1. OutputFormat接口
OutputFormat为输出格式接口,主要用于描述输出数据的格式,它能将输出的键值对写入特定格式的文件中。输出格式的层次结构如下
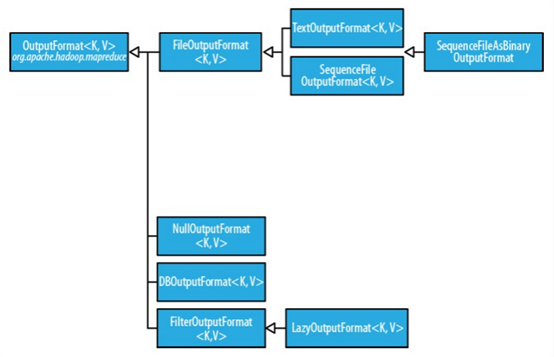
2. 文本输出
Hadoop默认的输出格式为文本输出格式TextOutputFormat,其键和值可以使任意类型的,因为该输出方式会调用toString()方法将它们转化为字符串。每个键/值对由制表符进行分割,当然也可以设定 mapreduce.output.textoutputformat.separator 属性(旧版本 API 中为 mapred.textoutputformat.separator)改变默认的分隔符。
3. 二进制输出
二进制输出有三种方式:SequenceFileOutputFormat,SequenceFileAsBinaryOutputFormat和MapFileOutputFormat。重点掌握第一种。
对于SequenceFileOutputFormat,顾名思义,SequenceFileOutputFormat 将它的输出写为一个顺序文件。如果输出需要作为后续 MapReduce 任务的输入,这便是一种好的输出格式, 因为它的格式紧凑,并且很容易被压缩。而对于SequenceFileAsBinaryOutputFormat,它将键/值对作为二进制格式写到一个 SequenceFile 容器中。不同的是,MapFileOutputFormat 把 MapFile 作为输出。MapFile 中的键必须顺序添加,所以必须确保 reducer 输出的键已经排好序。
4. 多个输出
由于默认情况下只有一个 Reducer,输出只有一个文件。有时可能需要对输出的文件名进行控制或让每个 reducer 输出多个文件。
当只有一个reduce时,输出文件命名格式为:part-r-00000。当有两个reduce时,输出文件命名格式为:part-r-00000,part-r-00001。当有多个时以此类推。实现Reducer输出多个文件主要有以下两种方式:Partitioner和MultipleOutputs。
4.1 Partitioner
我们考虑这样一个需求:按学生的年龄段,将数据输出到不同的文件路径下。这里我们分为三个年龄段:小于等于20岁、大于20岁小于等于50岁和大于50岁。
我们采用的方法是每个年龄段对应一个 reducer。为此,我们需要通过以下两步实现。
第一步:把作业的 reducer 数设为年龄段数即为3。
job.setPartitionerClass(PCPartitioner.class);//设置Partitioner类
job.setNumReduceTasks(3);// reduce个数设置为3
第二步:写一个 Partitioner,把同一个年龄段的数据放到同一个分区。
public static class PCPartitioner extends Partitioner< Text, Text>
{
@Override
public int getPartition(Text key, Text value, int numReduceTasks) {
// TODO Auto-generated method stub
String[] nameAgeScore = value.toString().split(" ");
String age = nameAgeScore[1];//学生年龄
int ageInt = Integer.parseInt(age);//按年龄段分区
// 默认指定分区 0
if (numReduceTasks == 0)
return 0;
//年龄小于等于20,指定分区0
if (ageInt <= 20) {
return 0;
}
// 年龄大于20,小于等于50,指定分区1
if (ageInt > 20 && ageInt <= 50) {
return 1 % numReduceTasks;
}
// 剩余年龄,指定分区2
else
return 2 % numReduceTasks;
}
}
这种方法即实现了多文件输出,但也只能满足此种需求。很多情况下是无法实现的,因为这样做存在两个缺点:
1)需要在作业运行之前需要知道分区数和年龄段的个数,如果分区数很大或者未知,就无法操作。
2)一般来说,让应用程序来严格限定分区数并不好,因为这样可能导致分区数少或分区不均。
4.2 MultipleOutputs
MultipleOutputs 类可以将数据写到多个文件,这些文件的名称源于输出的键和值或者任意字符串。这允许每个 reducer(或者只有 map 作业的 mapper)创建多个文件。 采用name-m-nnnnn 形式的文件名用于 map 输出,name-r-nnnnn 形式的文件名用于 reduce 输出,其中 name 是由程序设定的任意名字, nnnnn 是一个指明块号的整数(从 00000 开始)。块号保证从不同块(mapper 或 reducer)写的输出在相同名字情况下不会冲突。
实例将在下一篇博文(MapReduce实战:邮箱统计及多输出格式实现)给出!
5. 数据库输出
DBOutputFormat 适用于将作业输出数据(中等规模的数据)转存到Mysql、Oracle等数据库。如果数据量较大请考虑其他方法将输出数据导入或转存到数据库中。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。