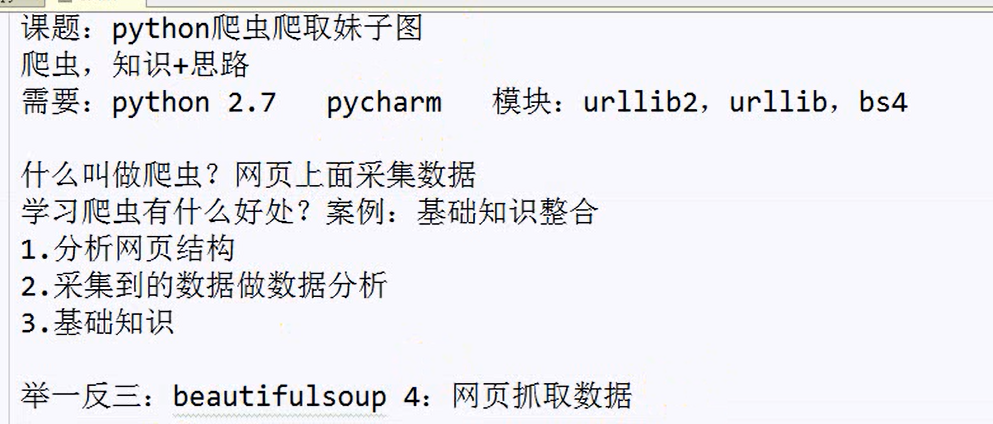


1 #-*- coding:utf-8 -*- 2 import urllib 3 import urllib2 4 from bs4 import beautifulsoup4 #获取标签下的内容 5 #打开网页,获取源码 6 x=0 7 url='http://www.dbmeinv.com/?pager_offset=1' 8 def crawl(url): #取名字,最好见名思义 9 headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'} 10 req=urllib2.Request(url,headers=headers) #浏览器帽子 11 page=urllib2.urlopen(req,timeout=20) #打开网页 12 contents=page.read()#获取源码 13 #print contents 14 #html.parser是自带的解析方式,lxml功能大 15 soup=BeautifulSoup(contents,'html.parser')#创建一个soup对象 16 my_girl=soup.find_all('img')#找到所有的标签 17 print(my_girl) 18 for girl in my_girl:#遍历list,选取属性 19 link=girl.get('src')#获取src图片路径 20 print(link) 21 #下载的文件,取名字 22 global x 23 urllib.urlretrieve(link,'image\%s.jpg'%x) 24 x+=1 25 print 26 27 crawl(url)
以上代码在3.5环境下运行一下代码可以成功爬到各图片链接
1 #-*- coding:utf-8 -*- 2 import urllib.request 3 from bs4 import BeautifulSoup #获取标签下的内容 4 #打开网页,获取源码 5 6 x = 0 7 url = 'http://www.dbmeinv.com/?pager_offset=1' 8 def crawl(url): 9 print('3') 10 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'} 11 print('4') 12 req = urllib.request.Request(url, headers=headers) 13 page = urllib.request.urlopen(req) 14 #req = urllib3.request(url, headers=headers) #浏览器帽子 15 print('5') 16 #page = urllib3.urlopen(req, timeout=20) #打开网页 17 contents = page.read()#获取源码 18 soup = BeautifulSoup(contents,'html.parser')#创建一个soup对象 19 my_girl = soup.find_all('img')#找到所有的标签 20 print(my_girl) 21 for girl in my_girl: 22 link = girl.get('src') 23 print(link) 24 print('1') 25 print('2') 26 crawl(url)