什么是反馈系统?
反馈系统(feedback system)是具有闭环信息通道的系统。
定义: 将系统的后果或输出信息采集、处理,然后送回输入端并据此调整系统行为的系统。由于信息流通构成闭合环路, 它也称为闭环系统。 反馈作用常常用于检测信号偏差以及对象特性的变化,并以此来控制系统行为以及消除误差。 它又被称为反馈控制或者按照误差控制的系统。
为什么需要反馈系统?
- 用户的需要。用户在使用过程中会遇到问题,对于此问题他希望能够有渠道去反馈,主要目的有三。
- 其一: 提出对于产品的一些个人意见,帮助开发者更好地改进产品。
- 其二: 在使用过程中可能遇到产品的某些bug,需要渠道来宣泄自己的情绪。
- 其三: 在使用过程中遇到了某些问题,如找不到入口、登录出错等等,用户需要获得及时的解答。
- 产品开发人员的需要。开发人员尤其是创业团队是更加需要反馈系统的,主要目的有二。
- 其一: 及时了解产品的问题与不足并改进产品,以此来不断地优化产品。
- 其二: 对于用户的问题作出及时的解答,提升产品的用户体验。
反馈系统的类型有哪些?
主要可以分为自建的反馈系统和使用第三方工具作为反馈系统:
- 自建的反馈系统。
- 邮件形式 --- 即用户将反馈信息提交之后通过邮件的形式发送到开发人员,然后开发人员进行邮件形式的回复。
- 对话形式 --- 即用户的反馈会直接显示在页面上, 开发人员的回复、用户的追问等以对话的形式显示出来。
- 工单形式 --- 即用户的反馈会以工单的形式显示, 其处理的过程包括处理中、处理完毕等具体流程会显示出来。
- 需求池形式 --- 即用户的反馈会全部显示出来。 需求池就是对所有需求的集合,但是开发人员需要及时地对需求池进行优化。
- 第三方工具作为反馈系统。
- 微信
- 官方微博
- 微信公众号
具有反馈系统的网站推荐
邮件形式:

如Tower,我们在 https://tower.im/help 的底部可以看到下面的界面:
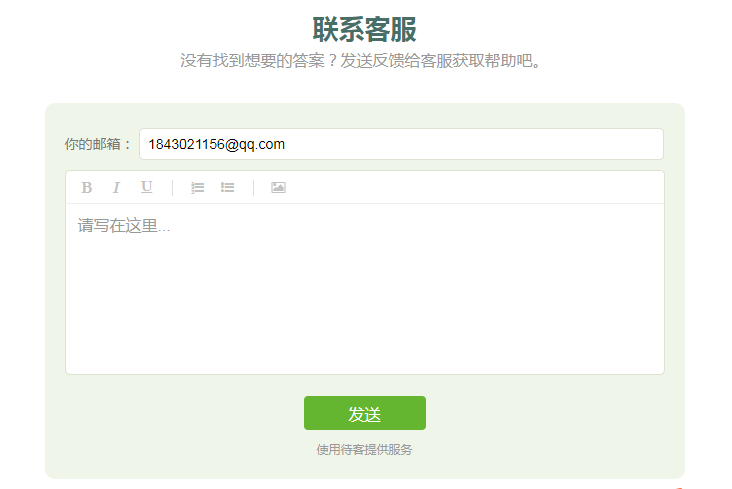
进入帮助页面,如果我们没有找到答案,就可以在底部发现这样的一个反馈系统,邮箱是网站默认填充的, 然后我们可以在内容框中填写文字、图片等, 开发、客服人员收到邮件之后会通过邮件的方式发送给用户。
