输出特征图。
假如主干分支输出特征图为Ti,c(x)Ti,c(x),掩膜分支的输出特征图为Mi,c(x)Mi,c(x),那么最终该注意力模块的输出特征图为:
Hi,c(x)=Ti,c(x)∗Mi,c(x)
Attention Residual Learning
作者在文中指出,虽然注意力模块对于目标分类有较大的作用,但是单纯叠加注意力模块会导致模型性能的下降,主要有两点:
掩膜分支为了输出权重归一的特征图,后面需要跟Sigmoid作为激活函数,但是问题在于Sigmoid将输入归一化到0到1之间,再来与主干分支进行点乘,会使得特征图的输出响应变弱,多层叠加该种结构会使得最终输出的特征图每一个点上的值变得很小;
同时,掩膜分支输出的特征图有可能会破坏主干分支的优点,比如说将残差连接中的shortcut机制替换为掩膜分支,那么将会使得深层网络的梯度不能很好的反传。
为了解决上述问题,作者使用了下列公式来替代注意力模块的输出:
Hi,c(x)=(1+Mi,c(x))∗Fi,c(x)
Mi,c(x)Mi,c(x)为[0, 1]区间内的取值,与1相加之后可以很好的解决一中提出来的会降低特征值的问题;到这个部分本文与残差网络的区别在于,残差网络的公式Hi,c(x)=x+Fi,c(x)Hi,c(x)=x+Fi,c(x),Fi,c(x)Fi,c(x)学习的是输出和输入之间的残差结果,而在本文中,Fi,c(x)Fi,c(x)是由一个深层的卷积神经网络结构来学习拟合。结合掩膜分支输出的结果,可以使得Fi,c(x)Fi,c(x)的输出特征图中重要的特征得到加强,而不重要的特征被抑制。最终,不断地叠加注意力模块可以使得逐渐的提升网络的表达能力。上图中显示越是深层,注意力模型的注意力机制会更加关注在对分类有帮助的目标上。
Soft Mask Branch
在掩膜分支(mask branch)中,特征图的处理操作主要包含为前向的降采样过程和上采样过程,前者是为了快速编码、获取特征图的全局特征,而后者主要是将提取出来的全局高维特征上采样之后与之前未降采样的特征组合在一起,目的使得上下文,高低纬度的特征能够更好的组合在一起,类似于FPN网络的做法。掩膜分支的操作如下图所示:
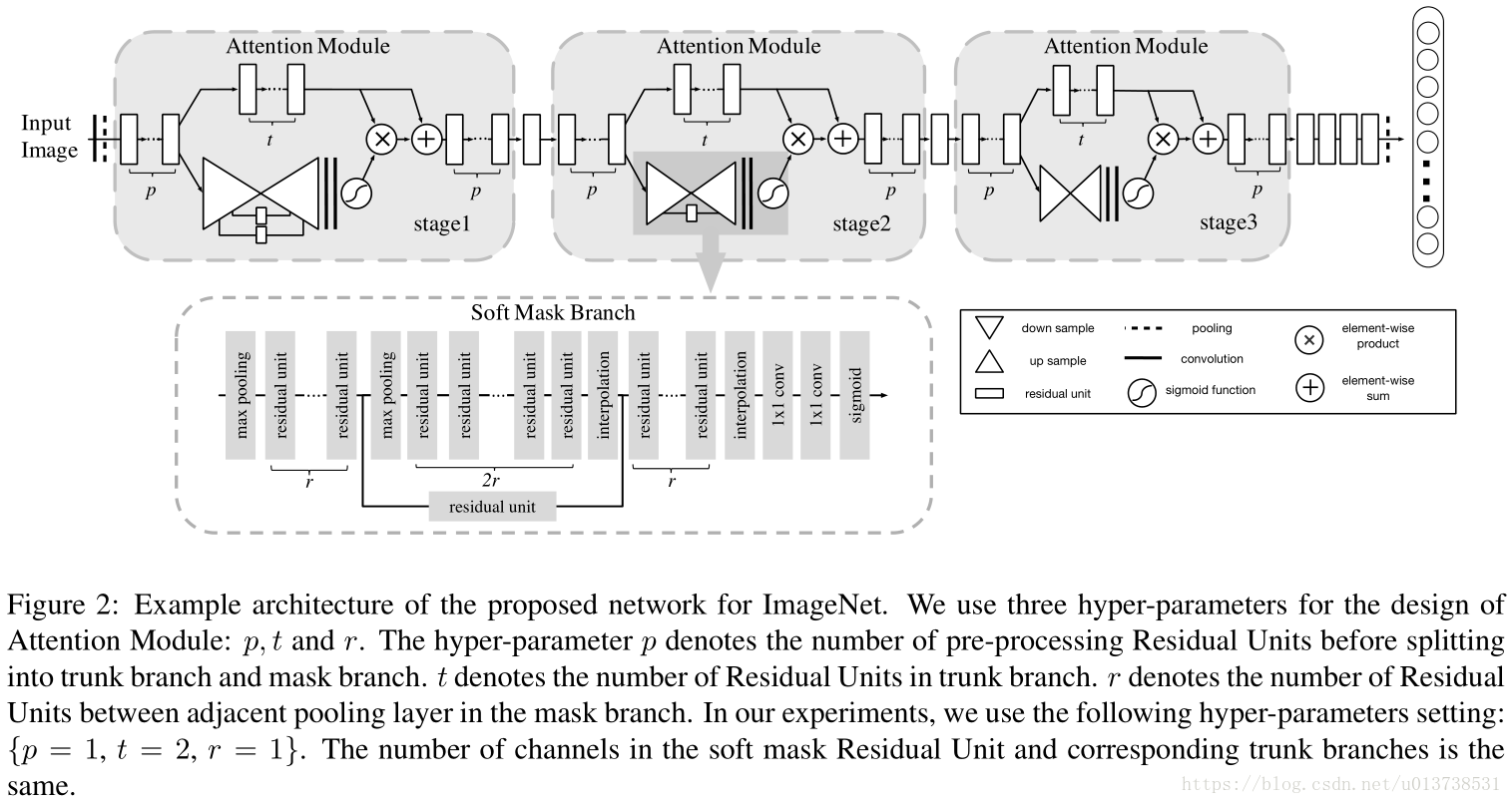
图中每一个Attention Module,也即是Soft Mask Branch对于固定的输入,多层卷积计算之后使用Max-Pooling操作对特征图进行降维操作,一直降维直到特征图宽高达到网络输出特征图的最小尺寸,比如7x7,然后逐层使用双线性差值的方法扩张特征图的宽高维度,并且与之前同样维度下的特征相加,这里的考量是结合了全局的和局部的特征,增强了特征图的表达能力。这种做法类似于FCN网络中FCN8s,最终对特征图使用2个1x1的卷积层对通道做整合计算输出一个与input宽高维度相等,但是通道数为1的特征图,最后接一个Sigmoid激活函数层将特征图归一化到0~1之间。这一部分的做法如下图所示。

