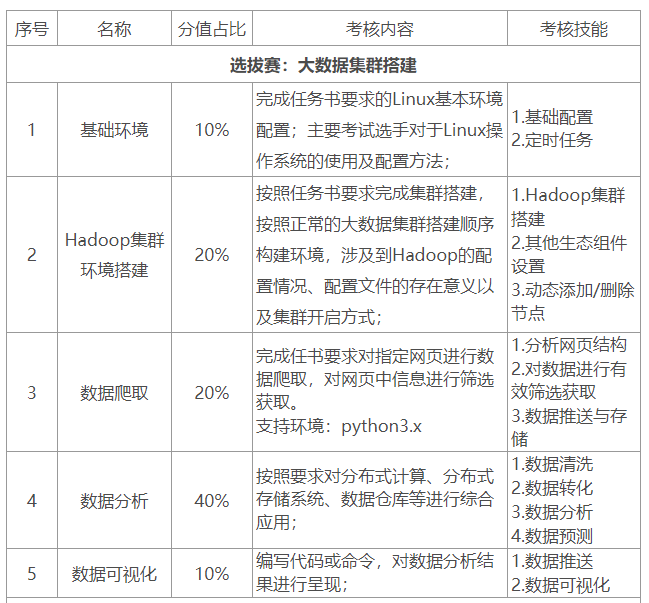
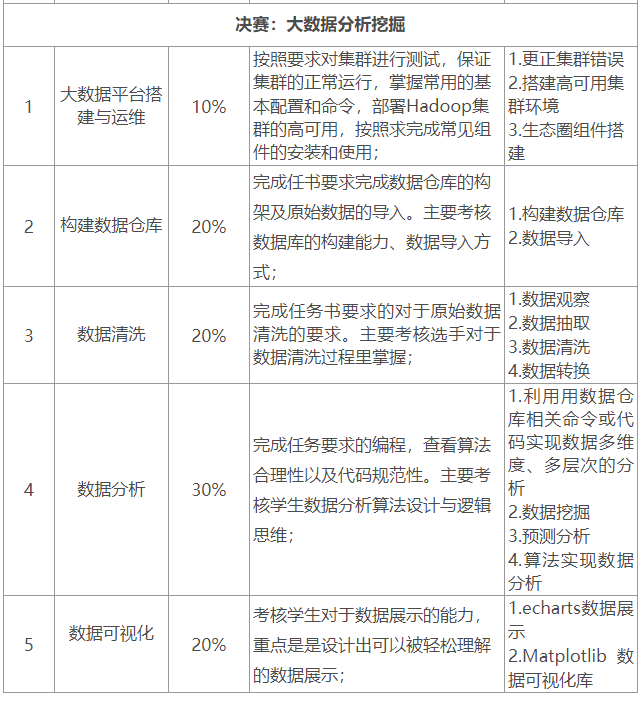
比赛项目
相关软件下载
链接:https://pan.baidu.com/s/1W4rVk5D4Zp3nEn7iyXnlsQ
提取码:rdyo
Hadoop技术
2.1 Liunx 系统环境准备
3月份白嫖的阿里云ECS云服务器终于有用了,ubuntu 16.04 64bit,开始搭环境
都是一些基本的命令,如果以前 Linux 用得少按课程资料照猫画虎也行
2.2 HDFS伪分布式集群搭建
HDFS 是负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
伪分布是因为只有一台云主机,以后看看有什么项目能用到真框架吧
首先是安装 hadoop,用了网盘里的版本,据说和比赛的匹配
然后就开始按课程资料一步步配置文档,有些地方按自己的想法改着做了,没出问题
就是我 vim 还用得比较蹩脚,快捷键记不住哈哈
2.3 YARN 伪分布式集群搭建
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
配置过程同上,没啥好说的
附启动集群成功截图一张:

2.4 Hadoop 集群初体验
因为是 SSH 到云服务器上的,好像没映射其他端口,看不到 UI 界面
这节课主要就是让我们用 hadoop 的样例程序体验一下分布式计算过程,也没啥好说的
数据仓库hive
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能, Hive 底层是将 SQL 语句转换为 MapReduce 任务运行。

(1)Hive 处理的数据存储在 HDFS;
(2)Hive 分析数据底层的实现是 MapReduce,利用 MapReduce 查询数据;
(3)执行程序运行在 YARN 上。

2.1 Hive 内嵌模式安装
内嵌模式:将元数据保存在本地内嵌的 Derby 数据库中,这是使用 Hive 最简单的方式。但是这种方式缺点也比较明显,因为一个内嵌的 Derby 数据库每次只能访问一个数据文件,这也就意味着它不支持多会话连接。
按照课程资料给定流程安装,注意在同一个目录下同时只能有一个 Hive 客户端能使用数据库