显然,这种方式是封闭的,只有发问的用户可以收到解决邮件,而其他用户看不到更多用户的问题与回答。
几分钟之后,我就接受到了这样的一封反馈邮件,很好地解决了我的问题, 可以看到,Tower的入口也是非常方便地。
对话形式:

叮当网站就是这种对话形式的反馈,在右下角有一个留言的图片,点击这个图片之后就会进入一个对话的页面,这个页面还可以使用一个新的iframe来显示,如下所示:
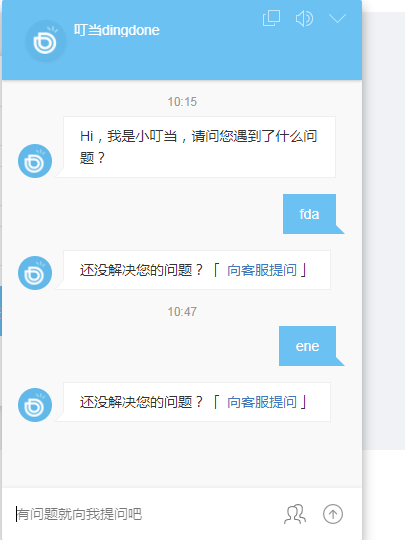
这种方式最大的好处就是直观、方便追问、具有及时性, 但是不太方便跟踪员工处理的进度情况。
工单形式:

在阿里云的网站上,我们可以添加建议并提交,提交之后我们可以看到显示如下:
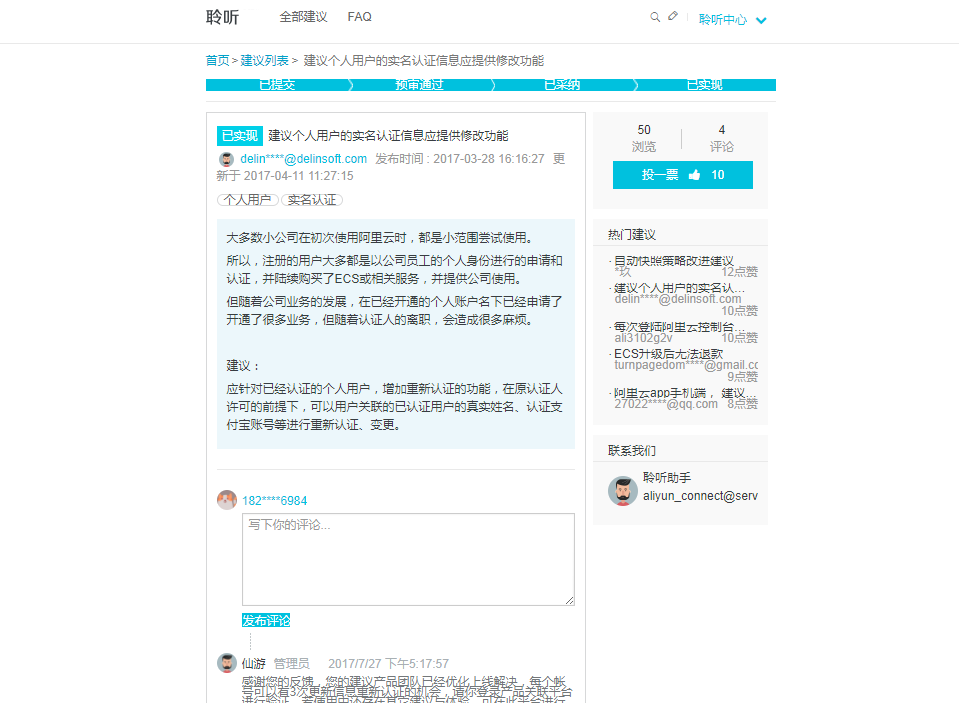
可以看到提交之后,就会形成一个工单,实时的反映当前情况, 即 ‘已提交’、‘预审通过’、‘已采纳’、‘已实现’ 几个步骤。 对于仅仅是提交的建议,我们还可以进行再次编辑,另外,所有的建议其他用户也都是可以看到的,所有人(当然包括管理员)可以进行反馈、评论、投票等功能。
在此网站可以查看:https://connect.aliyun.com/suggestion/5293?spm=5176.8409797.user.1.38c60aa8v2lqt7
需求池形式:

https://www.mockplus.cn/
这是一个做原型的工具,更为高效、简单。
反馈系统基本框架
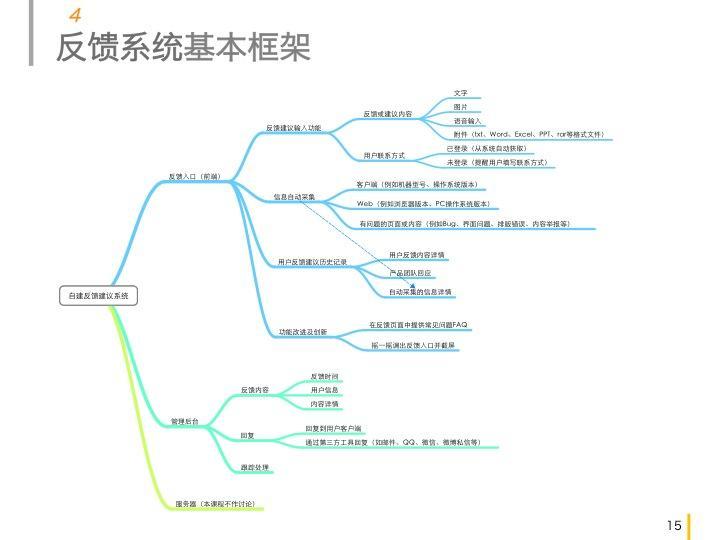
从反馈系统的基本框架来看,此系统在在前端至少需要两个页面(或者说是网站) --- 用户反馈网站 以及 后台管理网站。
前端用户反馈页面
第一部分:
即需要在网站的的主页面或者帮助页面处提供一个入口,由此进入反馈界面,在反馈界面中的需要提供一个表单用于提交反馈,内容如下:
- 表单的字段里需要包括用户的userName等基本信息用作后台记录。
- 选择提交反馈的类型
