咱们目前已经学习到的容器型数据类型只有list,那么list够用?他有什么缺点呢?
- 1. 列表可以存储大量的数据类型,但是如果数据量大的话,他的查询速度比较慢。
- 2. 列表只能按照顺序存储,数据与数据之间关联性不强。
- 3.列表在表达结构化数据时语义不明确,结构化数据是指有明确属性,明确表示规则的数据。
所以针对于上的缺点,所以需要引入另一种容器型的数据类型,解决上面的问题,就是dict字典。
- 不可变(可哈希)的数据类型:int,str,bool,tuple。
- 可变(不可哈希)的数据类型:list,dict,set。
- 在Python3.5版本(包括此版本)之前,字典是无序的。
- 在Python3.6版本之后,字典会按照初建字典时的顺序排列(即第一次插入数据的顺序排序)。
当然,字典也有缺点:他的缺点就是内存消耗巨大。
1.1创建字典
1.1.1使用{}
dict1 = {} # 空的字典 print(type(dict1)) dict2 = {'name': '王峰', 'sex': "男", 'hiredate': '1997-10-20', 'grade': 'A', 'job': '销售', 'salary': 1000, 'welfare': 100 } print(dict2)
1.1.2利用dict函数创建字典
dict3 = dict(name='王峰', sex='男', hiredate='1997-10-20') print(dict3) # {'name': '王峰', 'sex': '男', 'hiredate': '1997-10-20'} dict4 = dict.fromkeys(['name', 'sex', 'hiredate', 'grade'], 'N/A') print(dict4) # {'name': 'N/A', 'sex': 'N/A', 'hiredate': 'N/A', 'grade': 'N/A'}
注:字典由多个键及对应的值组成,键和值使用冒号分割,字典中键的值必须唯一,而值不需要,另外,字典中的键必须是不可变的,如:字符串,元组和数字。
1.2字典取值
employee = {'name': '王峰', 'sex': "男",
'hiredate': '1997-10-20', 'grade': 'A',
'job': '销售', 'salary': 1000,
'welfare': 100
}
# 字典的取值
name = employee['name'] # 如果查找的key不存在,会直接报错
print(name)
salary = employee['salary']
print(salary)
print(employee.get('job')) # 使用字典的get方法,如果key不存在,会默认返回None,而不报错
print(employee.get('dept' , '其他部门')) # 如果根据key获取不到value,使用给定的默认值
1.3in 成员运算符
employee = {'name': '王峰', 'sex': "男",
'hiredate': '1997-10-20', 'grade': 'A',
'job': '销售', 'salary': 1000,
'welfare': 100
}
print('name'in employee) # in运算符,如果直接用在字典上,是用来判断key是否存在,而不是value
print('dept' not in employee)
1.4遍历字典
# 第一种遍历方式:直接for...in循环字典 for key in employee: v = employee[key] print(v) # 第二种方式 for k,v in employee.items(): print(k,v)
1.5字典的更新和新增
employee = {'name': '王峰',
'sex': "男",
'hiredate': '1997-10-20',
'grade': 'A',
'job': '销售',
'salary': 1000,
'welfare': 100
}
print(employee)
#单个kv进行更新
employee['grade'] = 'B'
print(employee)
#对多个kv进行更新
employee.update(salary = 1200, welfare=150)
print(employee)
# 字典的新增操作与更新操作完全相同,秉承有则更新,无则新增的原则
employee['dept'] = '研发部'
print(employee)
employee['dept'] = '市场部'
print(employee)
employee.update(weight=80,dept='财务部') # 合并两个字典,字典不支持+
print(employee)
1.6删除字典
删除字典可以删除对应的键值对,也可以删除整个字典。
employee = {'name': '王峰', 'sex': "男",
'hiredate': '1997-10-20', 'grade': 'A',
'job': '销售', 'salary': 1000,
'welfare': 100
}
