Spark 是什么?
● 官方文档解释:Apache Spark is a fast and general engine for large-scale data processing.
通俗的理解:Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark 部署在大量廉价硬件之上,形成集群。
● 扩展了MapReduce计算模型;相比与MapReduce编程模型,Spark提供了更加灵活的DAG(Directed Acyclic Graph) 编程模型, 不仅包含传统的map、reduce接口, 还增加了filter、flatMap、union等操作接口,使得编写Spark程序更加灵活方便。
● 高效支持多种计算模式;Spark 不仅可以做离线运算,还可以做流式运算以及迭代式运算。
Spark与Hadoop的关系
Spark与Hadoop的关系---青出于蓝
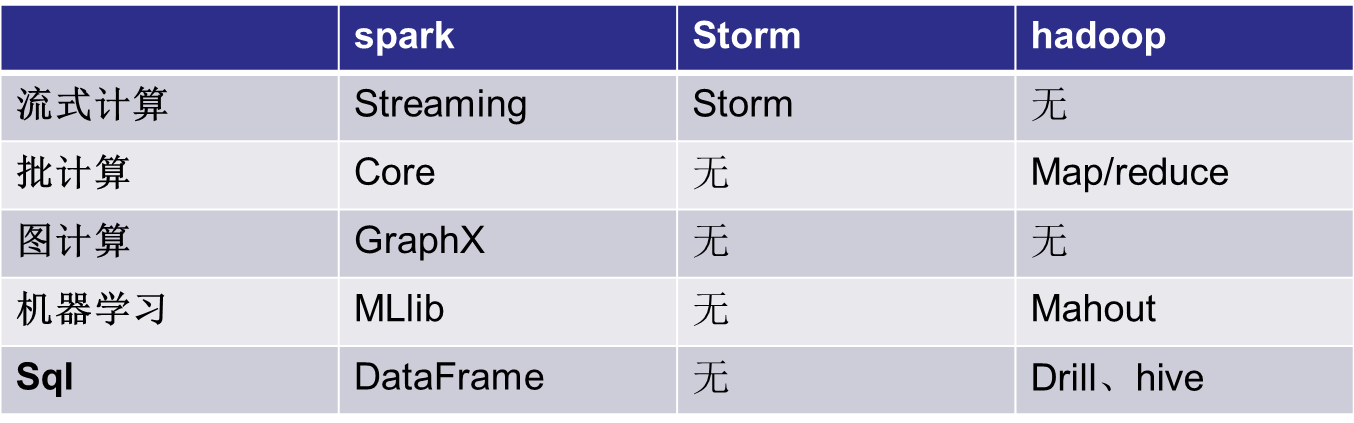
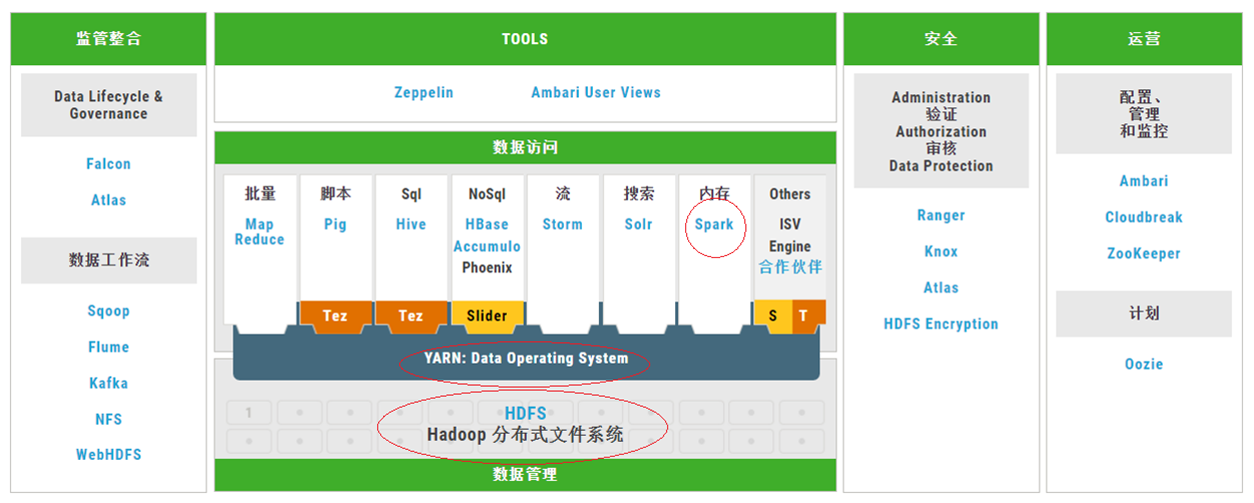
Spark与Hadoop的关系---相辅相成
Spark的竞争对手---Flink

● Flink是先有流处理后有批处理
● Pipeline vs Stage
● 详细内容参看http://note.youdao.com/share/?id=f3b0a1832e4ee43e3e3635913d5e00e1&type=note
Spark的竞争对手---Storm/JStorm

● Storm仅限于流计算(topology)
● JStorm参照Flink改进了Storm
Spark的竞争对手---Hadoop3.x
详细内容参看http://blog.51cto.com/zero01/2096435