- 一般问题。如界面UI问题、网站进不了、无法登陆等等问题。
- 产品问题。需要具体制定某个产品,即针对某个产品进行的反馈。如果这个反馈插件只是放在了某一个特定产品的网站上,那么我们就不需要选择产品了,如果反馈插件放在了一个公司(这个公司下有很多产品)网站上,我们就需要让用户选择特定的产品。
- 输入反馈的具体内容。 可以输入文字,也可以输入图片。
输入完成之后提示已提交至后台即可。
另外,在反馈界面,我们还可以列出一些常见的问题和回答,这样,用户也许就不需要去提问了。
第二部分:
当然,除了一个提交反馈的表单还是不够的,还需要一个“我的反馈”界面。
即在第一部分中,我们反馈进行了提交,在“我的反馈”界面就需要展示对于我的所有反馈的详情了。
- 这个反馈的详情是后台管理员进行回复的。
- 用户可以在管理员回复的基础上进行追问 。
既然有我的反馈界面,这也就是说每次你进入这个网站的时候还是需要唯一标识的,那么就需要使用登录和注册功能,这样才能在你下一次登录的时候将你的相关的建议展示出来。
前端后台管理界面
后台管理界面会稍微复杂一些。
- 可以查看所有产品列表。
- 可以创建新的产品。
- 可以查看某产品的反馈列表。
- 可以关注产品。 因为每一个使用后台管理的人可能是不同的,有人是为了关注 maxhub 相关产品,有人是为了关注 seewo 相关的产品。关注之后,当有新的消息时,就会给出后天相应的提示。 没有关注的也是可以看到反馈列表的,只是不会给出提醒。
- 可以查看某个反馈的详情。
- 可以回复单个反馈(采用堆楼模式)。
- 可以操作单个反馈,实现状态的改变(新建、已回复(回复后自动确认)、已关闭(关闭后自动修改))。
- 新建 --- 即一个新的反馈,需要及时的回复。
- 已回复 --- 即对于新的反馈,已经给予了回复。
- 已关闭 --- 即我们看到已经回复完成之后,对方也满意了,就可以关闭这个反馈了,那么我们就不需要再去经常查看了 。 那么此时应该通知客户端已经关闭了反馈、并且不可再回复了吗? 实际上也是可以的,既然已经解决了问题,就可以关闭了。
- 条件搜索。 根据某个条件,搜索到相应的用户问题。
重要: 可以做成推送平台的js插件!
