一、解决的问题:
通常的 Propensity Model 和 Response Model 只是给目标用户打了个分,并没有确保模型的结果可以使得活动的提升最大化;它没有告诉市场营销人员,哪个用户最有可能提升活动响应;
因此,需要另外一个统计模型,用来定向那些可以被营销推广活动明显驱动他们偏好响应的用户,也就是“营销敏感”用户;
Uplift Model的最终目标就是找到最有可能被营销活动影响的用户,从而提升活动的反响(r(test)-r(control))、提升ROI、提升整体的市场响应率;
因此,模型要避免推广预算花在
(一)从购买者角度来看:
(1)自然反应的用户(即不需要营销也会来的用户);(2)顽固不会响应的用户;
(二)从流失者的角度来说:
(1)肯定的用户;
(2)因为进行了市场推广反而流失的用户;
(3)没有意识到是否有这个活动会有什么影响的用户;(即营销不敏感的用户)
二、什么是uplift model ?
直接为treatment所带来的影响提升建模;
三、如何进行uplift modeling?(差分响应)
方法(一):
1、建立两个logistic模型
Logit(Ptest(response|X,treatment =1)) = a+ b*X +c*treatment
Logit(Pcontrol(response|X,treatment=0) ) = a + b*X
2、将两个得分相减,计算uplift score
Score = Ptest(response|X,treatment =1) - Pcontrol(response|X,treatment =0)
方法(二):
只用一个模型,但是建立两个同样的;
1、Logit(P(reponse|X) = a + b*X + c*treatment + d* treatment *X
2、将两个得分相减得到uplift score
Score = P(response|X,treatment =1) - P(response|X,treatment =0)
方法(三):
knn modeling
方法(四):
Naive Bayes
四、uplift model使用过程中需要注意的问题:
1、训练样本
由于强化学习需要用到的是反馈数据,因此训练样本的及时及自动更新会是比较重要的方面(尤其是label的更新和实时特征的更新),才能体现出来强化学习优于机器学习的地方,使用用户反馈的标注样本来更新训练样本库,可以使得反馈及时地得到学习,从而优化算法效果;
2、label设计问题
3、问题定义
uplift的点与运营活动指标完美结合
4、冷启动策略问题
5、抽样训练时样本有偏的问题
总结:
"Where traditional predictive modeling focuses on the outcome, uplift modeling focuses on the effectiveness of the treatment.Then, you can target resources on the cases that are likely to be positively impacted by the treatment."
Uplift Model 的精髓是,它专注于作用之后效果的提升,因此区分出“营销/核销敏感人群”这一步特别重要,也是筛选特征的重要考虑方面;它对ROI结果的优化,不是在于模型设计的复杂,而是在于将ROI的思维策略融入到了模型当中。
但是其实ROI并不仅仅是提升核销率,从长远的营销价值来说,ROI最优化还需要考虑用户的终身价值,也就是对用户所投入的每一分钱,是否对该用户长远来看给企业带来的价值是最大化的。
Uplift Model对正负样本的定义就是,with treatment 和 without treatment的时候,是否具有response。
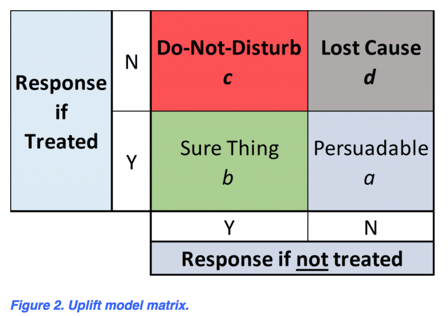
上图就是uplift model的建模假设矩阵。