第11节深度探秘搜索技术_案例实战基于dis_max实现best fields策略进行多字段搜索
课程大纲
1、为帖子数据增加content字段
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"content" : "i like to write best elasticsearch article"} }
{ "update": { "_id": "2"} }
{ "doc" : {"content" : "i think java is the best programming language"} }
{ "update": { "_id": "3"} }
{ "doc" : {"content" : "i am only an elasticsearch beginner"} }
{ "update": { "_id": "4"} }
{ "doc" : {"content" : "elasticsearch and hadoop are all very good solution, i am a beginner"} }
{ "update": { "_id": "5"} }
{ "doc" : {"content" : "spark is best big data solution based on scala ,an programming language similar to java"} }
2、搜索title或content中包含java或solution的帖子
下面这个就是multi-field搜索,多字段搜索
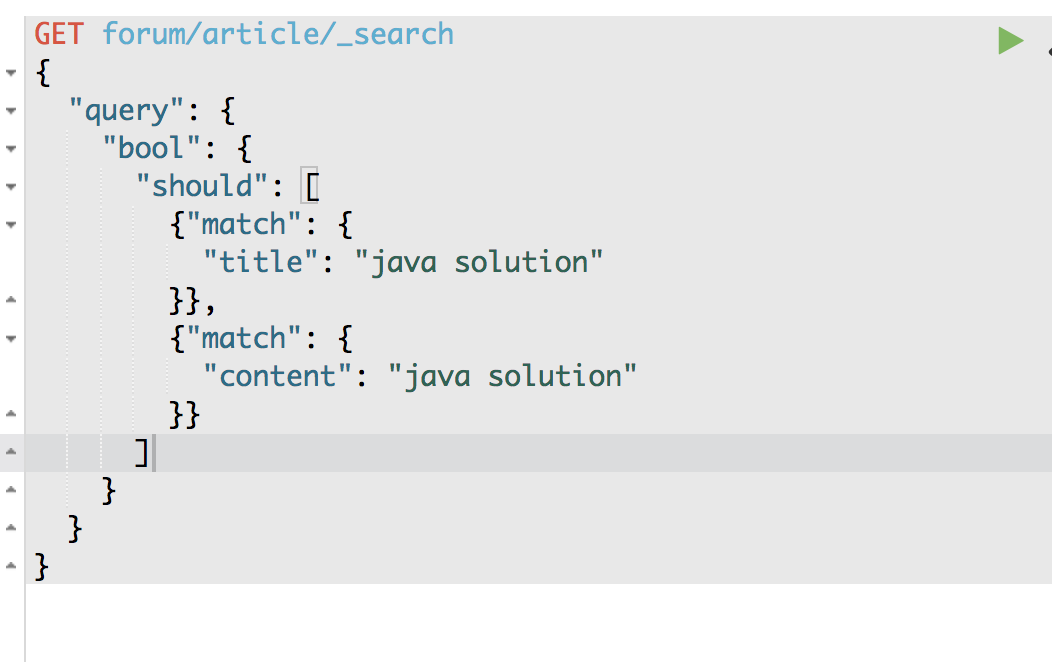
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
3、结果分析
期望的是doc5,结果是doc2,doc4排在了前面
计算每个document的relevance score:每个query的分数,乘以matched query数量,除以总query数量
算一下doc4的分数
{ "match": { "title": "java solution" }},针对doc4,是有一个分数的
{ "match": { "content": "java solution" }},针对doc4,也是有一个分数的
所以是两个分数加起来,比如说,1.1 + 1.2 = 2.3
matched query数量 = 2
总query数量 = 2
2.3 * 2 / 2 = 2.3
算一下doc5的分数