- 在任何地方引入之后,可以在页面上添加入口。
- 点击入口之后展示一个简单的反馈界面,可以提交反馈。
- 考虑js插件的可配置性(入口位置、颜色、文案等等)。
- js插件支持移动端。
做成插件之后,我们就可以在多个产品的主页上使用了。 这种场景往往是用于一家较大的公司,公司旗下有很多的产品,每个产品可能都会单独建站,在每一个网站上,我们可以添加一个特定产品的js插件,而后台管理页面是保持基本不变的。
后台接口
登录、注册、请求反馈界面、请求后台管理界面、添加产品、请求所有产品、请求某个产品下的所有反馈(每条反馈是一个文档,每个文档中包含了反馈的具体信息,题目,信息,评论(评论需要包括评论人、评论时间等),状态、所属用户等等,键值对不是简单的string,设计的有规律一些即可。), 请求某个用户的所有建议(在某个产品下去查找即可,那么保存用户信息时还需要保存用户所使用到的产品类别,这样在搜索产品时会比较快),
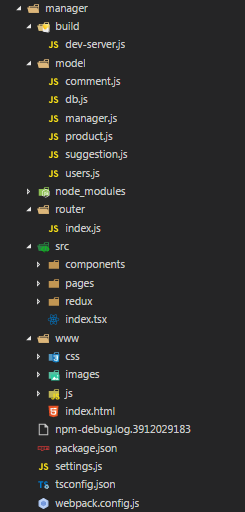
最终的项目架构:
这个项目分成了两个文件来做,一个作为主服务器,另一个作为辅助服务器,那个辅助服务器在发送请求时是代理到主要的服务器上的。前端采用基本的分层方式,后端采用的是MVC的架构方式。
build是服务器相关文件。 model是数据库的相关文件。 node_modules是存放的一些包。 router是存放的路由文件。 src是react的相关文件(src中components存放一些基本的组件,pages存放整个的页面, redux存放的是项目状态管理的相关文件,index.tsx是react项目的渲染页面)。 www是服务器上存放的静态文件。 最后就是基本的 package.json、settings.js(数据库配置)、tsconfig.json(typescript的相关配置文件)、webpack.config.js(webpack相关文件)。
遇到的问题
1、应该建立几个文件,即开启几个服务器(项目)?
第一种方式: 开启一个服务器。
即认为只有一个服务器,在用户点击按钮时,触发一个请求,从后端请求到反馈系统的页面,这样就可以进行简单的操作了。
对于管理员,也可以请求到服务器端的一个管理员的页面。
这样在技术上是可以做到的,但是在前端处理上会出现问题。 比如使用webpack打包的时候,就会把所有的js打包,但是实际上在用户和管理员处所使用的js并不是所有的,这样就会造成浪费。
第二种方式: 开启两个服务器
这样的方式最简单、清楚、明了。
结果: 实际上,我们应该当做两个项目来做,也就是说,需要同时进行两个项目来做,一个项目用于写后天管理系统(较多主要是数据库的处理),另一个项目主要是写前端反馈系统。
2、 这个任务的实际使用场景是这样的吗?
即管理员的界面始终只有一个,而用户反馈界面的界面是会随着不同产品的改变而改变的,会有不同的网站来进行请求。
结果:
- 反馈平台是比较核心的,并且这个可以看做是固定的,由管理员来使用,并且反馈平台管理员端的后台代码也是比较比较重要的,通过其为反馈系统提供API。
3、 使用react、 ant.design可以吗?
结果: 可以尝试使用 ant.design , 因为 ant.design 是蚂蚁的一套前端框架,适合react项目的使用,可能会遇到一些坑,但是还是可以尝试考虑使用的。
4、 这里所说的插件到底是什么?怎么去理解? 可配置是说添加一个配置文件、配置对象吗?
插件实际上就是一段js代码,通过这个js代码,我们可以将这个js插件暴露出来的方法进行 init 然后适用在某个产品上。
5、什么是堆楼模式? 这里所使用的反馈系统是工单形式的吗?
即评论是一层一层的,而不是缩进的形式。 反馈系统可以看作是工单形式的。
6、整体的思路应该是怎样的?
对于后台管理界面是直接使用node作为后台,然后使用react来写前台管理界面,这个是通用的。 另外,这个后台除了提供管理界面之外,也应该提供反馈平台所需要的接口。 另外,还需要一个通用的普通端,这里可以自己选产品的类型等。
7、数据库的设计应该是怎么样的?
在数据库中,我们需要存储的信息包括管理员信息、用户信息、建议信息、评论信息、产品信息等等, 对于这些信息,我们应当尽量采用扁平化的风格进行存储。使用连接的方式。
(1)产品存储
- 产品名称 (name) --- 用于在用户获取到之后在前端显示出来。
- 产品ID (productId) --- 用于唯一的标识产品。
- 产品被创建的时间 (savedTime) --- 存储了时间之后,在显示产品时我们就可以采用产品创建时间的先后顺序来获取,这样就是有序的了。
- 关注该产品的人(relatedPersonId) --- 即如果某用户关注了该产品, 我们就将这个人的ID添加进来,这样用户在获取 我关注的产品 时,就可以通过查询数据库查询到相应的产品。 并且作为管理员,应该不是很多,所以说将关注该产品的管理员加入也是可以的。
- 创建该产品的人 (createdPersonId)--- 只有创建了这个产品的人才能够删除这个产品。
(2)建议存储
- 建议的ID(suggestionId)--- 唯一的标识一条建议。
- 提建议的人(person) --- 用于在展示产品时展示出提建议的人。
- 提建议的人的Id --- 用于创建该建议的用户进行查找。
- 建议创建的时间 (suggestionTime) --- 用于在获取产品时,针对时间进行排序;展示。
- 相关的产品ID(productId) --- 在列举产品的建议时,可以根据建议中的这个字段获取到所有的相关建议。
- 建议的类型(type) --- 在列举某个产品的建议时,我们可以针对功能建议、产品缺陷、产品需求三个方面来分别展示相关的建议。
- 建议内容(content)--- 这个当然是不可少的,因为我们需要展示出来。
- 建议状态(status)--- 用户发出一个建议之后,需要管理员来回复处理,比如已提交、被拒绝、已接纳、实现建议的内容等等。
(3)评论存储
- 此条评论所属的建议的ID(suggestionId),这样,在列举建议的评论时,我们就可以查找所有suggestionId的建议。
- 评论时间(time) --- 进行展示的排序。
- 评论人(person) --- 用于在前台进行展示。
- 评论内容(content) --- 存储评论的内容。
- 评论ID --- 唯一的标识这一条评论。
- 评论类型(type) --- 管理员的type为1、而用户的type为2。
(4)管理员存储
- 管理员名称 ---(用于显示)可以是手机号。
- 管理员Id(id)--- 用于寻找所有的自己关注的产品。
- 管理员类型 --- 如果是1,表示这是一个管理员,如果是2,表示这是一个用户。
- 管理员创建的产品Id(产品Id是在创建的时候分配的) --- 只有创建了这个产品的人才能对这个产品进行操作。
(5)用户存储
- 用户名称 --- 用于显示。
- 用户Id --- 用于查找自己的所有的建议。
- 用户类型 --- 如果是1,表示这是一个管理员,如果是2,表示这是一个用户。
即在数据库中需要建立5个集合,这样我们就可以进行简单的系统操作了。可以看到,上面的数据库的设计尽量是扁平化的,而没有进行扎推。
并且我们应当提高可重用性,不要在不同的表中建立了太多相同的内容,这是不合适的。
8、 ant.design究竟应该怎么用?
我们在使用的时候应该尽可能多地去考虑其源码,这样,我们才能更理解,也能有所学习。
9、 管理系统和用户端对于建议的状态管理应该是怎么样的?
用户端
- 用户提交建议,用户端显示为已提交。
没错,用户的权限很小,用户只能提交之后,看到其答案已经提交了,后续的工作就完全取决于管理员了。
管理端
- 用户提交了建议之后,管理端显示为新建议。
- 这时管理员应该及时的将状态修改为审核中,这样用户就可以直接看到建议的最新状态,接着和团队、小组成员进行讨论建议的可实施性,也许会持续一段事件,并作出及时地回复。
- 讨论结束之后,管理员可以决定审查未通过,但一定要给予用户进行充分的解释,那么这个问题就可以关闭了;或者是决定已采纳。及时的将信息显示在用户端界面。
- 如果是 已采纳,那么管理端就需要及时解决,然后将信息及时通知给客户端 。
所以说,对于建议的管理,主动权完全在管理端,这样才会比较好控制数据,不至于混乱,就像redux的单向数据流的方式是一样的。
10、登录、注册这部分应该怎么做? 管理员、用户、产品、建议的ID怎么设置可以保证没有大的问题? 怎么保证不会重复? 表的设计是否有问题。
1、 对于唯一ID,我们可以使用 uuid (在项目中我们直接 npm install uuid --dev 即可),这个工具可以帮助我们快速解决问题,并且ID是不会重复的。
2、 对于登录、注册的问题,我们可以把这个反馈的网站看做一个黑盒子,然后只需要对之有确定的输入, 就能保证其输出,所以,我们可以将其i作为插件来想, 对于登录、注册的事情由不同的网站来解决即可。 而我们需要做的就是在后台处理好即可。 而在管理端还是比较容易理解的,就是必须登录注册才能查看产品等等。
11、 uuid介绍。
参考文章: https://www.npmjs.com/package/uuid
http://www.jianshu.com/p/d553318498ad
UUID是128位的全局唯一标识符,通常由32字节的字符串表示。它可以保证时间和空间的唯一性,也称为GUID,全称为:UUID ―― Universally Unique IDentifier,Python 中叫 UUID。
12、 如何实现代理服务器呢?
很简单,我们打开了两个项目,但是我们只希望在一个项目的服务器上处理各种服务器、数据库的数据, 这样,我们直接将次服务器直接代理到主要的服务器即可。如下所示:
第一步:
npm install http-proxy-middleware --save-dev
第二步:
在dev-server.js中,需要引入 http-proxy-middleware,然后:
var proxyTable = { '/api': { target: 'http://127.0.0.1:8000/', // 本地node服务器 changeOrigin: true, pathRewrite: { '^/api': '/' } } };
上面就是我们的基本设置,当然,在proxyTable中可以代理多个服务器,但这里我们只需要一个。 思路就是对api代理,然后发出的时候再重写。
// proxy api requests Object.keys(proxyTable).forEach(function (context) { var options = proxyTable[context] if (typeof options === 'string') { options = { target: options } } app.use(proxyMiddleware(options.filter || context, options)) })
ok! 就是这么简单了,这样就可以完成服务器的代理了。
下面我们就可以发出一个请求了:
componentWillMount () { fetch("/api/getAllProduct", { method: "GET" }).then(function(res) { console.log('进入'); return res.json(); }).then(function (data) { console.log(data); if (data.code == 200) { console.log('获取到所有产品' ,data.data); } else { console.log(data.message); } }) }
即: 这里我们在 localhost: 3000 的服务器下发出了指向 localhost:8000 服务器的资源。
13、多次看到服务器崩溃! 为什么呢?

