题目描述:
DreamJack 同学最近在学习数据结构,他没事干写了一个压缩软件,准备交给老师当大作业用。
他用哈夫曼树,二叉堆,位图,和字典树实现了软件的压缩部分。
可是他不想写这个软件的解压缩部分,太懒了。
今天 DreamerJack 同学给你发来了一个神秘的 whereIsMyFlag.jzpk 文件,你能破解这个文件吗?
附件描述:
.jzpk 文件,即 Jack ZIP Package 文件,为 DreamerJack 同学开发的新型压缩文件格式
其文件结构如下定义所述:
头部 (8Byte) ,描述该压缩文件数据段所占比特数目 ((Bit))
剩下的全是数据段,数据段中的数据以比特为最小单位
数据段:
首先是哈夫曼树字典信息:
for(int i=0;i<256;i++){
占用8Bit空间的整形i_len:指明原文件中值为i的单个字节(8Bit)被压缩后占用几个比特空间
占用i_len Bit空间的01二进制串:指明原文件中值为i的单个字节被哈夫曼树压缩后的新编码
}
接下来全是用哈夫曼树压缩后的新编码表示的信息,一个比特紧邻一个比特连续不断
举例:
假设我有一哈夫曼树,对于整个文件中每个字节有256种可能的组合,其中只有两种字节在文件中存在:
假设经压缩后长度变化为 (3Bit)
(00000001) ,压缩后为 (001)
(00000000) ,压缩后为 (000)
假设其他的 (254) 种字节都没有编码表示(此处仅举例用)
假设要存储数据 (10) ,那么压缩后的数据为 (001000) ,长度为 (6)
哈夫曼树字典信息为(为查看方便加上空格和换行,实际上空格和换行在二进制文件中并不存在,而且所有 (0) 和 (1) 都以二进制形式表示)
00000011 000
00000011 001
00000000
00000000
...以此类推 直到 (256) 种字节都表示完毕为止(后面还会有 ((256-4)*8) 个 (0) )字典信息长度为 (2054)
头部 (8Byte) ,指示数据段长度,值为 (2060) 的 (long long) ,长度为 (8)
那么这个文件共 (8+2054+6) 个字节,顺序为头部 + 哈夫曼树字典 + 压缩后的信息
备注:所有整型变量均采用 小端储存 。
————————————————————————————
CTF比赛居然还能有这种题,长见识了...
这是一道披着数据结构外皮的一道模拟题,就算没学过哈夫曼编码也可以做,但是要对计算机底层有一定的了解。
哈夫曼编码的原理是利用更短的二进制编码表示不同字符序列,其压缩率通常在 (20\%~90\%) 之间。
其需要满足最小冗余和惟一编码两个要求,前者通过用短(长)编码表示频率大(小)的字符来实现(本质是构造哈夫曼树),后者要求任一字符的二进制编码都不能是另一字符编码的前缀。
DreamJack 同学既然能发明出这种压缩算法,必然是满足上面两个要求的,所以只需要按照题意模拟即可。
比赛的时先花了好长时间研究如何让程序读入二进制数据,然后发现不太好弄...于是我是用 (WinHex) 复制了十六进制数据到文件 data.txt,然后以字符串的形式让程序读入。
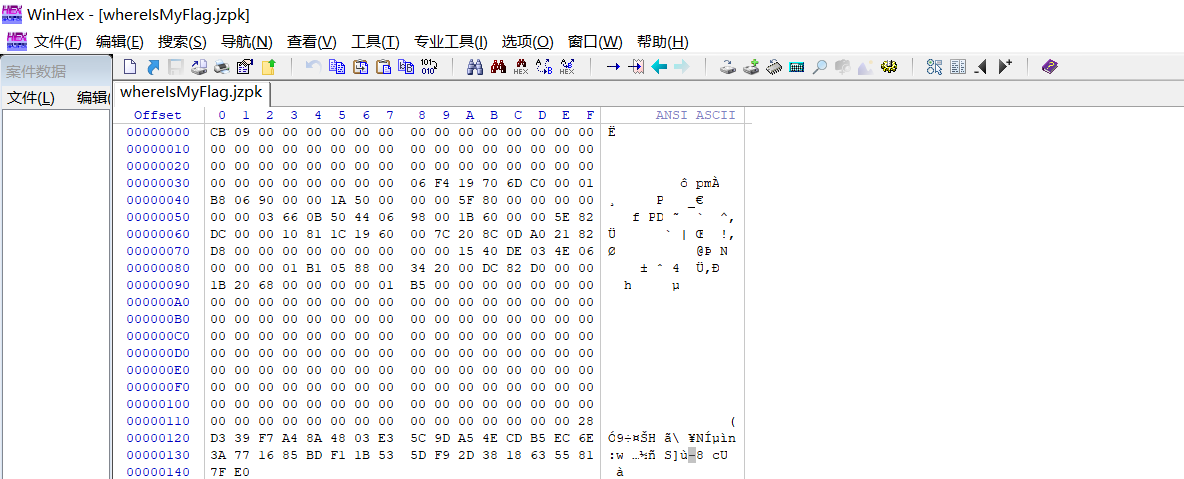
首先根据题目描述,要用 (8byte) 的数据长度读取数据段比特位数,这里要注意用的是小端存储,要以字节为单位从后往前读,可以在观察后直接人工赋值。
然后要把剩下的 (hex) 数据转换成 (01) 串,这个要逐字节操作,考虑到 (hex) 数据是每八位算出来的,除了长度为 (0) 的外,每个字节都要补满 (8bit)(否则无法正确对齐)。
转换之后就可以开始读取哈夫曼字典信息了,对于每个字符先读取 (8bit) 的长度数据,然后根据这个数据再读入指定位数的该字符的压缩信息。
于是问题就只有如何把原字符和压缩后的 (01) 串对应起来,一开始写的是 (C++;STL) 里面的 (map) 映射,在解码的过程中枚举一下压缩后的位数然后对应在映射里找对应的原字符即可。
更加优秀的方法是用一个字典二叉树记录,索引的时候逐位向下找就行了,复杂度是 (O(len))。
大概长这样:
代码如下:
#include <bits/stdc++.h>
using namespace std;
char data[10007];
bool bit[100007];
int len,tot,pos,bits;
map<string,char> m;
inline int ord(int p,int x) { //小端存储
int ret=0,base=pow(2,x-1);
for (int i=0;i<x;i++)
ret+=bit[p+i]*base,base>>=1;
return ret;
}
inline string str(int p,int x) {
string ret="";
