作业要求参见 https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
本次作业代码地址:https://git.coding.net/zsy1996/text.git代码为wf.py文件
1.根据ASCII码表来去掉特殊字符,比如,。!“”等
定义词频字典
循环判定每个单词的频率
根据字典的value每个单词词频排序
def getFrequency(testtext): testtext = re.sub('[^a-zA-Z0-9n]', ' ', testtext) #根据ASCII码表去掉特殊字符,比如,。!“”等 frequency = {} #定义词频字典 for word in testtext.split(): #循环判定每个单词频率 if word in frequency: frequency[word] += 1 else: frequency[word] = 1 frequency = sorted(frequency.items(),key = lambda x:x[1],reverse = True)
2.全文共有___个不重复的单词,以及每个单词出现的次数
根据文本的词汇量总数来判定显示多少个数据
print('全文共有',len(frequency),'个不重复的单词') if (len(frequency) > 100): for x in range(0,10): a = frequency[x][0] b = frequency[x][1] print('单词',a,'出现的次数为',b) else: for x in range(0,len(frequency)): a = frequency[x][0] b = frequency[x][1] print('单词',a,'出现的次数为',b)
3.输出单一文本
def inputfc(inputtxt): with open(inputtxt,encoding = 'UTF-8') as wf: getFrequency(wf.read())
4.输入文件夹统计文件夹内文本函数
def inputfilefc(self): name_delete = '([sS]*?).txt' txtlist = [] txtlist = os.listdir(inputfile) for i in range(0,len(txtlist)): a = re.findall(name_delete, txtlist[i]) print(a) inputfc(txtlist[i])
功能实现
- 测试文本,无重难点
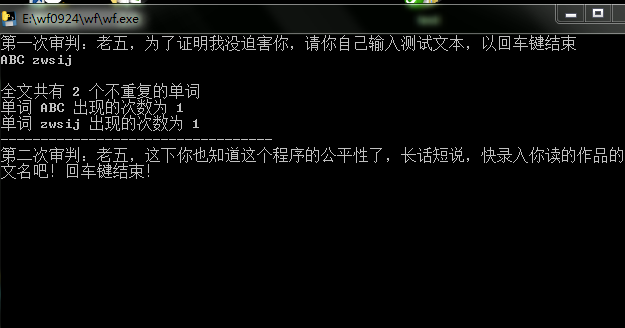
代码
for word in testtext.split(): #循环判定每个单词频率 if word in frequency: frequency[word] += 1 else: frequency[word] = 1 frequency = sorted(frequency.items(),key = lambda x:x[1],reverse = True) #根据字典的value(每个单词词频)排序 print('') #为了好看 print('全文共有',len(frequency),'个不重复的单词')
2.重点是文件名后面一定要输入.txt
def(定义函数)inputfc输入文本到python中

输入文本地址
inputtxt = input() #输入文本地址 inputfc(inputtxt)
def(定义函数)inputfc输入文本到python中
def inputfc(inputtxt): with open(inputtxt,encoding = 'UTF-8') as wf: getFrequency(wf.read())
3.输入文件夹,对文件夹内的所有文本进行词频统计
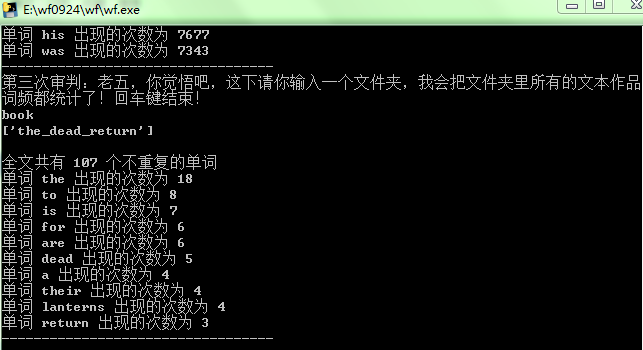

重点:导入文本
def inputfilefc(self)
txtlist = os.listdir(inputfile)导入文件夹
def inputfilefc(self): name_delete = '([sS]*?).txt' txtlist = [] txtlist = os.listdir(inputfile) for i in range(0,len(txtlist)): a = re.findall(name_delete, txtlist[i]) print(a) inputfc(txtlist[i])
统计结果
4.
重点:command = input()键盘输入指令
将数据导入CSV文档中
command = 1 while command: print("输入1导入文档,输入其他退出程序,回车键确认!") command = input() if command == '1': print("请输入导入的文档地址,回车键确认!") inputcommand = input() with open(inputcommand,encoding = 'UTF-8') as wf: outtxt = wf.read() with open("1.csv","w", newline='') as csvfile: writer = csv.writer(csvfile) writer.writerow(["单词","词频"]) outtxt = re.sub('[^a-zA-Z0-9n]', ' ', outtxt) #根据ASCII码表去掉特殊字符,比如,。!“”等 frequency = {} #定义词频字典

PSP阶段