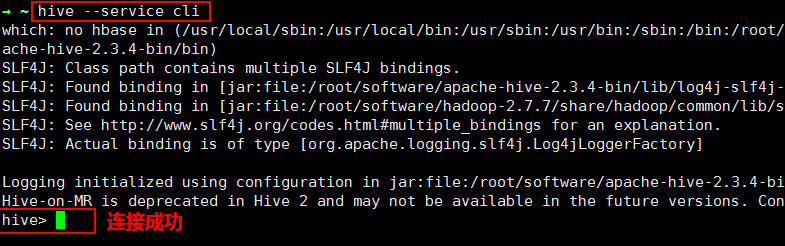
输入 hive 有反馈即连接成功(注意 hive 是基于 hadoop 的,所以事先要在该目录下启动集群 start-dfs.sh start-yarn.sh )
2.2 Hive 本地模式安装
这种模式是将元数据保存在本地独立的数据库中(一般是 MySQL),这种方式是一个多用户的模式,运行多个用户 Client 连接到一个数据库中。这种方式一般作为公司内部同时使用 Hive。 这里有一个前提,每一个用户必须要有对 MySQL 的访问权利,即每一个客户端使用者需要知道 MySQL 的用户名和密码才行。
首先安装 MySQL,由于用的是云服务器(Ubuntu 16.04 64bit),用不了课程资料中的 rpm 包,以下是用 apt 的半自动安装步骤:
(1)更新 apt-get > sudo apt-get update
(2)安装服务端 > sudo apt-get install mysql-server
会有一个界面要求设置密码
(3)安装客户端 > sudo apt-get install mysql-client
(4)安装链接库 > sudo apt-get install libmysqlclient-dev
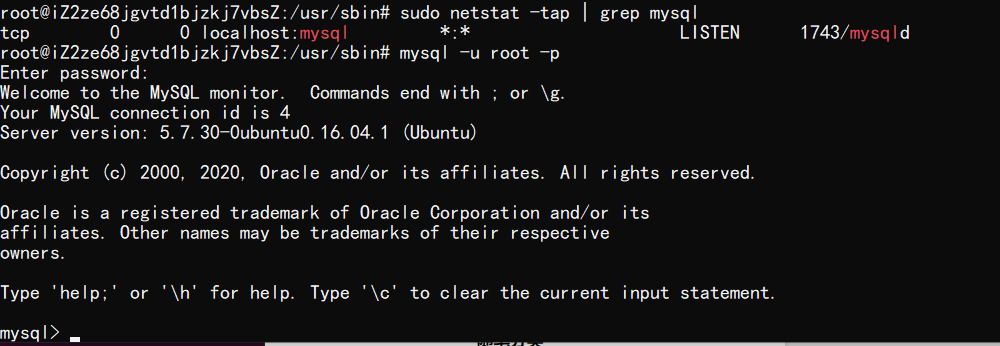
配置和启动流程和课程资料一致,包括:
-
初始化 MySQL 的数据库
-
启动 MySQL 服务

- 登录 MySQL

-
重置 MySQL 密码
-
增加远程登录权限
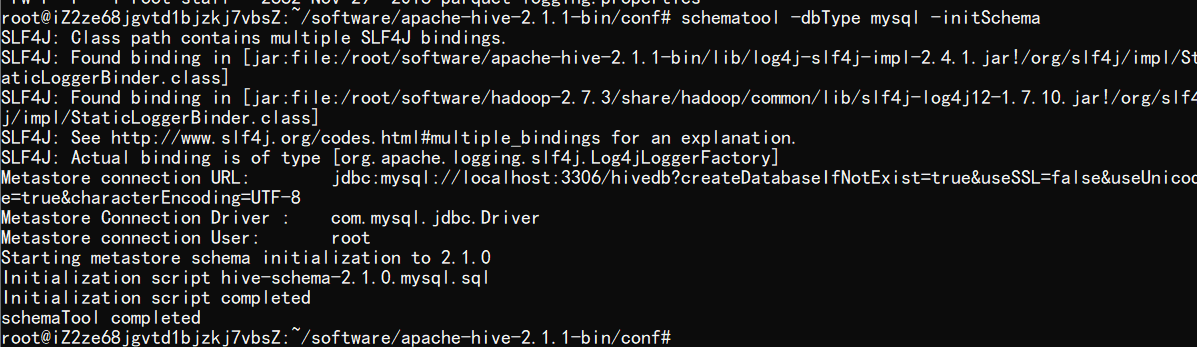

然后要把 Hive 元数据配置到 MySQL
3.1 驱动拷贝
将/root/software目录下的 MySQL 驱动包 mysql-connector-java-5.1.47-bin.jar 拷贝到 ${HIVE_HOME}/lib 目录下。
3.2 配置 Metastore到MySQL
同样按课程资料操作
3.3 初始化元数据库
中途报错了一次,重写了一次配置文件修复了

3.4 Hive 连接
注意启动 Hive 之前要先启动 Hadoop
爬虫技术
Python Requests lib
...