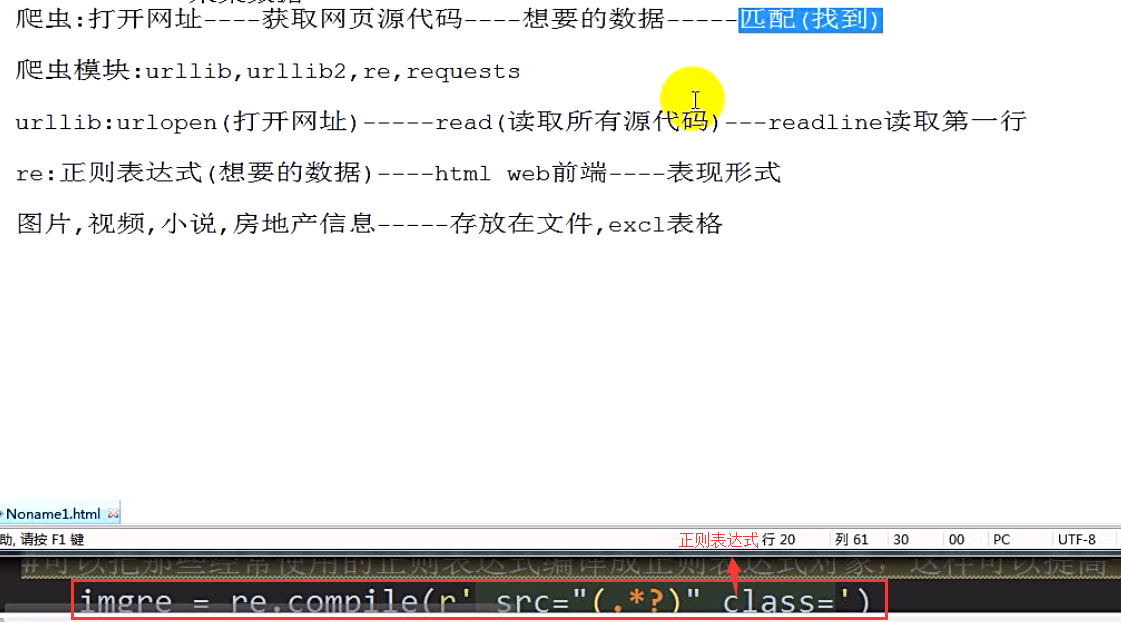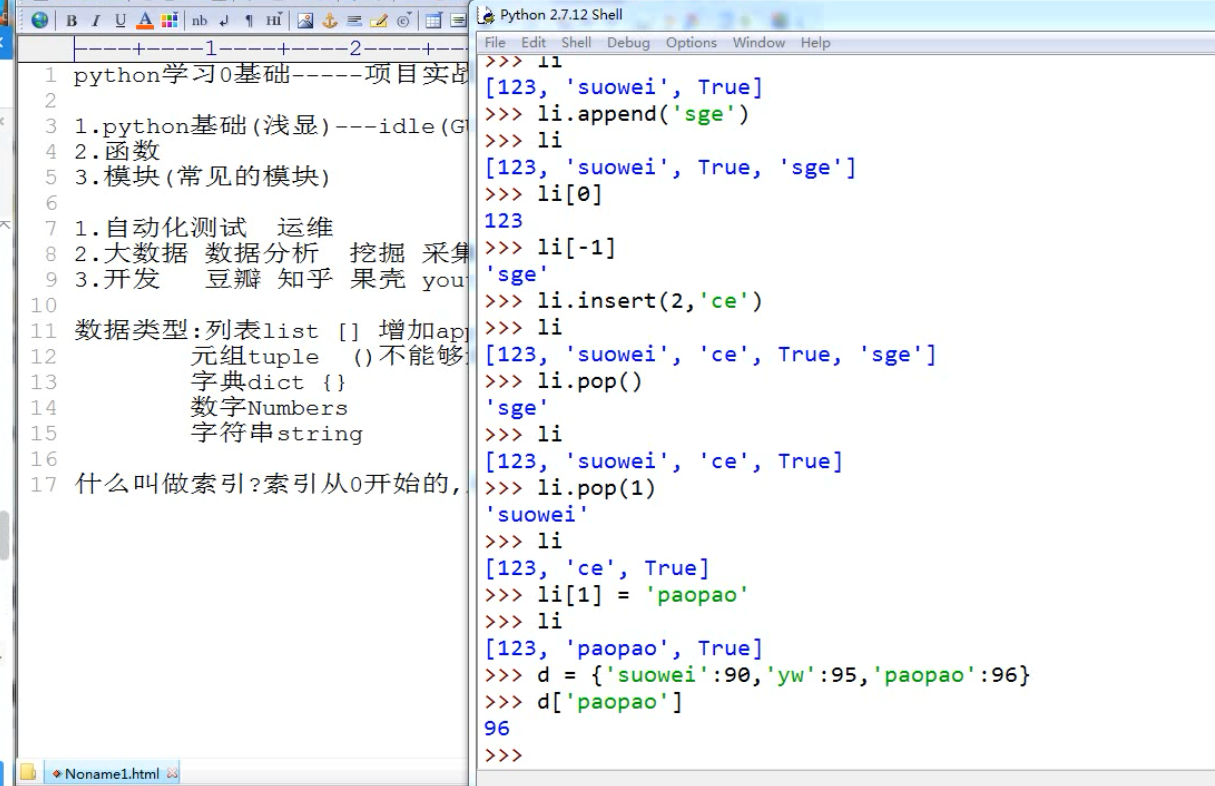
爬虫相关笔记:
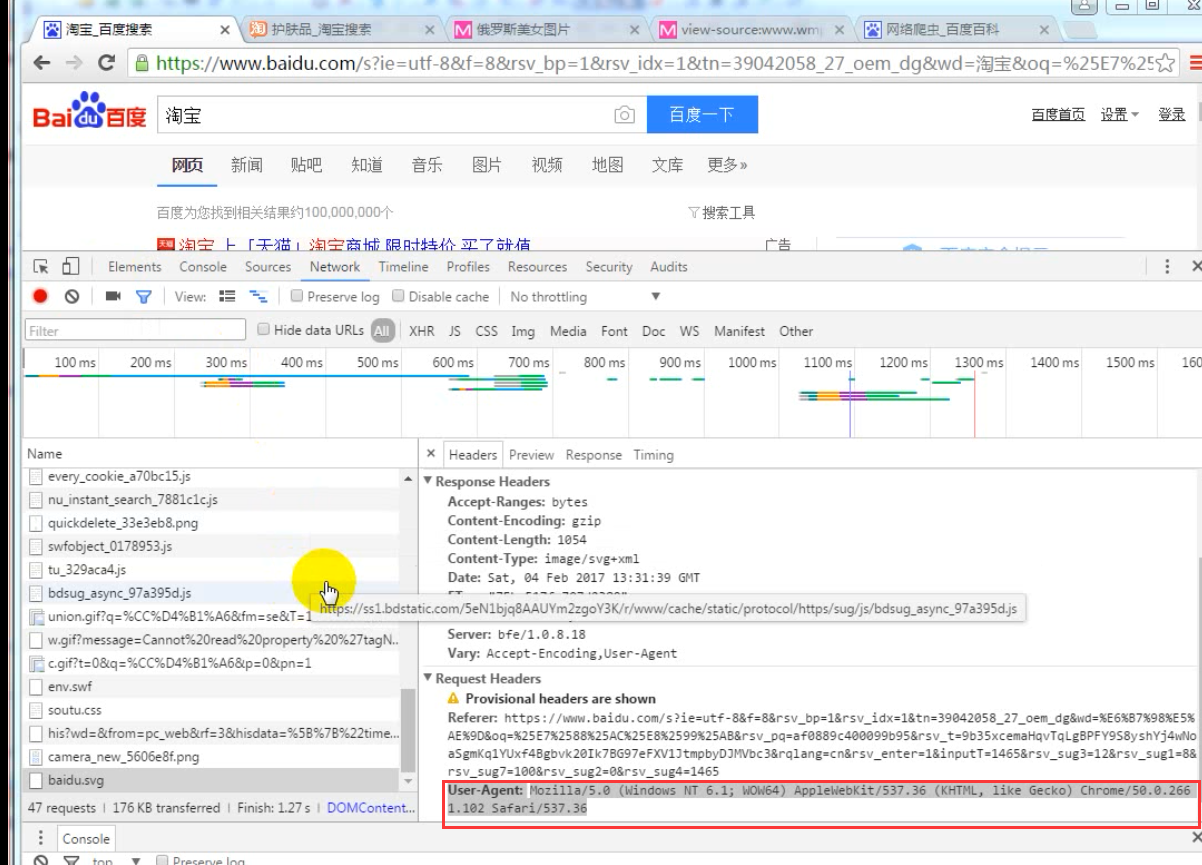