Spatial Attention and Channel Attention
论文作者在Attention这部分总共考虑了三种Attention方式,Spatial Attention使用L2正则化约束每个位置上的所有通道,推测最终输出一个空间维度一致的Attention Map;Channel Attention,类似于SENet约束每一个通道上的所有特征值,最后输出长度与通道数相同的一维向量作为特征加权;Mix Attention对每个通道和每个空间位置使用Sigmoid。不同Attention的计算公式如下所示

论文作者也对三种Attention方法的分类结果做了对比,对比结果如下所示:

Network Structure
网络的结构如下所示:
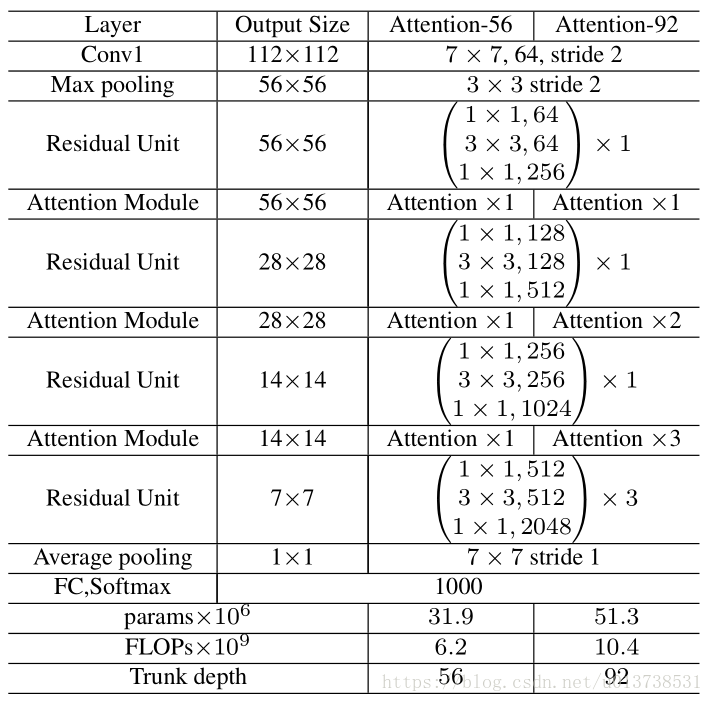
上图是一个使用在ResNet-50上的例子,可以看出来和原始的ResNet的区别就是在每个阶段的Residual Block之间增加了Attention Module,可以看到最小的输出特征图的宽高大小为7x7,上文中说到,在每一个Soft Mask Branch中对于input的特征图,会不断地卷积操作之后使用Max-Pooling降采样,文中降采样的宽高维度下限就是网络的最小输出特征图,比如这里的7x7。
Conclusion
深度学习发展到现在,有很多工作开始逐渐的转向Attention的融合上去做,过去通过一个单一结构的网络提取整张图像的特征用于分类、检测和分割,其实从人脑配合人眼的机制去思考,这种方法不一定是最优的,每一个图像样本都具有内容性,而且基本一张图片的内容并不会均匀分布在画面中的每一块区域,对于图像的内容区域使用Attention机制进行辅助可以增强有效信息同时抑制无效信息。目前这一方法被用于大部分计算机视觉任务中。