for (int i=0;i<x;i++) ret+=(bit[p+i]+'0');
return ret;
}
int main() {
FILE *fin,*fout;
fin=fopen("data.txt","r");
fout=fopen("flag.txt","w");
fscanf(fin,"%s",data);
len=(int)strlen(data),tot=len*8;
//这里开始把提出来的hex数据转换成bit数据
for (int i=0;i<len;i+=2) {
if (data[i]>='A') data[i]=data[i]-'A'+10;
else data[i]-='0';
if (data[i+1]>='A') data[i+1]=data[i+1]-'A'+10;
else data[i+1]-='0';
int num=data[i]*16+data[i+1]; //以byte为单位转换
for (int j=7;j>=0;j--) {
bit[(i*4)+j]=num&1;
num>>=1;
}
}
bits=2507,pos=64; //根据题意计算出数据段长度,并初始化
//下面读取哈夫曼树字典信息
for (int i=0;i<256;i++) {
int ilen=ord(pos,8); pos+=8;
if (!ilen) continue;
string v=str(pos,ilen); pos+=ilen;
m[v]=(char)i;
}
//下面就是解码过程了
while(pos<tot) {
for (int i=8;i>=1;i--) {
string now=str(pos,i);
if (m.count(now)) {
fprintf(fout,"%c",m[now]);
pos+=i; break;
}
}
}
fclose(fin);
fclose(fout);
return 0;
}
优化之后:
#include <bits/stdc++.h>
using namespace std;
char data[10007],tr[10007];
bool bit[100007];
int len,tot,pos,bits;
inline int ord(int p,int x) { //小端存储
int ret=0,base=pow(2,x-1);
for (int i=0;i<x;i++)
ret+=bit[p+i]*base,base>>=1;
return ret;
}
inline string str(int p,int x) {
string ret="";
for (int i=0;i<x;i++) ret+=(bit[p+i]+'0');
return ret;
}
int main() {
FILE *fin,*fout;
fin=fopen("data.txt","r");
fout=fopen("flag.txt","w");
memset(tr,0,sizeof(tr));
fscanf(fin,"%s",data);
len=(int)strlen(data),tot=len*8;
//这里开始把提出来的hex数据转换成bit数据
for (int i=0;i<len;i+=2) {
if (data[i]>='A') data[i]=data[i]-'A'+10;
else data[i]-='0';
if (data[i+1]>='A') data[i+1]=data[i+1]-'A'+10;
else data[i+1]-='0';
int num=data[i]*16+data[i+1]; //以byte为单位转换
for (int j=7;j>=0;j--) {
bit[(i*4)+j]=num&1;
num>>=1;
}
}
bits=2507,pos=64; //根据题意计算出数据段长度,并初始化
//下面读取哈夫曼树字典信息
for (int i=0;i<256;i++) {
int ilen=ord(pos,8),tp=1; pos+=8;
if (!ilen) continue;
string v=str(pos,ilen); pos+=ilen;
//字典树建立新节点
for (int j=0;j<ilen;j++) {
if (v[j]=='0') tp<<=1;
else tp=(tp<<1)+1;
}
tr[tp]=(char)i;
}
//下面就是解码过程了
int tp=1;
while(pos<tot) {
if (bit[pos]) tp=(tp<<1)+1;
else tp<<=1;
if (tr[tp]) fprintf(fout,"%c",tr[tp]),tp=1;
pos++;
}
fclose(fin);
fclose(fout);
return 0;
}

最后得到这个字符串,使用 (Base64) 解码即可得到 (flag)。