对于反爬虫网站,我们需要获取网站的浏览器信息+头部信息,可见下方截图中的Requests Header头部信息中的红框部分内容,我们后续会应用这里进行反爬虫网站的代码处理。
实际网站调试过程
除了urllib.urlopen外用requests更简单的获取网页源码方法:
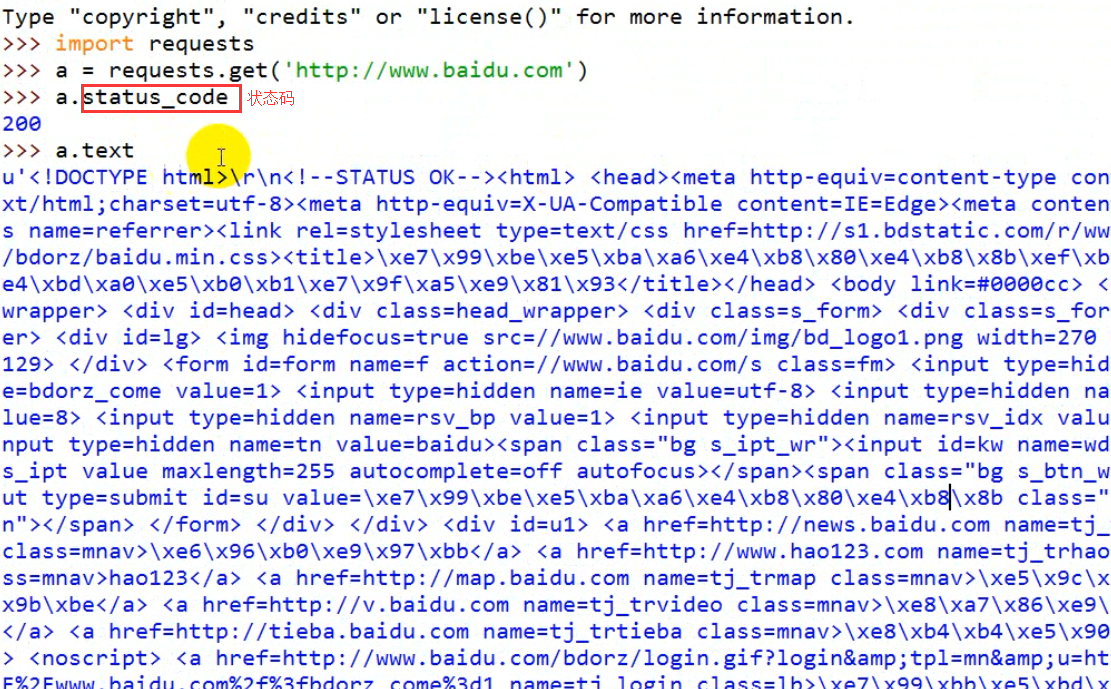
request比urllib更加的简便,使用起来更便捷。知识点记录:
1. a.headers[]//获取头部信息
2. a.text//获取网站的源代码
3. a.content//获取网站的源代码
爬虫部分: