近期碰到一个问题,两套系统之间数据同步出了差错,事后才发现的,又不能将业务流程倒退,但是这么多数据手工处理量也太大了,于是决定用Python偷个小懒。
1、首先分析数据。
两边数据库字段的值都是一样,先将这边数据库的数据查询导出,正好是2列120多行的数据。那么目标就是拼接成update from_name set data= where id= 格式,将导出内容中的第1列和第2列内容放到等号=后面即可。

2、下面开始动手。
前提肯定是要有一个python环境的,没有的去下载安装一个也很快。有了环境之后打开编辑器,这里用自带的IDLE或者pycharm都行,代码简单用哪个都不影响。
2.1 打开文件(注意文件存放路径),默认打开为 r 模式,seek(0):从起始位置读取内容。

2.2 读取文件中的数据,得到一个列表,用以for循环

输出f1查看数据格式,可以看出中间的制表符 和换行符

2.3 先将列表内容的换行符 替换为;,再从指标表 位置进行切割,分开为两个字符。
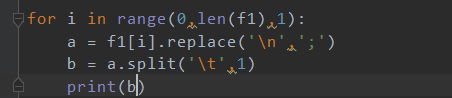
输出结果:

2.4 然后就可以进行拼接了,使用最简单拼接方式,再将所有内容存到一个对象中

2.5 最后将成果封装写入到一个文件当中

检查电脑存放的路径中是否存在最终输出的文件,大功告成,11行代码就完了,简单粗暴又有效。