{ "match": { "title": "java solution" }},针对doc5,是没有分数的
{ "match": { "content": "java solution" }},针对doc5,是有一个分数的
所以说,只有一个query是有分数的,比如2.3
matched query数量 = 1
总query数量 = 2
2.3 * 1 / 2 = 1.15
doc5的分数 = 1.15 < doc4的分数 = 2.3
4、best fields策略,dis_max
best fields策略,就是说,搜索到的结果,应该是某一个field中匹配到了尽可能多的关键词,被排在前面;而不是尽可能多的field匹配到了少数的关键词,排在了前面
dis_max语法,直接取多个query中,分数最高的那一个query的分数即可(取最大的分数)
{ "match": { "title": "java solution" }},针对doc4,是有一个分数的,1.1
{ "match": { "content": "java solution" }},针对doc4,也是有一个分数的,1.2
取最大分数,1.2
{ "match": { "title": "java solution" }},针对doc5,是没有分数的
{ "match": { "content": "java solution" }},针对doc5,是有一个分数的,2.3
取最大分数,2.3
然后doc4的分数 = 1.2 < doc5的分数 = 2.3,所以doc5就可以排在更前面的地方,符合我们的需要
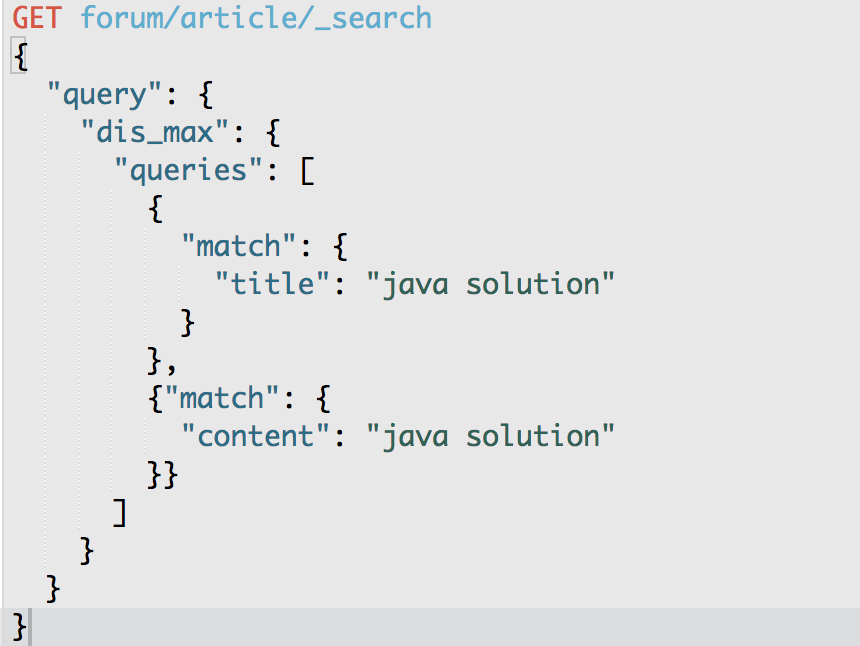
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
第12节深度探秘搜索技术_案例实战基于tie_breaker参数优化dis_max搜索效果.mp4
课程大纲
1、搜索title或content中包含java beginner的帖子
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java beginner" }},
{ "match": { "body": "java beginner" }}
]
}
}
}
有些场景不是太好复现的,因为是这样,你需要尝试去构造不同的文本,然后去构造一些搜索出来,去达到你要的一个效果
可能在实际场景中出现的一个情况是这样的:
(1)某个帖子,doc1,title中包含java,content不包含java beginner任何一个关键词
(2)某个帖子,doc2,content中包含beginner,title中不包含任何一个关键词
(3)某个帖子,doc3,title中包含java,content中包含beginner
(4)最终搜索,可能出来的结果是,doc1和doc2排在doc3的前面,而不是我们期望的doc3排在最前面
dis_max,只是取分数最高的那个query的分数而已。
2、dis_max只取某一个query最大的分数,完全不考虑其他query的分数
3、使用tie_breaker将其他query的分数也考虑进去
tie_breaker参数的意义,在于说,将其他query的分数,乘以tie_breaker,然后综合与最高分数的那个query的分数,综合在一起进行计算
除了取最高分以外,还会考虑其他的query的分数
tie_breaker的值,在0~1之间,是个小数,就ok
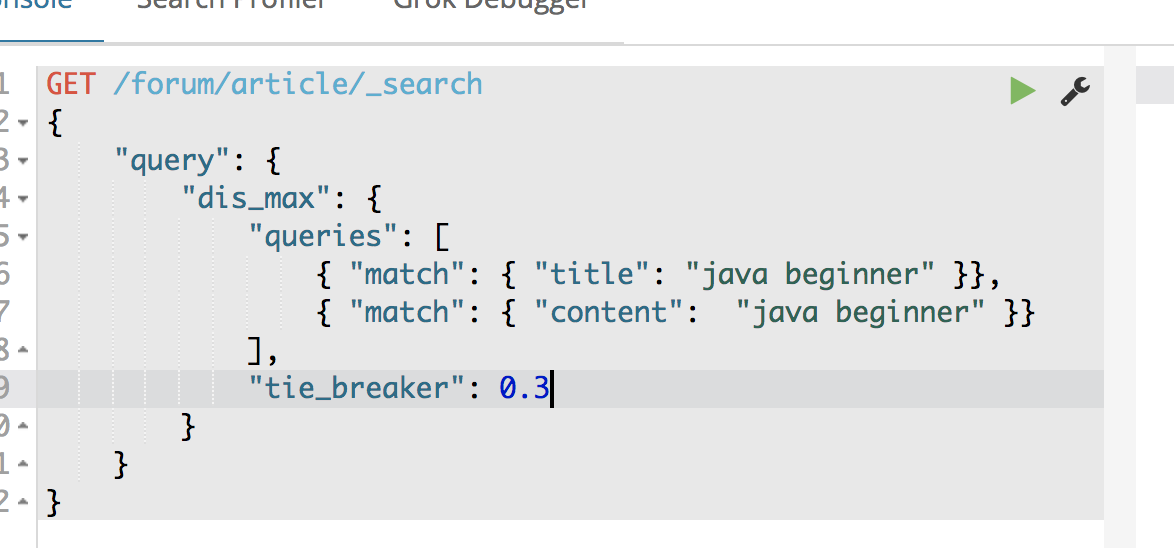
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java beginner" }},
{ "match": { "body": "java beginner" }}
],
"tie_breaker": 0.3
}
}
}
第13节深度探秘搜索技术_案例实战基于multi_match语法实现dis_max+tie_breaker
课程大纲
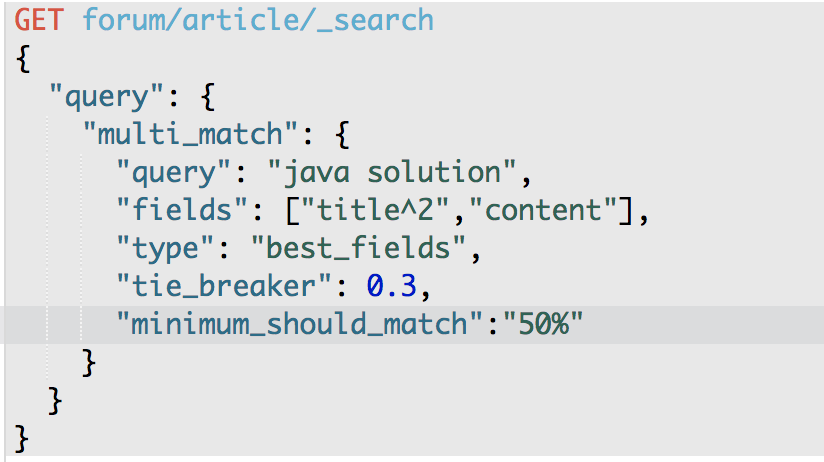
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "java solution",
"type": "best_fields",
"fields": [ "title^2", "content" ],
"tie_breaker": 0.3,
"minimum_should_match": "50%"
}
}
}
^2搜索词 针对 title的field的权重为2
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": {
"query": "java beginner",
"minimum_should_match": "50%",
"boost": 2
}
}
},
{
"match": {
"body": {
"query": "java beginner",
"minimum_should_match": "30%"
}
}
}
],
"tie_breaker": 0.3
}
}
}
minimum_should_match,主要是用来干嘛的?