即如上所示,乍一看似乎并没有什么解决的办法,都是不知道的文件,但是,如果我们仔细看,还是可以发现导致问题的地方的, 比如这里我们可以看到 router 下的 index.js 问题, 接着锁定 product.js 的问题, 再去追究,可以发现,我们在出错的时候,没有及时关闭mongodb数据库,这样,就会报错,修复了这个问题之后,就可以正常获取数据了。
14、在使用redux的过程中,遇到了一个问题。 即在一个问题列表页,点击每一条连接之后,可以进入这个列表的详情页,那么如何在详情页获取到数据呢? 目前的方法是这样的, 即在列表页的Link进行路由跳转的时候,将这条列表的suggestionId传递到详情页中去,然后在 componentWillMount() 这个钩子函数中使用下面的方法:
componentWillMount () { const suggestionId = this.props.location.query.suggestionId; this.props.filterSug(suggestionId); console.log(suggestionId); }
即获取到当前的 suggestionId, 然后通过一个 action 筛选 store 中的这条建议。
function handleSuggestions (state = {allSuggestions: [], filteredSug: []}, action) { switch (action.type) { case 'ADD_ALL_SUGGESTIONS': const newSug = Object.assign([], action.data); return { allSuggestions: newSug } case 'FILTER_SUGGESTION': return { allSuggestions: state.allSuggestions, filteredSug: state.allSuggestions.filter(function (item, index) { return item.suggestionId == action.id; }) } default: return state; } }
接着,我们在再从store中获取这条建议。如下:
function mapDispatchToProps (dispatch) { return { filterSug: (id) => dispatch( filterSuggestion(id) ) } } function mapStateToProps (state) { return { filteredSug: state.handleSuggestions.filteredSug } }
接着,我们就可以在render函数中使用这个 prop 了,即:
const {filteredSug} = this.props;
但是这样导致的一个问题就是: 通过 filteredSug.map 调用时,发现会报错,即 无法读取 map 所在的值,他是 undefined 的。
而如果我们使用下面的方法:
const {filteredSug = [] } = this.props;
即使用es6中的默认值的方法,这样就不会报错了,并且可以正常显示这条建议。 这是为什么? 我之前的想法是: 因为在 store 中存储时,就会有一个默认值,所以,就算是直接获取应该也是一个空的数组,而不是undefined啊,为什么这里还需要提供一个默认值呢?
首先可以确定的是,在store中的state发生变化的时候,就会及时的通过页面进行最新的渲染,这样页面就会及时的变化,即最开始 filteredSug 是 [], 然后当reducer处理完了 action 之后,就会改变state,这样 filteredSug 就成了有一个对象元素的数组了,这样我们就可以进行map了。
之所以页面会随着数据发生变化,是因为页面对数据有了一个订阅,来监听变化。getState函数可以获取当前的state。
下面,我们需要测试的就是在 const {} = this.props;和后面的 mapStateToProps 获取的速度问题(即谁先谁后),测试如下:
在 componentWillMount中添加下面的语句:
console.log('在componentWillMount中的时间', new Date().getTime());
在render函数下添加下面的语句:
const {filteredSug} = this.props; console.log('render函数时间', new Date().getTime());
在 mapStateToProps中添加下面的语句:
function mapStateToProps (state) { console.log('获取store中的state的时间', new Date().getTime(), state); return { filteredSug: state.handleSuggestions.filteredSug } }