# 1. pop 删除指定的kv,执行结果是被删除的value
employee.pop('weight')
print(employee)
# 2.popitem 删除最后一个kv,结果是被删除的这个元素组成的键值对
kv = employee.popitem()
kv = employee.popitem()
print(kv)
print(employee)
# 3. clear 清空字典
employee.clear()
print(employee)
1.7为字典设置默认值
emp1 = {'name':'Jacky' , 'grade' : 'B'}
emp2 = {'name':'Lily' , 'grade' : 'A'}
# 1. setdefault为字典设置默认值,如果某个key已存在则忽略,如果不存在则设置
emp1.setdefault('grade' , 'C')
emp2.setdefault('grade' , 'C')
#if 'grade' not in emp2:
# emp2['grade'] = 'C'
print(emp2)
1.8字典的视图
emp1 = {'name':'Jacky' , 'grade' : 'B'}
emp2 = {'name':'Lily' , 'grade' : 'A'}
ks = emp1.keys()
print(ks)
print(type(ks))
# (2) values 代表获取所有的值
vs = emp1.values()
print(vs)
print(type(vs))
# (3) items 代表获取所有的键值对
its = emp1.items()
print(its)
print(type(its))
emp1['hiredate'] = '1984-05-30'
print(ks)
print(vs)
print(its)
1.9利用字典格式化字符串
# 老版本的字符串格式化 emp_str = "姓名:%(name)s,评级:%(grade)s,入职时间:%(hiredate)s" %emp1 print(emp_str) # 新版本的字符串格式化 emp_str1 = "姓名:{name},评级:{grade},入职时间:{hiredate}".format_map(emp1) print(emp_str1)
1.10字典推导式
dict1 = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
dict2 = {}
for k, v in dict1.items():
dict2[v] = k
# dict1 = dict2
# print(dict1)
dict1 = {v: k for k, v in dict1.items()}
print(dict1) # {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
1.10散列值(Hash)
字典也称为“哈希(Hash)”,对应“散列值”,是从任何一种数据中创建数字“指纹”,Python中提供了hash()生成散列值。
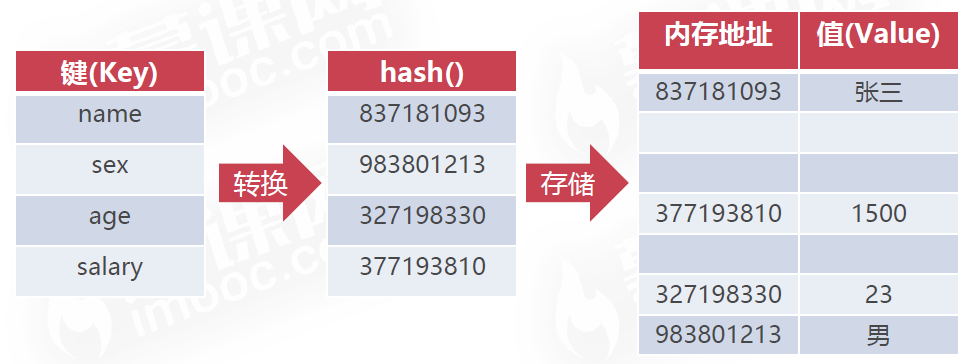
# 散列值 hash() h1 = hash("abc") print(h1) h2 = hash("bcd") print(h2) h3 = hash(8838183) print(h3) h4 = hash("abc") h5 = hash("def") print(h4) print(h5)
1.11字典在项目中的应用
# 处理员工数据 source = "7782,CLARK,MANAGER,SALES,5000$7934,MILLER,SALESMAN,SALES,3000$7369,SMITH,ANALYST,RESEARCH,2000" employee_list = source.split("$") print(employee_list) # 保存所有解析后的员工信息,key是员工编号,value则是包含完整员工信息的字典 all_emp = {} for i in range(0,len(employee_list)): #print(i) e = employee_list[i].split(",") print(e) # 创建员工字典 employee = {"no" : e[0],'name':e[1],'job':e[2],'department':e[3],'salary':e[4]} print(employee) all_emp[employee['no']] = employee print(all_emp) empno = input("请输入员工编号:") emp = all_emp.get(empno) if empno in all_emp: print("工号:{no},姓名:{name},岗位:{job},部门:{department},工资:{salary}".format_map(emp)) else: print("员工信息不存在")
1.12字典的其他说明
a)字典和列表的区别
- 字典的特点:查找和插入的速度非常快,但是需要占用大量内存,内存浪费较多。
- 列表的特点:查找和插入的速度随着元素的增加而减慢,占用空间小。