去长尾,long tail
长尾,比如你搜索5个关键词,但是很多结果是只匹配1个关键词的,其实跟你想要的结果相差甚远,这些结果就是长尾
minimum_should_match,控制搜索结果的精准度,只有匹配一定数量的关键词的数据,才能返回
第14节深度探秘搜索技术_基于multi_match+most fiels策略进行multi-field搜索
课程大纲
从best-fields换成most-fields策略
best-fields策略,主要是说将某一个field匹配尽可能多的关键词的doc优先返回回来
most-fields策略,主要是说尽可能返回更多field匹配到某个关键词的doc,优先返回回来
sub_title 使用english分词器
sub_title.std使用string分词器
POST /forum/_mapping/article
{
"properties": { "sub_title": {
"type": "string",
"analyzer": "english",
"fields": {
"std": {
"type": "string",
"analyzer": "standard"
}
}
}
}
}
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"sub_title" : "learning more courses"} }
{ "update": { "_id": "2"} }
{ "doc" : {"sub_title" : "learned a lot of course"} }
{ "update": { "_id": "3"} }
{ "doc" : {"sub_title" : "we have a lot of fun"} }
{ "update": { "_id": "4"} }
{ "doc" : {"sub_title" : "both of them are good"} }
{ "update": { "_id": "5"} }
{ "doc" : {"sub_title" : "haha, hello world"} }
GET /forum/article/_search
{
"query": {
"match": {
"sub_title": "learning courses"
}
}
}
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.219939,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1.219939,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.5063205,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses"
}
}
]
}
}
sub_title用的是enligsh analyzer,所以还原了单词
为什么,因为如果我们用的是类似于english analyzer这种分词器的话,就会将单词还原为其最基本的形态,stemmer
learning --> learn
learned --> learn
courses --> course
sub_titile: learning coureses --> learn course
{ "doc" : {"sub_title" : "learned a lot of course"} },就排在了{ "doc" : {"sub_title" : "learning more courses"} }的前面
GET /forum/article/_search
{
"query": {
"match": {
"sub_title": "learning courses"
}
}
}
很绕。。。。我自己都觉得很绕
很多东西,你看文字就觉得很绕,然后用语言去表述,也很绕,但是我觉得,用语言去说,相对来说会好一点点
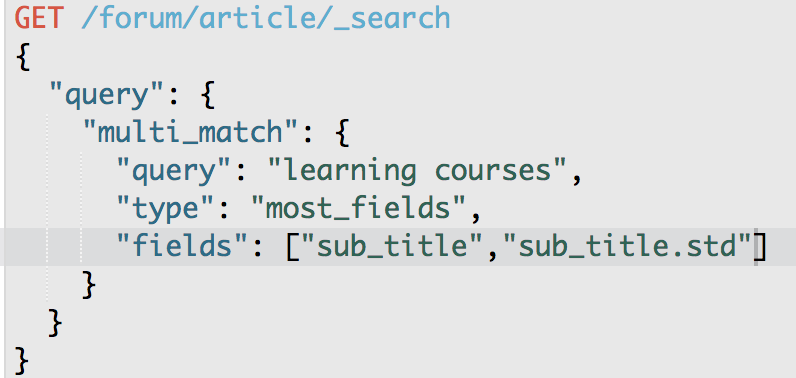
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "learning courses",
"type": "most_fields",
"fields": [ "sub_title", "sub_title.std" ]
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.219939,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1.219939,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1.012641,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses"
}
}
]
}
}
你问我,具体的分数怎么算出来的,很难说,因为这个东西很复杂, 还不只是TF/IDF算法。因为不同的query,不同的语法,都有不同的计算score的细节。
与best_fields的区别
(1)best_fields,是对多个field进行搜索,挑选某个field匹配度最高的那个分数,同时在多个query最高分相同的情况下,在一定程度上考虑其他query的分数。简单来说,你对多个field进行搜索,就想搜索到某一个field尽可能包含更多关键字的数据
优点:通过best_fields策略,以及综合考虑其他field,还有minimum_should_match支持,可以尽可能精准地将匹配的结果推送到最前面
缺点:除了那些精准匹配的结果,其他差不多大的结果,排序结果不是太均匀,没有什么区分度了
实际的例子:百度之类的搜索引擎,最匹配的到最前面,但是其他的就没什么区分度了