然后,我们开始测试,加载这个页面,结果如下:
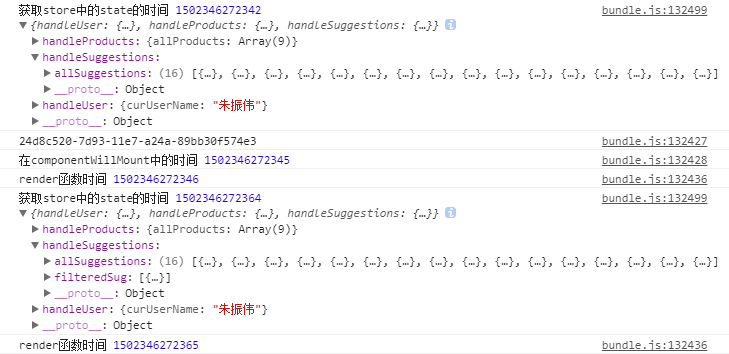
这里的整体思路非常简单,就是首先进入页面,然后第一步就获取到当前的state, 这样的好处在于,第一步获取到之后就可以在后面的各个钩子函数、render函数中使用了,但是我们可以发现一个问题,就是在handleSuggestions这个reducer里只有allSuggestions但是并没有filteredSug。 第二步进入了componentWillMount钩子函数中,这样就可以直接出发filter我们想要的suggestion的action了。 第三步就是开始render。 由于在第一步的过程中就没有获取到filterSug,所以在render的时候,就可以发现map的是一个undefined值。 第四步就比较有意思了,就是在我们之前触发了一个action,所以又在render之后,重新接收到了新的store,这样,就又会重新渲染出来新的render。 我们可以发现,这个 fiterdSug 是存在的,但是之前如果没有赋默认值,那么就在前面报错了,也就没有后面的步骤了。
问题原因:
其实现在就比较好理解了,问题就是处在 reducer 那里,我们在获取到所有的建议的时候,并没有把当前 state 的所有值返回到一个新的state了,所以就导致了在进入 detail 页面的时候,接收不到 filteredSug,解决问题的方式很简单,如下:
function handleSuggestions (state = {allSuggestions: [], filteredSug: []}, action) { switch (action.type) { case 'ADD_ALL_SUGGESTIONS': const newSug = Object.assign([], action.data); return { allSuggestions: newSug, filteredSug: [] } case 'FILTER_SUGGESTION': return { allSuggestions: state.allSuggestions, filteredSug: state.allSuggestions.filter(function (item, index) { return item.suggestionId == action.id; }) } default: return state; } }
这样,我们就可以在render中使用filterSug的时候不需要使用默认值,然后就map了,因为开始map的时候,什么都没有,所以就不会渲染,然后store接收到action之后,触发了新的state,这样就可以使得我们的filterSug成为了一个新的值,页面就会渲染出来了。
那么 connect 的这个源码是怎样的呢? 为什么在进入页面的时候,可以保证在 componentWillMount 钩子函数之前就可以已经获取到了 store 中的state呢?
猜想一: 由于在react中的组件里,constrctor钩子函数式最早被调用的,所以这里获取store的步骤可能是在 constructor 时调用的。 因为connect是react-redux的方法, 而react-redux是另外一个库,所以只能利用react的现有的api。
测试验证
方法: 在constructor钩子函数中打印一下时间,再在 connect 的相关函数中打印一下时间, 如果说 connect 中的时间在后,那么就是对的。
 这个结果很意外,为什么可以首先获得 state 呢? 不是应该首先获得conscructor的吗? 然后利用这个钩子函数获取到state?
这个结果很意外,为什么可以首先获得 state 呢? 不是应该首先获得conscructor的吗? 然后利用这个钩子函数获取到state?
猜想二: 既然state是最先获取到的, 那么就是说它在原来的组件的基础上包装了一层。
这个确实很简单了,在最开始学习redux的过程中,就已经学习到了下面的概念:组件包括UI组件和容器组件,前者的作用完全是用于展示的, 而容器组件的作用就是使用状态管理工具如redux来命名的,即在使用redux时,就需要先将所有的数据以props的形式传递到各个容器组件中(实际上并不是这样的,在react中,有一个context的概念,就是传递数据,不需要使用props层层传递,而只需要使用一个 context 就可以以最快的速度把想要传递的数据给到各个子组件中了), 然后容器组件再将之作为props传递给UI组件, 并且我们在使用redux时,无论是发送dispatch,还是接受store中的数据,都需要通过这一层。
到这里这个问题就很清楚了,就是首先,connect的容器组件首先将获取到的数据传进来放在props中,然后再开始创建内部的UI组件,然后内部需要相应的props时,直接从这个中间层来获取就可以了。所以constructor的创造时间是晚于state传递进来的时间的。