(2)most_fields,综合多个field一起进行搜索,尽可能多地让所有field的query参与到总分数的计算中来,此时就会是个大杂烩,出现类似best_fields案例最开始的那个结果,结果不一定精准,某一个document的一个field包含更多的关键字,但是因为其他document有更多field匹配到了,所以排在了前面;所以需要建立类似sub_title.std这样的field,尽可能让某一个field精准匹配query string,贡献更高的分数,将更精准匹配的数据排到前面
优点:将尽可能匹配更多field的结果推送到最前面,整个排序结果是比较均匀的
缺点:可能那些精准匹配的结果,无法推送到最前面
实际的例子:wiki,明显的most_fields策略,搜索结果比较均匀,但是的确要翻好几页才能找到最匹配的结果
第15节深度探秘搜索技术_使用most_fields策略进行cross-fields search弊端大揭秘
课程大纲
cross-fields搜索,一个唯一标识,跨了多个field。比如一个人,标识,是姓名;一个建筑,它的标识是地址。姓名可以散落在多个field中,比如first_name和last_name中,地址可以散落在country,province,city中。
跨多个field搜索一个标识,比如搜索一个人名,或者一个地址,就是cross-fields搜索
初步来说,如果要实现,可能用most_fields比较合适。因为best_fields是优先搜索单个field最匹配的结果,cross-fields本身就不是一个field的问题了。
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"author_first_name" : "Peter", "author_last_name" : "Smith"} }
{ "update": { "_id": "2"} }
{ "doc" : {"author_first_name" : "Smith", "author_last_name" : "Williams"} }
{ "update": { "_id": "3"} }
{ "doc" : {"author_first_name" : "Jack", "author_last_name" : "Ma"} }
{ "update": { "_id": "4"} }
{ "doc" : {"author_first_name" : "Robbin", "author_last_name" : "Li"} }
{ "update": { "_id": "5"} }
{ "doc" : {"author_first_name" : "Tonny", "author_last_name" : "Peter Smith"} }
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "most_fields",
"fields": [ "author_first_name", "author_last_name" ]
}
}
}
Peter Smith,匹配author_first_name,匹配到了Smith,这时候它的分数很高,为什么啊???
因为IDF分数高,IDF分数要高,那么这个匹配到的term(Smith),在所有doc中的出现频率要低,author_first_name field中,Smith就出现过1次
Peter Smith这个人,doc 1,Smith在author_last_name中,但是author_last_name出现了两次Smith,所以导致doc 1的IDF分数较低
不要有过多的疑问,一定是这样吗?
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.6931472,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.6931472,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.5753642,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.51623213,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith"
}
}
]
}
}
问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面
第16节深度探秘搜索技术_使用copy_to定制组合field解决cross-fields搜索弊端
课程大纲
上一讲,我们其实说了,用most_fields策略,去实现cross-fields搜索,有3大弊端,而且搜索结果也显示出了这3大弊端
第一个办法:用copy_to,将多个field组合成一个field
问题其实就出在有多个field,有多个field以后,就很尴尬,我们只要想办法将一个标识跨在多个field的情况,合并成一个field即可。比如说,一个人名,本来是first_name,last_name,现在合并成一个full_name,不就ok了吗。。。。。
PUT /forum/_mapping/article
{
"properties": {
"new_author_first_name": {
"type": "string",
"copy_to": "new_author_full_name"
},
"new_author_last_name": {
"type": "string",
"copy_to": "new_author_full_name"
},
"new_author_full_name": {
"type": "string"
}
}
}
用了这个copy_to语法之后,就可以将多个字段的值拷贝到一个字段中,并建立倒排索引
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"new_author_first_name" : "Peter", "new_author_last_name" : "Smith"} } --> Peter Smith
{ "update": { "_id": "2"} }
{ "doc" : {"new_author_first_name" : "Smith", "new_author_last_name" : "Williams"} } --> Smith Williams
{ "update": { "_id": "3"} }
{ "doc" : {"new_author_first_name" : "Jack", "new_author_last_name" : "Ma"} } --> Jack Ma
{ "update": { "_id": "4"} }
{ "doc" : {"new_author_first_name" : "Robbin", "new_author_last_name" : "Li"} } --> Robbin Li
{ "update": { "_id": "5"} }
{ "doc" : {"new_author_first_name" : "Tonny", "new_author_last_name" : "Peter Smith"} } --> Tonny Peter Smith
GET /forum/article/_search
{
"query": {
"match": {
"new_author_full_name": "Peter Smith"
}
}
}
很无奈,很多时候,我们很难复现。比如官网也会给一些例子,说用什么什么文本,怎么怎么搜索,是怎么怎么样的效果。es版本在不断迭代,这个打分的算法也在不断的迭代。所以我们其实很难说,对类似这几讲讲解的best_fields,most_fields,cross_fields,完全复现出来应有的场景和效果。
更多的把原理和知识点给大家讲解清楚,带着大家演练一遍怎么操作的,做一下实验
期望的是说,比如大家自己在开发搜索应用的时候,碰到需要best_fields的场景,知道怎么做,知道best_fields的原理,可以达到什么效果;碰到most_fields的场景,知道怎么做,以及原理;碰到搜搜cross_fields标识的场景,知道怎么做,知道原理是什么,效果是什么。。。。
问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc --> 解决,最匹配的document被最先返回
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 --> 解决,可以使用minimum_should_match去掉长尾数据
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 --> 解决,Smith和Peter在一个field了,所以在所有document中出现的次数是均匀的,不会有极端的偏差
第17节深度探秘搜索技术_使用原生cross-fiels技术解决搜索弊端
课程大纲
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "cross_fields",
"operator": "and",
"fields": ["author_first_name", "author_last_name"]
}
}
}
问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc --> 解决,要求每个term都必须在任何一个field中出现
Peter,Smith
要求Peter必须在author_first_name或author_last_name中出现
要求Smith必须在author_first_name或author_last_name中出现
Peter Smith可能是横跨在多个field中的,所以必须要求每个term都在某个field中出现,组合起来才能组成我们想要的标识,完整的人名
原来most_fiels,可能像Smith Williams也可能会出现,因为most_fields要求只是任何一个field匹配了就可以,匹配的field越多,分数越高
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 --> 解决,既然每个term都要求出现,长尾肯定被去除掉了
java hadoop spark --> 这3个term都必须在任何一个field出现了
比如有的document,只有一个field中包含一个java,那就被干掉了,作为长尾就没了
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 --> 计算IDF的时候,将每个query在每个field中的IDF都取出来,取最小值,就不会出现极端情况下的极大值了
Peter Smith
Peter
Smith
Smith,在author_first_name这个field中,在所有doc的这个Field中,出现的频率很低,导致IDF分数很高;Smith在所有doc的author_last_name field中的频率算出一个IDF分数,因为一般来说last_name中的Smith频率都较高,所以IDF分数是正常的,不会太高;然后对于Smith来说,会取两个IDF分数中,较小的那个分数。就不会出现IDF分过高的情况。
第18节深度探秘搜索技术_在案例实战中掌握phrase matching搜索技术
近似匹配
1、什么是近似匹配
两个句子
java is my favourite programming language, and I also think spark is a very good big data system.
java spark are very related, because scala is spark's programming language and scala is also based on jvm like java.
match query,搜索java spark
{
"match": {
"content": "java spark"
}
}
match query,只能搜索到包含java和spark的document,但是不知道java和spark是不是离的很近
包含java或包含spark,或包含java和spark的doc,都会被返回回来。我们其实并不知道哪个doc,java和spark距离的比较近。如果我们就是希望搜索java spark,中间不能插入任何其他的字符,那这个时候match去做全文检索,能搞定我们的需求吗?答案是,搞不定。
如果我们要尽量让java和spark离的很近的document优先返回,要给它一个更高的relevance score,这就涉及到了proximity match,近似匹配
如果说,要实现两个需求:
1、java spark,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc
2、java spark,但是要求,java和spark两个单词靠的越近,doc的分数越高,排名越靠前
要实现上述两个需求,用match做全文检索,是搞不定的,必须得用proximity match,近似匹配
phrase match,proximity match:短语匹配,近似匹配
这一讲,要学习的是phrase match,就是仅仅搜索出java和spark靠在一起的那些doc,比如有个doc,是java use'd spark,不行。必须是比如java spark are very good friends,是可以搜索出来的。
phrase match,就是要去将多个term作为一个短语,一起去搜索,只有包含这个短语的doc才会作为结果返回。不像是match,java spark,java的doc也会返回,spark的doc也会返回。
2、match_phrase
GET /forum/article/_search
{
"query": {
"match": {
"content": "java spark"
}
}
}
单单包含java的doc也返回了,不是我们想要的结果
POST /forum/article/5/_update
{
"doc": {
"content": "spark is best big data solution based on scala ,an programming language similar to java spark"
}
}
将一个doc的content设置为恰巧包含java spark这个短语
match_phrase语法
GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": "java spark"
}
}
}

成功了,只有包含java spark这个短语的doc才返回了,只包含java的doc不会返回
3、term position
hello world, java spark doc1
hi, spark java doc2
hello doc1(0)
wolrd doc1(1)
java doc1(2) doc2(2)
spark doc1(3) doc2(1)
了解什么是分词后的position
GET _analyze
{
"text": "hello world, java spark",
"analyzer": "standard"
}
4、match_phrase的基本原理
索引中的position,match_phrase
hello world, java spark doc1
hi, spark java doc2
hello doc1(0)
wolrd doc1(1)
java doc1(2) doc2(2)
spark doc1(3) doc2(1)
java spark --> match phrase
java spark --> java和spark
java --> doc1(2) doc2(2)
spark --> doc1(3) doc2(1)
要找到每个term都在的一个共有的那些doc,就是要求一个doc,必须包含每个term,才能拿出来继续计算
doc1 --> java和spark --> spark position恰巧比java大1 --> java的position是2,spark的position是3,恰好满足条件
doc1符合条件
doc2 --> java和spark --> java position是2,spark position是1,spark position比java position小1,而不是大1 --> 光是position就不满足,那么doc2不匹配
必须理解这块原理!!!!
因为后面的proximity match就是原理跟这个一模一样!!!
第19节深度探秘搜索技术_基于slop参数实现近似匹配以及原理剖析和相关实验
GET /forum/article/_search
{
"query": {
"match_phrase": {
"title": {
"query": "java spark",
"slop": 1
}
}
}
}
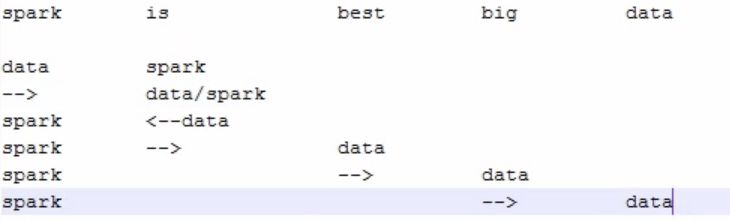
slop的含义是什么?
query string,搜索文本,中的几个term,要经过几次移动才能与一个document匹配,这个移动的次数,就是slop
实际举例,一个query string经过几次移动之后可以匹配到一个document,然后设置slop
hello world, java is very good, spark is also very good.
java spark,match phrase,搜不到
如果我们指定了slop,那么就允许java spark进行移动,来尝试与doc进行匹配
java is very good spark is

这里的slop,就是3,因为java spark这个短语,spark移动了3次,就可以跟一个doc匹配上了
slop的含义,不仅仅是说一个query string terms移动几次,跟一个doc匹配上。一个query string terms,最多可以移动几次去尝试跟一个doc匹配上
slop,设置的是3,那么就ok
GET /forum/article/_search
{
"query": {
"match_phrase": {
"title": {
"query": "java spark",
"slop": 3
}
}
}
}
就可以把刚才那个doc匹配上,那个doc会作为结果返回
但是如果slop设置的是2,那么java spark,spark最多只能移动2次,此时跟doc是匹配不上的,那个doc是不会作为结果返回的
做实验,验证slop的含义
GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": {
"query": "spark data",
"slop": 3
}
}
}
}
spark is best big data solution based on scala ,an programming language similar to java spark

GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": {
"query": "data spark",
"slop": 5
}
}
}
}
spark is best big data slop=5
slop搜索下,关键词离的越近,relevance score就会越高,做实验说明。。。
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.3728157,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1.3728157,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.5753642,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.28582606,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith",
"new_author_last_name": "Smith",
"new_author_first_name": "Peter"
}
}
]
}
}
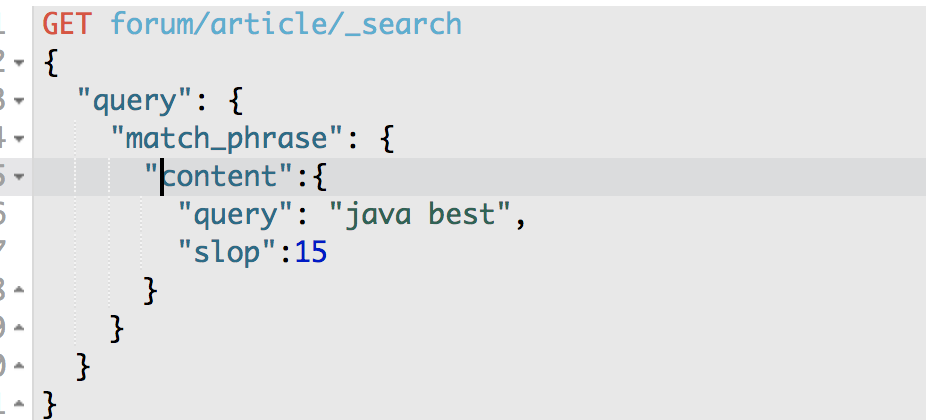
GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": {
"query": "java best",
"slop": 15
}
}
}
}
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.65380025,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.65380025,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.07111243,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny"
}
}
]
}
}
其实,加了slop的phrase match,就是proximity match,近似匹配
1、java spark,短语,doc,phrase match
2、java spark,可以有一定的距离,但是靠的越近,越先搜索出来,proximity match
第20节深度探秘搜索技术_混合使用match和近似匹配实现召回率与精准度的平衡
召回率
比如你搜索一个java spark,总共有100个doc,能返回多少个doc作为结果,就是召回率,recall
精准度
比如你搜索一个java spark,能不能尽可能让包含java spark,或者是java和spark离的很近的doc,排在最前面,precision
直接用match_phrase短语搜索,会导致必须所有term都在doc field中出现,而且距离在slop限定范围内,才能匹配上
match phrase,proximity match,要求doc必须包含所有的term,才能作为结果返回;如果某一个doc可能就是有某个term没有包含,那么就无法作为结果返回
java spark --> hello world java --> 就不能返回了
java spark --> hello world, java spark --> 才可以返回
近似匹配的时候,召回率比较低,精准度太高了
但是有时可能我们希望的是匹配到几个term中的部分,就可以作为结果出来,这样可以提高召回率。同时我们也希望用上match_phrase根据距离提升分数的功能,让几个term距离越近分数就越高,优先返回
就是优先满足召回率,意思,java spark,包含java的也返回,包含spark的也返回,包含java和spark的也返回;同时兼顾精准度,就是包含java和spark,同时java和spark离的越近的doc排在最前面
此时可以用bool组合match query和match_phrase query一起,来实现上述效果
GET /forum/article/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": {
"query": "java spark" --> java或spark或java spark,java和spark靠前,但是没法区分java和spark的距离,也许java和spark靠的很近,但是没法排在最前面
}
}
},
"should": {
"match_phrase": { --> 在slop以内,如果java spark能匹配上一个doc,那么就会对doc贡献自己的relevance score,如果java和spark靠的越近,那么就分数越高
"title": {
"query": "java spark",
"slop": 50
}
}
}
}
}
}
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content": "java spark"
}
}
]
}
}
}
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.68640786,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.68640786,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"followers": [
"Tom",
"Jack"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.68324494,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"followers": [
"Jack",
"Robbin Li"
]
}
}
]
}
}
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content": "java spark"
}
}
],
"should": [
{
"match_phrase": {
"content": {
"query": "java spark",
"slop": 50
}
}
}
]
}
}
}
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.258609,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 1.258609,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"followers": [
"Jack",
"Robbin Li"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.68640786,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"followers": [
"Tom",
"Jack"
]
}
}
]
}
}